



读到了一篇来自HuggingFace[1] 很不错的LLM eval 科普教程,信息量很大,从PaperCache[2] 搬运了过来又完善了一些细节,分享给大家。
1. 概述
本文是一本详尽的LLM(大型语言模型)评估指南,旨在帮助研究人员、工程师和模型使用者理解LLM评估的复杂性。其核心目标是解答“如何判断一个模型是否优秀?”这一根本问题。
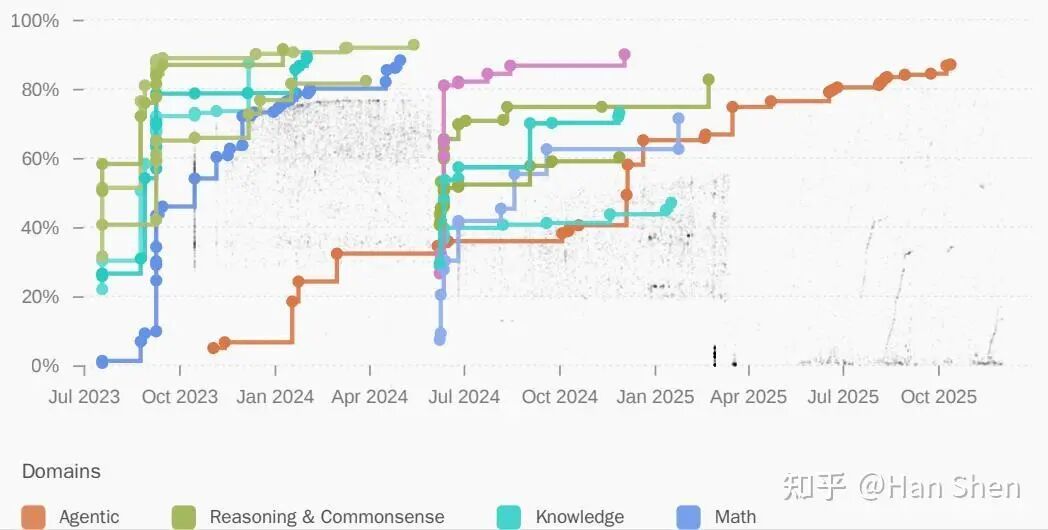
All the things you could want to know about LLM evaluation based on our experience scoring 15000 models over 3 years
核心问题与研究目标
面对层出不穷的模型排行榜、基准测试和SOTA(state-of-the-art)声明,用户和开发者需要一个清晰的框架来理解评估能做什么、不能做什么,以及如何信任不同的评估方法。
本指南旨在阐明评估的局限性与偏见,指导如何选择合适的基准(特别是2025年的相关基准),并为需要定制评估方案的用户提供设计方法。
主要面向对象与创新点:
本指南从两个核心视角阐述了评估的需求和方法,这构成了其主要贡献:
1.模型构建者视角(Model Builder Perspective):
需求:在模型开发(从头训练或微调)过程中,构建者需要通过评估来验证架构、数据组合和训练策略的有效性。他们需要快速、高信噪比的基准来进行大量的消融实验(ablations),以确保模型性能未受损害并有所提升。
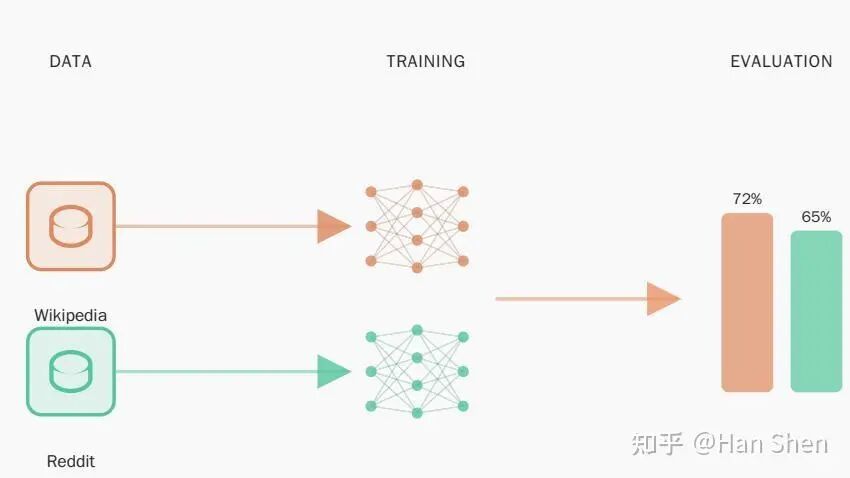
Say you want to compare dataset A and dataset B (for example, Wikipedia vs Reddit) to see how they affect model performance. You train models under the same setups on each, then evaluate and compare the scores on benchmarks.
