 Python反反爬实战:汽车之家字体反爬解密
Python反反爬实战:汽车之家字体反爬解密





 本文介绍了如何应对汽车之家网站的字体反爬策略,通过解析HTML源码、提取关键信息、解密混淆数据以及使用Selenium进行替换操作,成功爬取并还原汽车参数配置。详细讲解了整个过程,包括找到CSS3关键数据、使用正则表达式匹配、JS源码分析及数据替换,最终实现数据入库。
本文介绍了如何应对汽车之家网站的字体反爬策略,通过解析HTML源码、提取关键信息、解密混淆数据以及使用Selenium进行替换操作,成功爬取并还原汽车参数配置。详细讲解了整个过程,包括找到CSS3关键数据、使用正则表达式匹配、JS源码分析及数据替换,最终实现数据入库。
说说这个网站
汽车之家,反爬神一般的存在,字体反爬的鼻祖网站,这个网站的开发团队,一定擅长前端吧,2019年4月19日开始写这篇博客,不保证这个代码可以存活到月底,希望后来爬虫coder,继续和汽车之间对抗。
优快云上关于汽车之家的反爬文章千千万万了,但是爬虫就是这点有意思,这一刻写完,下一刻还能不能用就不知道了,所以可以一直不断有人写下去。希望今天的博客能帮你学会一个反爬技巧。
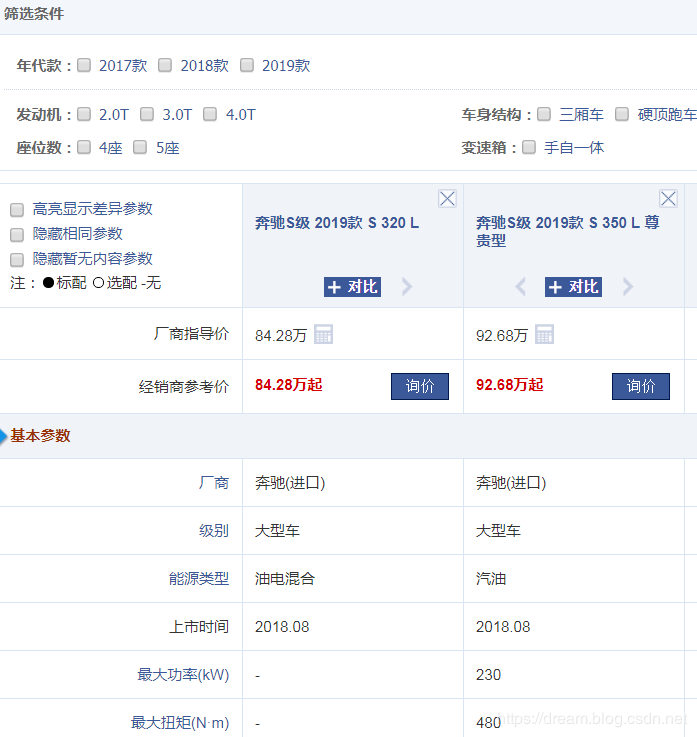
今天要爬去的网页

car.autohome.com.cn/config/seri… 我们要做的就是爬取汽车参数配置
具体的数据如下
查看页面源代码发现,一个好玩的事情,源代码中使用了大量的CSS3的语法 下图,我标注的部分就是关键的一些数据了,大概在600行之后。
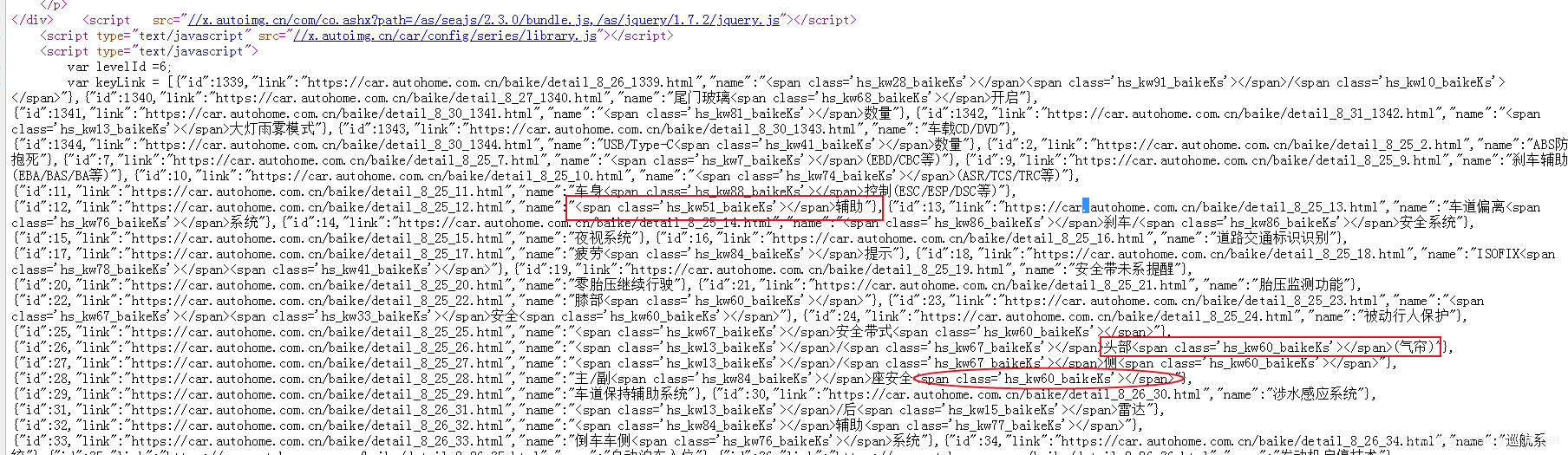
反爬措施展示
源文件数据
刹车/<span class='hs_kw86_baikeIl'></span>安全系统
复制代码页面显示数据
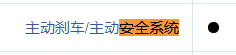
一些关键数据被处理过了。
爬取关键信息
我们要把源代码中的关键信息先获取到,即使他数据是存在反爬的。获取数据是非常简单的。通过request模块即可
def get_html():
url = "https://car.autohome.com.cn/config/series/59.html#pvareaid=3454437"
headers = {
"User-agent": "你的浏览器UA"
}
with requests.get(url=url, headers=headers, timeout=3) as res:
html = res.content.decode("utf-8")
return html
复制代码找关键因素
在html页面中找到关键点:
- var config
- var levelId
- var keyLink
- var bag</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+








 到【灌水乐园】发言
到【灌水乐园】发言







