




 本文介绍如何使用Python爬虫采集短视频。通过分析网页瀑布流加载模式,利用selenium模拟滑动,抓取视频跳转链接,再通过requests请求获取视频源地址,实现视频下载。同时讨论了DY签名加密的处理策略。
本文介绍如何使用Python爬虫采集短视频。通过分析网页瀑布流加载模式,利用selenium模拟滑动,抓取视频跳转链接,再通过requests请求获取视频源地址,实现视频下载。同时讨论了DY签名加密的处理策略。
目录
前言
大家好,我叫善念,这是我的第三篇技术博文。音乐、小说、这次是视频,估计下次就是图片吧。
文章都是当天现写得,自己也没有去做过。
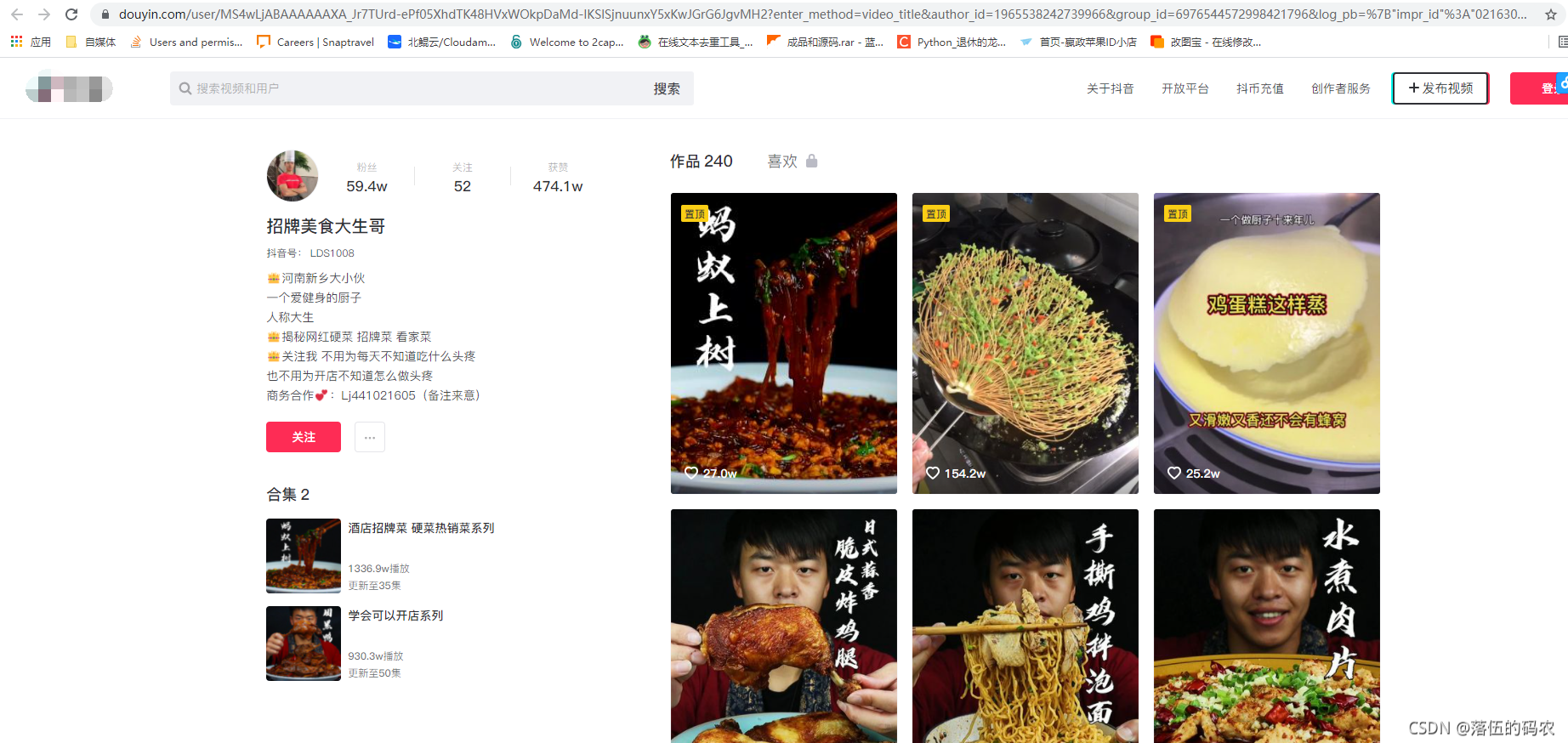
我们将要采集的网站是网页版的DY数据:目标网址
咱们随便选择一个博主的视频进行采集,我饿了我就找了个美食博主。
分析(x0)
在网页的元素中咱们可以找到当前视频的跳转链接:
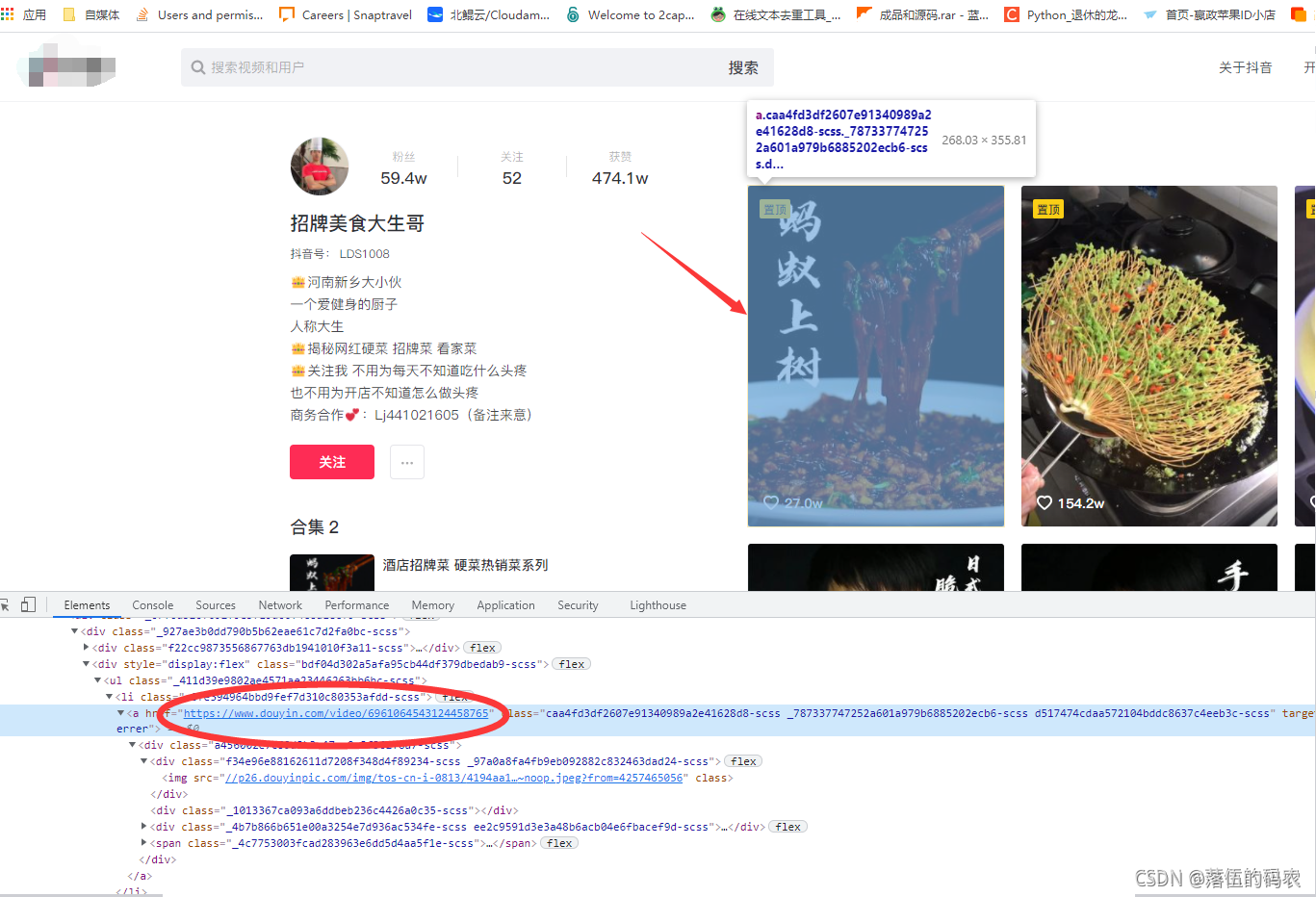
而经过我观察了一下我发现每个li标签都包含了一条短视频的信息: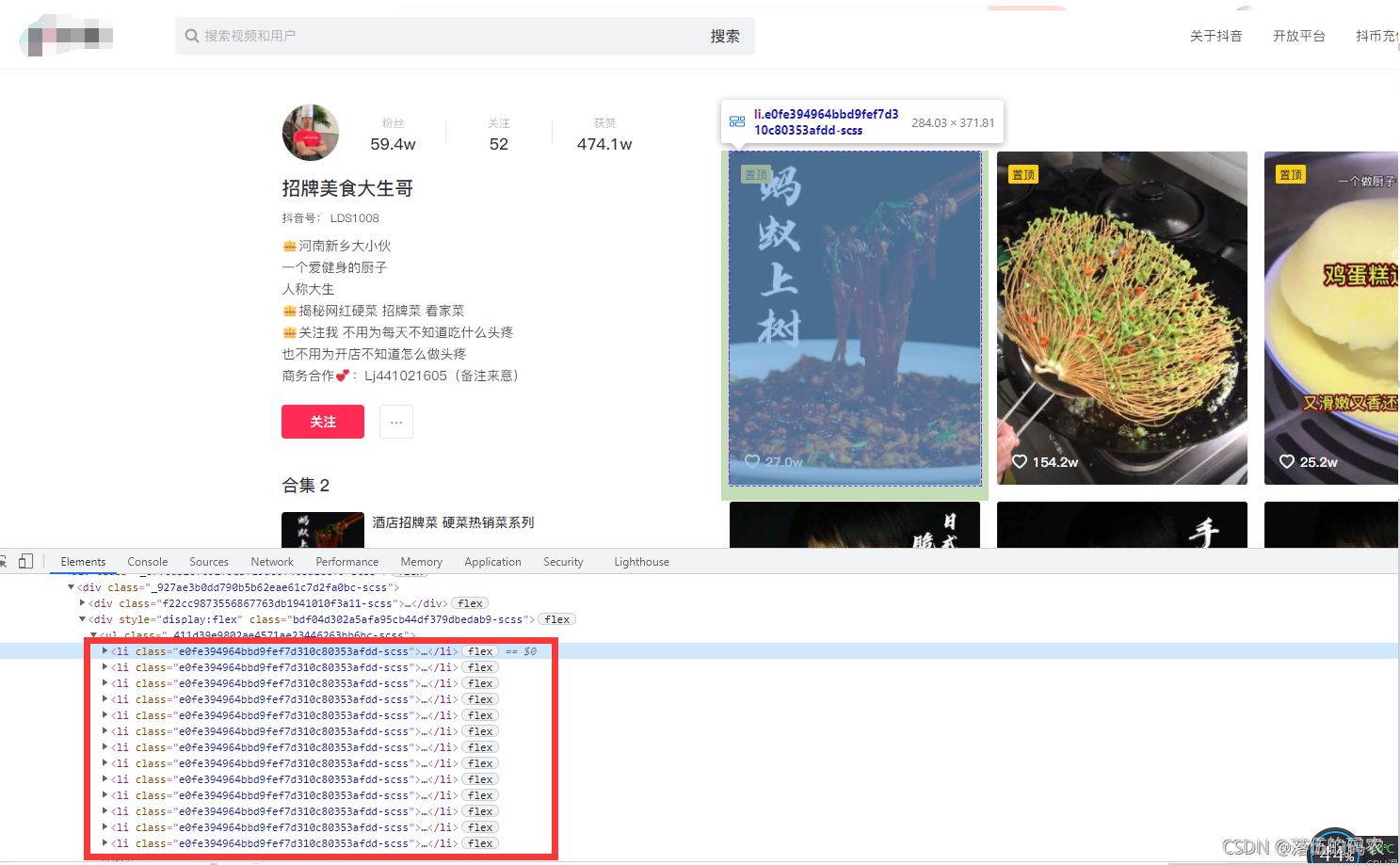
那么这里总共是13个li标签,而咱们的这个博主肯定不止发了13个视频吧?又不是我善念这种货色只有几十个粉丝,所以问题出在哪?
我已经猜到这个是一种瀑布流的模式加载视频了,跟大家解释一下。就是比如说一个网页上面你只能看到十条数据,当你拉动网页下滑条后它会自动加载一些新的数据出来。像瀑布一样数据流出来,原理很简单,就是你拉动下滑条的时候会触发JavaScript脚本生成一些新数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1324
1324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