指南提供的价值:指导构建者选择能够在模型训练早期就提供有效信号的基准,用于监控训练过程、比较不同设计选择的影响,并最终评估最终模型的性能。
2.模型使用者视角(Model User Perspective):
需求:使用者希望为特定的应用场景(如数学、编码、特定知识领域)选择性能最佳的模型。他们需要能够准确反映其用例性能的评估。
指南提供的价值:帮助使用者解读现有的排行榜和基准,并指导他们在标准基准不适用时,如何设计和实施与自己特定任务高度相关的定制评估。
核心观点与警示
指南强调,任何评估结果都应审慎看待。目前我们无法断言“某个模型在某项能力上是最好的”,而应更精确地表述为“在这些我们希望能够代表某项能力的特定任务样本上,该模型表现最好,但这并无保证”。这提醒读者要始终对SOTA声明保持批判性思维。
此外,指南还探讨了评估“通用人工智能(AGI)”的挑战,指出由于缺乏清晰定义、现有框架的局限性以及“智能”目标本身不断变化,追求一个单一的AGI评估指标可能是徒劳的。相反,我们应该专注于评估模型在具体、有用任务上的表现。
- LLM评估基础知识
============
2.1 Tokenization(分词)
模型输入的预处理。输入文本(在推理时称为prompt)首先被分割成称为tokens的小文本单元,这些单元可以是一个或多个字符,甚至是一个完整的词,每个token都与一个数字相关联。模型能够解析的全部token范围被称为其词汇表(vocabulary)。
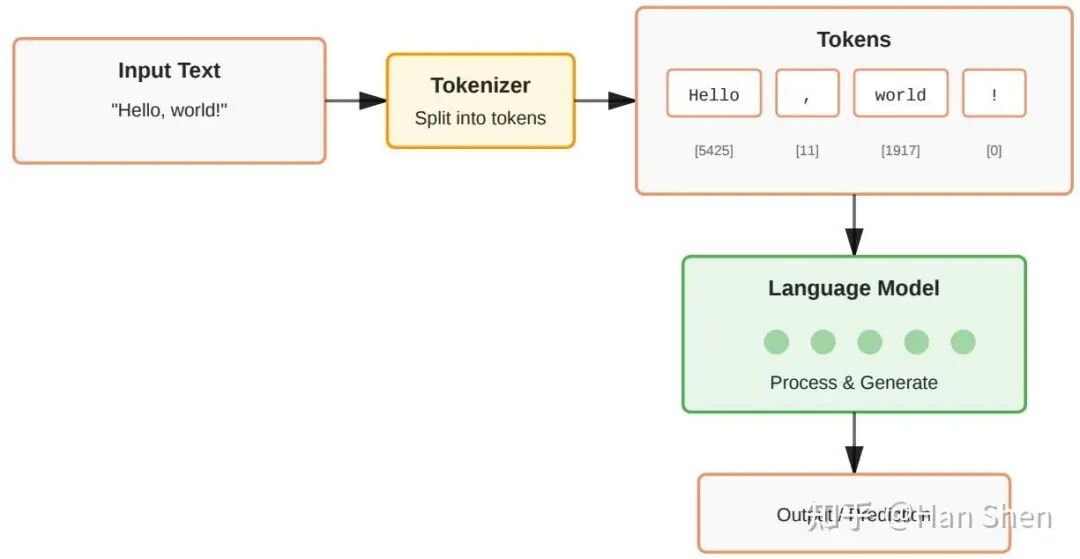
分词原理与演进。由于大型语言模型本质上是大型数学函数,它们处理的是数字而非文本。
为了将句子转换为数字,首先需要决定如何将句子切分成小块,然后将每个小块映射到一个数字,这个过程就是分词。
过去,人们尝试过基于字符的分词(例如,a -> 1, b -> 2)或基于单词的分词(例如,a -> 1, aardvark -> 2)。
这两种方法都有一个显著的局限性:它们会从输入文本中移除信息,例如抹去了可以从词形中看出的语义联系(如 “dissimilar”, “similarity”, “similarly”),而我们希望模型能保留这些信息以连接相关词汇。
因此,有人提出了将单词切分成子词(sub-words)并为这些子词分配索引的想法。
最初这是通过形态句法规则完成的,但现在大多数人使用字节对编码(Byte Pair Encoding, BPE),这是一种智能的统计方法,可以根据子词在参考文本中的频率自动创建它们。
Huggingface 还贴心给出了相关的学习材料:
Going further: Understanding tokenization⭐ Explanation of different tokenization methods in the NLP Coursehttps://huggingface.co/learn/nlp-course/en/chapter2/4⭐ Conceptual guide about tokenization in the dochttps://huggingface.co/docs/transformers/en/tokenizer_summaryCourse by Jurafsky on tokenization (and other things) - skip to 2.5 and 2.6https://web.stanford.edu/~jurafsky/slp3/2.pdfBPE⭐ Explanation of BPE in the NLP Coursehttps://huggingface.co/learn/nlp-course/en/chapter6/5BPE Paper (for text, as the method existed before in other fields)https://aclanthology.org/P16-1162/
数字分词的挑战。构建一个分词器需要做出比预期更多的选择。例如,在对数字进行分词时,不应使用基本的BPE。是只索引0到9,并假设所有其他数字都是这些数字的组合?还是想单独存储高达十亿的数字?
当前知名的模型展示了多种处理方法,但尚不清楚哪种方法更有利于数学推理。这将影响一些数学评估(这也是几乎没有纯算术评估的原因)。
Going further: Tokenizing numbers⭐ A nice visual demo by Yennie Jun of how tokenizers of Anthropic, Meta, OpenAI, and Mistral models split numbershttps://www.artfish.ai/p/how-would-you-tokenize-or-break-downSmall history by Beren Millidge of the evolution of number tokenization through the yearshttps://www.beren.io/2024-05-11-Integer-tokenization-is-now-much-less-insane/
微调模型、系统提示和聊天模板的重要性。在2022年之前,模型通常只是进行预训练:文本输入,文本输出。随后,在2023年出现了指令微调和聊天模型,2025年则出现了推理模型。
这意味着我们从使用原始文本逐渐过渡到使用越来越多的格式化。如果不确保以下几点,许多模型的表现会非常糟糕:
-
遵守模型期望的格式;
-
如果模型需要,在推理开始时添加系统提示;
-
在处理推理模型的答案之前,从中移除思考轨迹(通常可以用正则表达式移除标签之间的内容)。
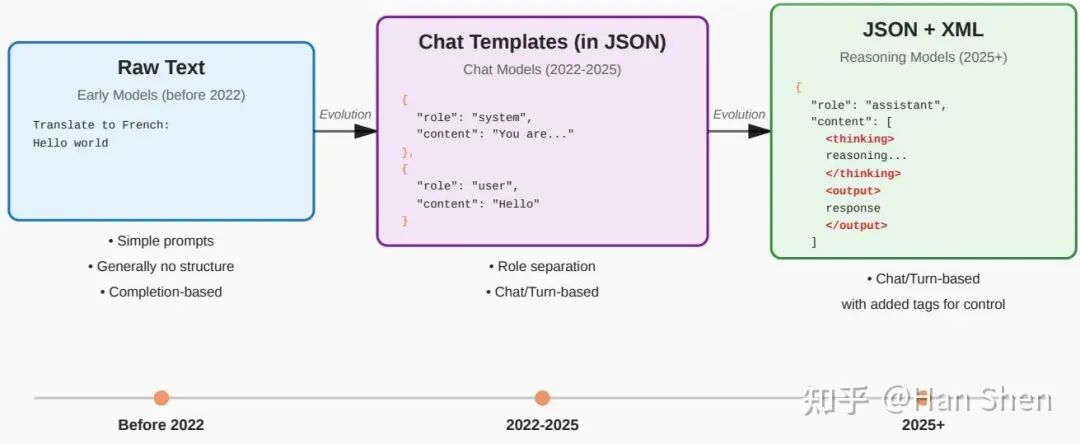
聊天模板和分词的差异。不同的分词器在处理空格和特殊token时的行为有所不同。切勿假设分词器的行为是完全相同的!
句首和句尾token的注意事项。一些预训练模型,如Gemma系列,对推理时是否包含句首token极为敏感。你可能需要做一些实验来确定你的模型是否存在这种情况,并在评估时手动添加这些token。你也可能遇到模型不会像你预期的那样在句尾token处停止的问题。代码模型通常将\n\t作为一个单独的token进行训练。
这意味着在生成文本时,它们通常会一步生成\n\t。如果一个任务将\n定义为句尾token(即停止生成),模型在预测出\n\t这个token后会继续生成,因为它与\n不同。
但在这种情况下,你实际上还是希望模型停止。这时,你需要更新你的句尾token列表,或者定义一个机制来回溯最新token的字符表示,以便在事后停止(并截断)生成。
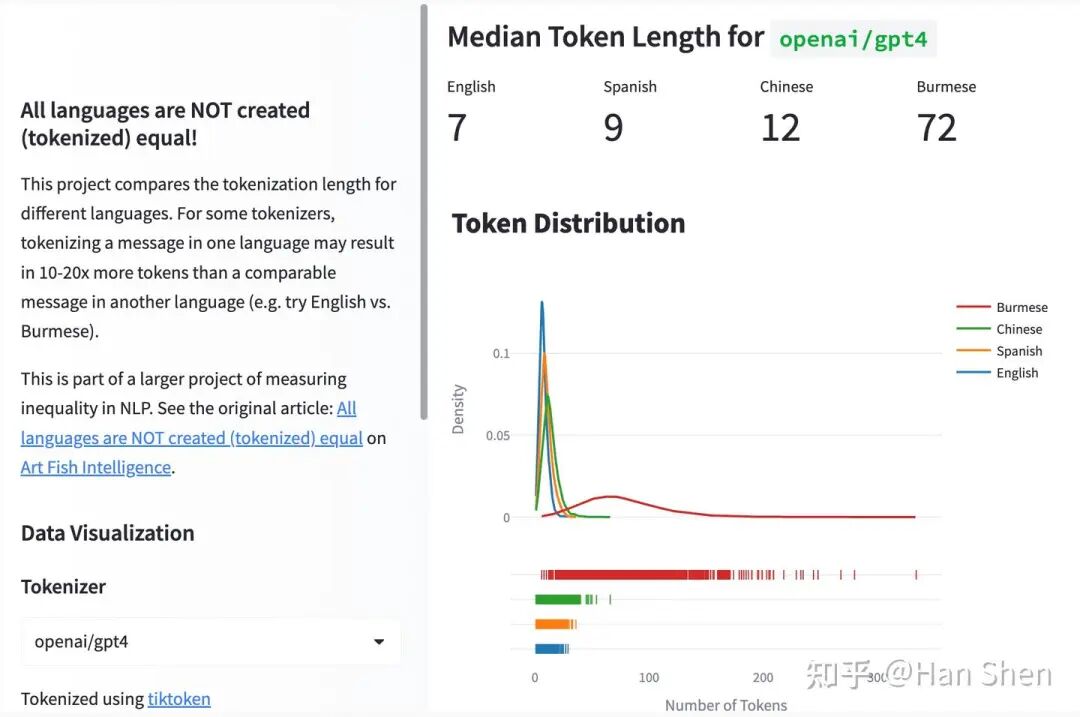
多语言分词的挑战。在进行多语言评估时,你会遇到两个问题。
首先,由于某些语言(如韩语、泰语、日语、中文等)不总是使用空格作为词的分隔符,它们需要特定语言的分词器才能被正确切分,否则会影响它们在BLEU、F1分数等指标上的得分。
其次,分词器通常可能对非英语语言不公平。在训练BPE分词器时,虽然会使用你希望覆盖的不同语言的数据,但大多数情况下,这些数据在语言之间是不平衡的(例如,英语数据可能比泰语或缅甸语多一个数量级)。
由于BPE分词器基于最高频词来创建其词汇表token,大部分长token将是英语单词,而来自较少见语言的大多数单词只会被切分到字符级别。这种效应导致了多语言分词的不公平性:一些(频率较低或资源较少的)语言需要多出几个数量级的token才能生成与英语等长的一句话。在这种情况下,模型在评估中允许生成的token数量也应依赖于具体语言。
 ```plaintext
```plaintext
Going further: Language and tokenization⭐ A beautiful breakdown and demo by Yennie Jun on tokenization issues across languages: The breakdown in itself is very clear, and the embedded space comes from her work.https://www.artfish.ai/p/all-languages-are-not-created-tokenized⭐ A demo by Aleksandar Petrov on unfairness of tokenization: I recommend looking at Compare tokenization of sentences to get a feel for the differences in cost of inference depending on languageshttps://aleksandarpetrov.github.io/tokenization-fairness/
### 2.2 推理(Inference)
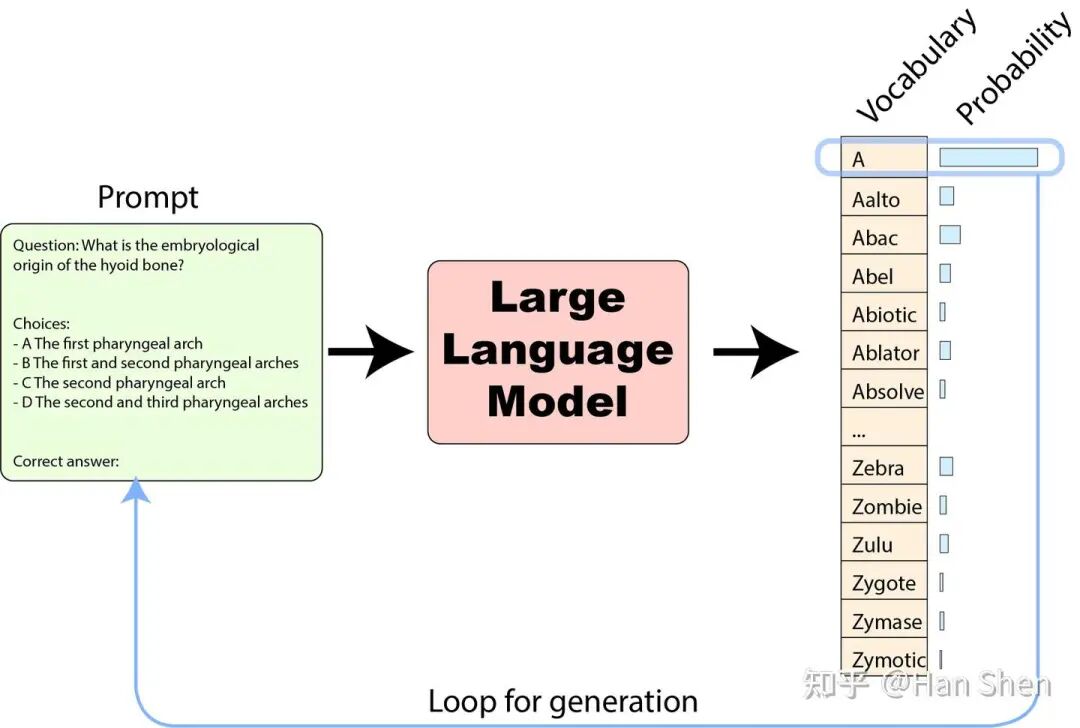
**模型生成过程**。从输入文本中,LLM会生成一个覆盖整个词汇表的、关于最可能下一个token的概率分布。
为了实现连续生成,我们可以选择最可能的token(或者加入一些随机性以获得更有趣的输出)作为下一个token,然后重复这个操作,将新的token作为prompt的结尾,如此循环。
**两种主要的评估方法**。评估方法主要有两种:
1.**对数似然评估**(Log-likelihood evaluations):给定一个prompt和一个(或多个)答案,我的模型给出这些答案的概率是多少?
2.**生成式评估**(Generative evaluations):给定一个prompt,我的模型会生成什么文本?
选择哪种方法取决于你的任务(如下所述)和你的模型:大多数通过API提供的模型不返回对数概率,因此你需要系统地使用生成式评估来评估它们。
#### 2.2.1 对数似然评估的流程与指标
对于对数似然评估,我们想要的是给定一个prompt下,一个或多个选项的条件概率——换句话说,给定一个输入,得到一个特定续写的可能性有多大?具体流程如下:
1. 我们将每个选项与prompt拼接,然后传递给我们的LLM,LLM会根据前面的token输出每个token的logits。
2. **我们只保留与选项token相关的最后logits**,并应用一个log softmax来获得对数概率(范围是[-inf, 0]而不是[0-1])。
3. 然后我们将所有单个token的对数概率相加,得到整个选项的对数概率。
4. 最后我们可以根据选项的长度进行归一化。
这使我们能够应用以下一种度量标准:在多个选项中获取模型的首选答案;测试单个选项的概率是否高于0.5;研究模型的校准情况。一个校准良好的模型是其正确答案具有最高概率的模型。
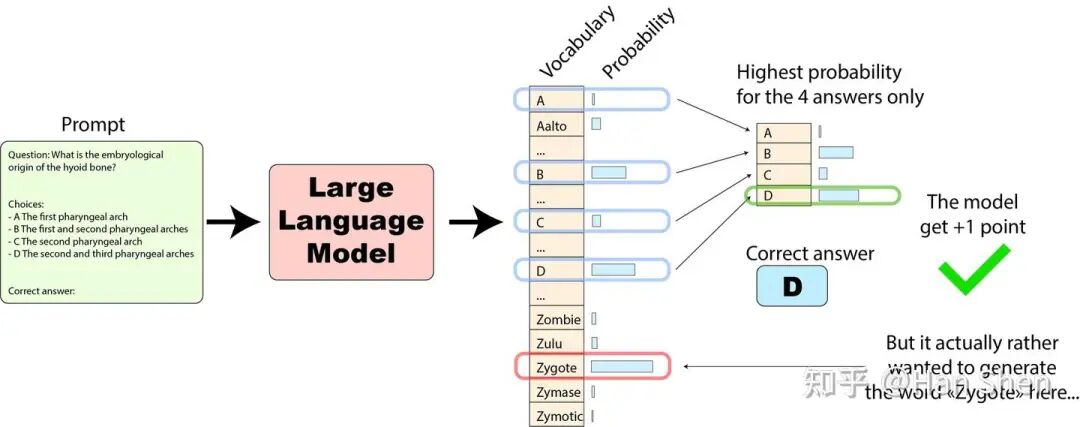
**任务表述方式及其影响**。一个多项选择题的答案也可以通过自由形式的生成评估来表达!因此,你有时会看到关于任务表述的提法。有三种常见的任务表述方式:
a) **多项选择格式(Multiple choice format)**:我们比较选项索引的似然,其中选项在prompt中明确呈现并以A/B/C/D为前缀(如在MMLU中)。
> 将任务转化为“从预设选项中选最优”,模型需计算每个选项的概率(似然),最终选择概率最高的选项作为输出。核心是“选项前置明确,模型做‘选择题’”,典型代表是MMLU(Massive Multitask Language Understanding)数据集。
#### 特殊情况:
> 在进行多项选择题(MCQA)评估时,通常需要将上下文与选项一起进行分词,因为这样能生成一串模型更容易理解、更符合语言自然规律的词元序列。但部分分词器(如 Llama 分词器)并不满足 分词(上下文+选项) = 分词(上下文) + 分词(选项) 这一条件(这类分词器会额外增加或删减空格)。
>
> 这就意味着,仅对比各选项的对数概率并非易事 —— 上下文的词元可能会 “渗透” 到选项词元中,干扰最终的对比结果。
>
> 如果你的模型存在上述问题,通常的解决思路是 “两害相权取其轻”,选择具备可比性的方案:先分别对上下文和选项进行分词,去除分词过程中可能添加的句首 / 句尾特殊词元,再将处理后的词元序列拼接起来。
b) **完形填空格式(Cloze formulation)**:我们比较不同选项的似然,而不将它们提供在prompt中。
> 将任务转化为“补全文本空缺”,模型需在不提前看到选项的情况下,计算“每个候选内容填入空缺后”的文本整体似然,最终选择似然最高的候选内容,若其填入的内容与标准答案一致,则模型正确。
>
> 核心是“选项后置隐式,模型做‘填空题’”,典型代表是CLS(Contrastive Language-Image Pre-training)的文本补全任务、BERT的预训练任务。
c) **自由形式生成(Freeform generation)**:我们评估给定prompt的贪婪生成的准确性。
> 不预设任何选项,让模型根据Prompt“自主生成完整回答”,再通过人工或自动指标(如准确率、BLEU)评估生成内容的“正确性”。
>
> 核心是“无选项约束,模型做‘简答题/论述题’”,典型代表是问答系统(如SQuAD的开放域问答)、文本摘要。
```plaintext
例子: 以“问题:中国的首都是哪个城市?”为例,完整流程分3步:1. 构建简洁Prompt:仅包含任务指令和核心问题,无需任何选项或引导性内容(确保模型自主生成)。最终Prompt示例:“请回答以下问题:中国的首都是哪个城市?”2. 模型贪婪生成回答:采用“贪婪搜索”策略(每次选择概率最高的下一个token)生成完整回答——模型从Prompt开始,逐token生成,直到触发“结束符(如<|endoftext|>)”或达到预设长度。 - 生成过程示例:模型先输出“中国”→ 接着选“的”→ 再选“首都”→ 再选“是”→ 再选“北京”→ 最后选“。”,最终生成回答:“中国的首都是北京。”3. 评估生成内容的准确性: - 自动评估:将生成回答与“标准答案(北京)”对比,若包含关键信息(如“北京”),则判定正确;或用字符串匹配(如精确匹配率)、语义相似度(如BERTScore)量化。 - 人工评估:若任务复杂(如“解释相对论”),需人工判断生成内容的“正确性、完整性、逻辑性”(如是否有事实错误、是否覆盖核心要点)。
FG需要大量的潜在知识,通常在短时间的预训练消融实验中对模型来说太难了。
因此,在进行小规模消融实验时,我们通常关注多项选择表述(MCF或CF)。然而,对于经过后训练的模型,FG成为主要的表述方式,因为我们评估的是模型是否能实际生成有用的响应。
不过,研究也表明,模型在训练早期难以处理MCF,只有在大量训练后才能学会这项技能,这使得CF更适合提供早期信号。
因此,我们建议在小型消融实验中使用CF,并在主要运行中集成MCF,因为一旦模型通过一个阈值,它能为MCF提供足够高的信噪比,从而给出更好的中段训练信号。
对数似然评估中的归一化。为了给模型的答案评分,例如在CF这样的序列似然评估中,我们将准确率计算为正确答案具有最高对数概率(按字符/token数归一化)的问题所占的百分比。这种归一化可以防止对较短答案的偏好。
2.2.2 生成式评估的流程
对于生成式评估,我们想要的是模型在给定输入prompt下生成的文本。它是通过自回归的方式获得的:我们将prompt传递给模型,查看最可能的下一个token,选择它作为模型的“选择的第一个token”,然后重复这个过程,直到达到生成结束的条件(最大长度、特殊的停止token等)。模型生成的所有token都被视为它对prompt的回答。
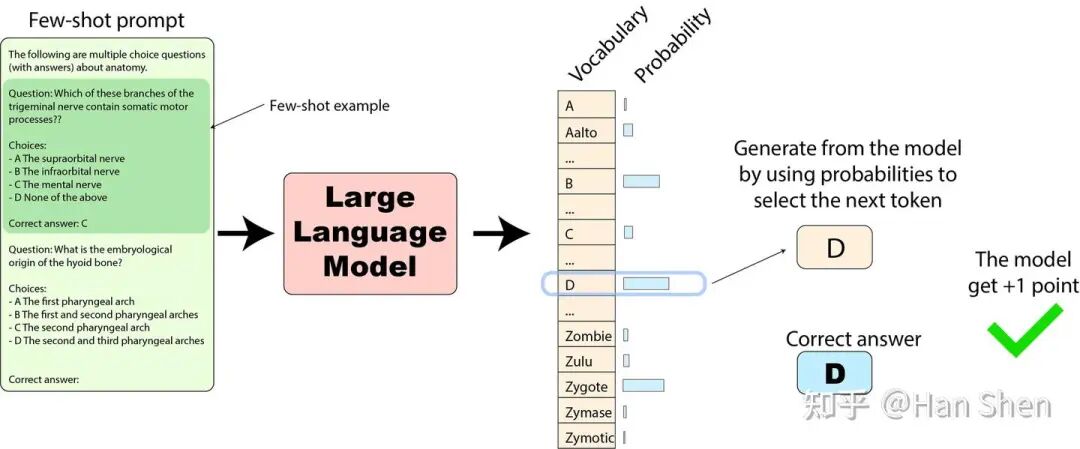
生成式评估的评分。然后,我们可以将这个生成结果与参考答案进行比较,并计算两者之间的距离(使用简单的度量标准如精确匹配,更复杂的度量标准如BLEU,或使用模型作为裁判)。
Going further⭐ Blog on several ways to evaluate MMLU , by my team at Hugging Face. I recommend reading it if you want to delve deeper into the differences between multi choice log-likelihood evaluations and generative ones, including what it can mean with respect to score changes (The above illustrations come from the blog and have been made by Thom Wolf)https://huggingface.co/blog/open-llm-leaderboard-mmlu⭐ A beautiful mathematical formalization of the above inference methods, from EleutherAI. Go to the Appendix directly.https://arxiv.org/abs/2405.14782v2
- 使用现有基准进行评估
=============
重要概念。在本节中,你会经常看到两个概念:污染(contamination)和饱和(saturation)。
- • 饱和(Saturation) 是指模型在某个基准测试上的性能超过了人类的性能。更广泛地说,这个术语用于那些不再被认为有用的数据集,因为它们失去了区分不同模型的能力。
- • 污染(Contamination) 是指评估数据集最终出现在了模型的训练数据集中,这种情况下,模型的性能被人为地夸大了,不能反映其在真实世界中处理该任务的性能。
3.1 2025年值得了解的基准
A) 推理与常识(REASONING AND COMMONSENSE)。
- • 历史数据集:如 ARC (2018)(小学科学选择题)、WinoGrande (2019)(代词消解)、HellaSwag (2019)(选择正确的下一句)、CommonsenseQA (2018)(常识问答)、PIQA (2019)(物理常识)、OpenBookQA (2018)(开卷问答)。这些数据集在BERT时代具有挑战性,但现在大多过于简单、已被污染或饱和,主要用于消融实验或预训练评估。
- • 近期数据集:Zebra Logic 使用逻辑谜题测试模型推理能力,其方法可以无限生成谜题,从而减少污染。
B) 知识(KNOWLEDGE)。
- • 历史数据集:MMLU (2020)曾是主要的知识评估数据集,但现已饱和/被污染,并暴露出问题(如不完整问题、错误答案、文化偏见)。其后续版本包括 MMLU-Redux (2024)(清理版)、MMLU-Pro (2024)(扩展版,当前社区主要替代品)和 GlobalMMLU (2024)(多文化版)。
- • 高难度数据集:GPQA (2023)包含博士级别的生物/化学/物理问题,难度很高,但自发布以来也开始出现污染。Humanity’s Last Exam (2024) 包含由各领域专家众包的2.5K个高质量问题,兼具复杂知识和推理要求,目前尚未被攻破。
- • 未来趋势:随着模型与工具(如互联网搜索)的结合,对模型潜在知识的评估正从“闭卷”转向“开卷”,评估重点将从记忆知识转向利用信息进行推理的能力。
C) 数学(MATH)。
- • 历史数据集:GSM8K (2021)(小学数学题)和 MATH (2021)(奥林匹克竞赛题)均已饱和/被污染。它们的扩展包括 GSM1K (2024)(1K新问题)、GSM-Plus(对抗性重写)和 GSM-Symbolic (2024)(使用模板无限生成问题)。
- • 当前常用数据集:
- • MATH-500[3](MATH的代表性子集)和 MATH-Hard(最难的500题)。
- • AIME (24[4], 25[5]):美国高中生奥林匹克竞赛题,每年更新,可用于检测污染。
- • Math-Arena[6]:定期更新的竞赛和奥林匹克试题汇编。
- • FrontierMath (2024)[7] 和 Humanity’s Last Exam (2025)[8]中的数学部分提供了由数学家专门设计的高难度问题。
推荐:预训练评估使用AIME25和MATH-500,后训练评估使用Math-Arena。
D) 代码(CODE)。
- • 历史数据集:MBPP (2021, Python入门问题), APPS (2021, 编程面试题), HumanEval (2021, Codex发布时引入)。
- • 扩展与变体:EvalPlus (2023) 扩展了HumanEval和MBPP,增加了更多测试用例。EvoEval (2024) 对HumanEval进行了语义重写并增加了难度标签。
- • 当前常用数据集:
- • LiveCodeBench (2024)[9]:从LeetCode等网站获取问题,并记录问题创建日期以检测污染。
- • AiderBench (2024)[10]:专注于代码编辑和重构。
- • RepoBench (2023)[11]:测试仓库级别的代码自动补全。
- • SweBench (2024)[12]:测试模型解决GitHub上真实issue的能力,涉及逻辑理解、跨文件编辑等。
- • CodeClash (2025)[13]:模型之间进行编码对抗的竞技场。
推荐:LiveCodeBench、AiderBench、SWE-Bench的高质量子集(SWE-Bench verified)。
E) 长上下文(LONG CONTEXT)。
- • 早期基准:NIAH (Needle in a Haystack, 2023) 测试在长文本中检索信息的能力,目前已接近解决。
- • 更复杂的基准:RULER (2024)[14] 增加了多跳追踪等任务。Michelangelo (2024) 和 OpenAI MRCR (2025)[15] 测试对长文本的精确复制和修改理解。InfinityBench (2024) 提供100K token的多语言(英/中)合成数据任务,仍有一定区分度。
- • 聚合基准:HELMET (2024)[16] 整合了多个任务和现有基准(如QA、RAG、摘要等),目前仍有区分能力。
- • 创新基准:Novel Challenge (2024)[17]要求模型回答关于去年出版的虚构书籍的真假问题。Kalamang translation dataset (2024) 要求模型通过阅读语法书将英语翻译成一种几乎没有在线资源的语言Kalamang。
F) 指令遵循(INSTRUCTION FOLLOWING)。
- • 核心基准:IFEval (2023)[18] 及其扩展 IFBench (2025)[19]。IFEval通过要求模型遵循格式化指令(如关键词、标点、词数等),并用特定的解析测试来检查这些条件,实现了对自由形式生成结果的严格评分,而无需依赖模型裁判。
- • 不遵循指令测试:CoCoNot (2024) 测试模型在面对不完整、无法回答或不安全请求时的合规性。
G) 工具调用(TOOL-CALLING)。
- • 领域特定:TauBench (2024) 在零售和航空领域评估模型回答用户查询和正确更新数据库的能力。
- • 通用API调用:ToolBench (2023)[20] 要求调用多种API解决问题,其稳定版 StableToolBench (2025) 引入了虚拟API服务器以确保评估稳定性。
- • 功能调用演进:BFCL (2025) 包含单轮、多轮对话、众包真实函数调用和智能体(agentic)任务等多个子集,使用抽象语法树和状态匹配进行评估。
- • MCP(模型控制平台)基准:
- • MCPBench (2025)[21] 连接LLM到真实的MCP服务器(如Wikipedia, Reddit)进行多轮任务评估。
- • MCP-Universe (2025) 使用11个MCP服务器,并采用基于执行的评估框架,自动获取最新正确答案进行比较。
- • LiveMCPBench (2025) 提供可本地部署的MCP服务器集合,测试模型在大量工具中的辨别能力。
H) 助手任务(ASSISTANT TASKS)。
真实信息检索:
- • GAIA (2023)[22] 要求模型结合工具、推理和检索来解决现实生活中的查询,其第三级难度至今仍具挑战性。
- • BrowseComp (2025)[23] 类似GAIA,但问题是从结果反向构建的。
- • GDPval (2025) 评估模型在美国主要行业的44个职业任务上的表现。
- • GAIA2 在模拟移动环境中测试助手能力,对时间敏感和噪声子集的测试最具挑战性。
科学助手:
- • SciCode (2024) 测试模型通过编写科学代码解决真实科学问题的能力。
- • PaperBench (2025)[24] 要求模型根据ICML高质量论文重建匹配的代码库。
- • DSBench (2025) 是一个多模态数据分析基准。
- • DABStep (2025) 评估模型在私有操作数据分析工作负载上的多步推理和数据处理能力。
I) 基于游戏的评估(GAME BASED EVALUATIONS)。
- • 逻辑与推理:ARC-AGI (2019)[25] 包含抽象推理谜题,其最新版 ARC-AGI3 (2025, 进行中) 包含需要探索、复杂规划和记忆的新游戏。
- • 规划与记忆:单人冒险游戏/RPG如 TextQuests (2025) 或 Pokemon (2024),以及生存游戏如 Crafter (2021),用于测试长期规划、记忆管理和回溯能力。
- • 欺骗与合作:竞争性欺骗游戏如 Poker (2025)、Town of Salem (2025),以及合作游戏如 Hanabi,用于测试逻辑、推理、欺骗和沟通能力。
- • 优点:这类评估有明确的成功/失败标准(是否赢得游戏),并且能够测试模型在动态变化环境中的适应性。
J) 预测者(FORECASTERS)。
- • 新兴类别:这类任务要求模型预测未来事件,因此无法被污染。
- • 基准:FutureBench 测试模型预测未来新闻事件的能力。FutureX 使用模板从特定网站生成关于未来事件的问题。Arbitrage 的时间跨度更长,事件将在2028年解决。
- • 挑战:尚不确定这些基准是否具有足够的区分度,其结果可能接近随机。
TLDR
截至2025年11月,推荐使用:
- • 核心能力(模型构建者):训练时使用旧的能力评估,后训练使用即将推出的AIME26、GPQA、IFEval、SWE-Bench、HELMET等长距离评估,以及针对工具使用的TauBench或BFCL。
- • 核心能力(推理时比较模型):IFBench、HLE、MathArena、AiderBench和LiveCodeBench、MCP-Universe。
- • 长远任务(真实世界性能):GAIA2、DABStep、SciCode,或针对你用例的领域特定评估。
- • 游戏(衡量鲁棒性和适应性的额外乐趣):ARC-AGI3推出后、TextQuests,如果你对安全感兴趣,可以使用Town of Salem。
查看各个benchmark 数据集的工具:
https://huggingface.co/datasets/HuggingFaceTB/post-training-benchmarks-viewer
3.2 理解评估内容
数据创建过程。理想情况下,数据集应由专家创建,其次是付费标注员、众包、合成数据,最后是MTurk。需关注数据卡(data card),了解标注员的人口统计信息以判断语言多样性或文化偏见。同时,检查数据是否经过同行或作者审查,标注员间的一致性得分是否高,以及是否有明确的标注指南。
样本检查。亲自手动检查至少50个随机样本。首先,检查内容质量:prompt是否清晰无歧、答案是否正确、信息是否缺失。
其次,检查与任务的相关性:这些问题是否与你的用例相关。还需检查样本的一致性(如多选题选项数量是否一致)。
最后,确认样本数量是否足够多(通常至少100个样本)以保证结果的统计显著性。
为何无法复现报告的模型分数?
不同的代码库。要精确复现评估分数,必须使用与论文完全相同的代码库,如EleutherAI的lm_eval或HuggingFace的lighteval。如果未提供评估代码,则几乎不可能精确复现结果。
细微的实现或加载差异。即使使用相同的代码库,以下因素也容易导致结果差异:
- • 不同的随机种子:会影响某些CUDA操作、非贪婪生成策略、few-shot示例的选择以及预处理/后处理函数。
- • 实际不同的度量标准:同名度量标准可能有不同实现,例如“精确匹配”可能是对数似然精确匹配、生成式精确匹配、前缀精确匹配或经过归一化的准精确匹配。
- • 不同的归一化:答案在比较前可能会经过不同的归一化处理(如去除标点、统一数字格式),这会显著改变结果。
- • 模型加载影响可复现性:硬件(不同GPU)、推理库(transformers, vllm, sglang)、批量大小(batch size)和加载精度(量化模型 vs. 浮点模型)都会导致结果变化。
不同的Prompt。
- • Prompt本身:Prompt格式的微小变化(例如,使用A vs A. vs A))可能导致模型分数出现几个百分点的差异。模型可能对特定基准的prompt格式过拟合。
- • 系统提示和聊天模板:对于聊天模型,不遵循其预期的聊天模板(包括系统提示、用户/助手角色标识)会严重损害性能。
- • Few-shots样本:使用的few-shot示例数量、具体内容及其顺序都会影响结果。
- • 参数:生成评估的参数,如句尾token、最大生成token数以及采样参数(温度、随机种子),必须保持一致。
3.3 为模型训练自动选择好的基准
多样性与可靠信号。FineWeb团队为预训练消融实验设计了一套选择最佳评估任务的方法。目标是确保评估的多样性(覆盖阅读理解Reading comprehension、通用知识General knowledge、自然语言理解Natural Language Understanding、常识推理Common-sense reasoning、生成任务Generative tasks 等)和每个任务都能提供可靠的信号。
可靠信号的定义。一个可靠的信号应满足:分数高于随机基线、随训练进程单调增加、不同随机种子下的变异性低,并且在每个训练步骤中对模型的排序保持一致。
为深入验证研究所涉及任务提供的信号有效性,研究人员针对每种目标语言,利用五大开源多语言网络数据集的目标语言子集(总计 300 亿个 token),训练了多个参数量为 15 亿的模型,且所有模型均采用相同的超参数与分词器。随后在模型训练的不同检查点阶段,以零样本(无指令、无系统提示词)的方式对这些模型开展任务评估。
由于任务实现方案需要反复迭代优化,每项任务都要进行多次评估,整个过程累计消耗 7.3 万小时的 GPU 算力。
最终,在完成 49 个模型的训练后,研究人员明确了 “可靠信号” 的定义标准。
评估信号可靠性的标准。
1.单调性(MONOTONICITY):任务分数应随训练步数增加而稳定提升。使用Spearman秩相关系数来衡量,要求平均相关性至少为0.5。
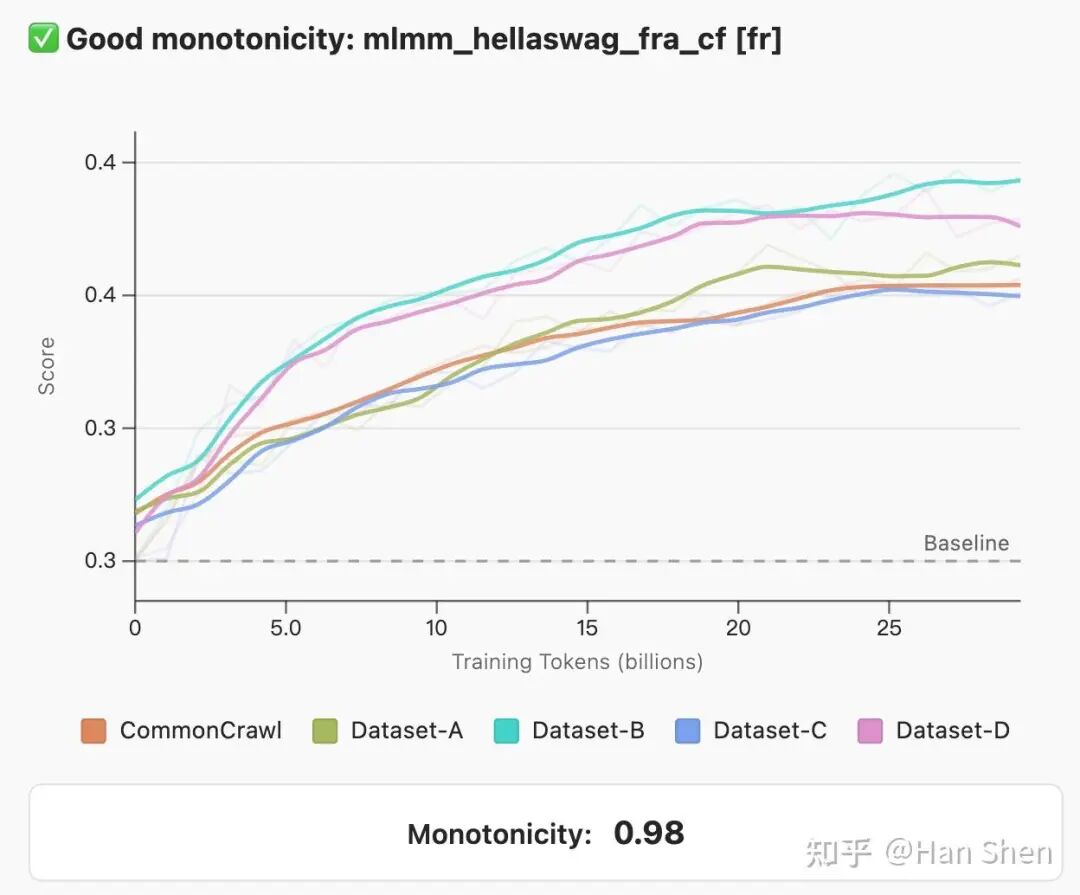
正确的单调性指标
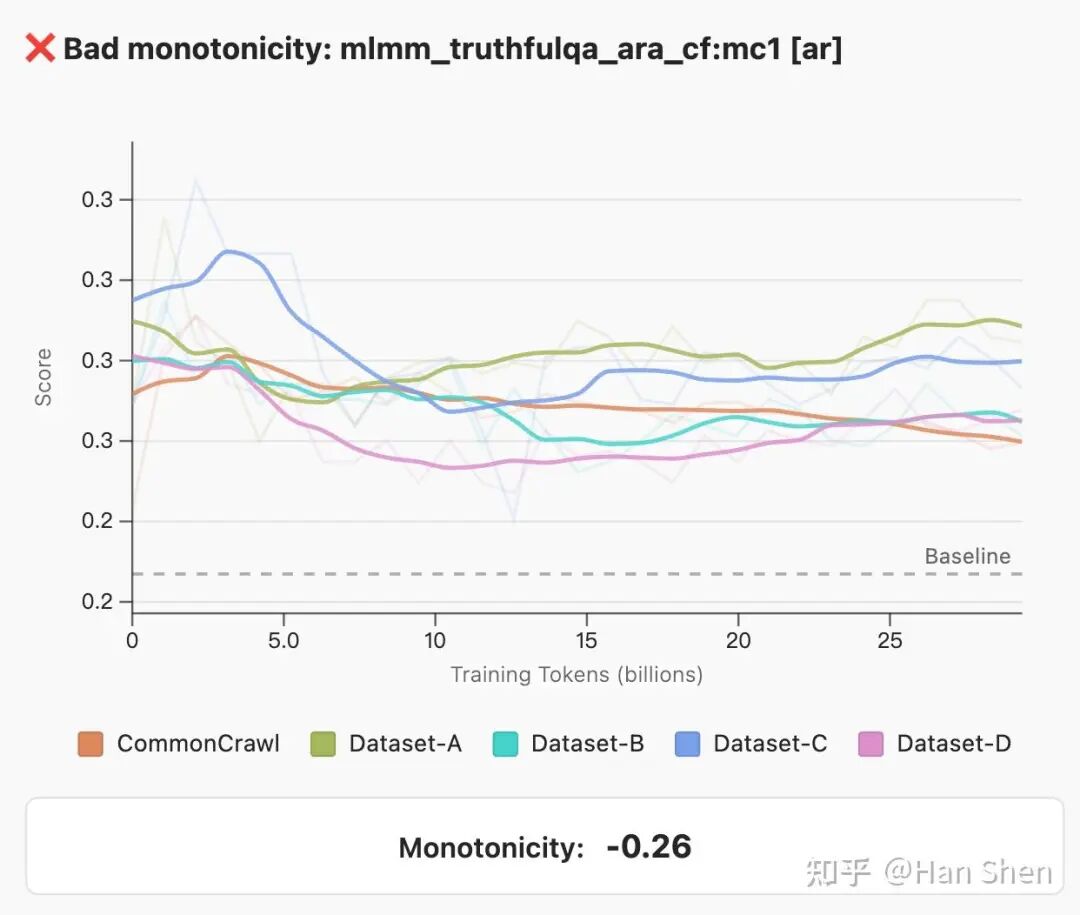
错误的单调性指标
2.低噪声(LOW NOISE):
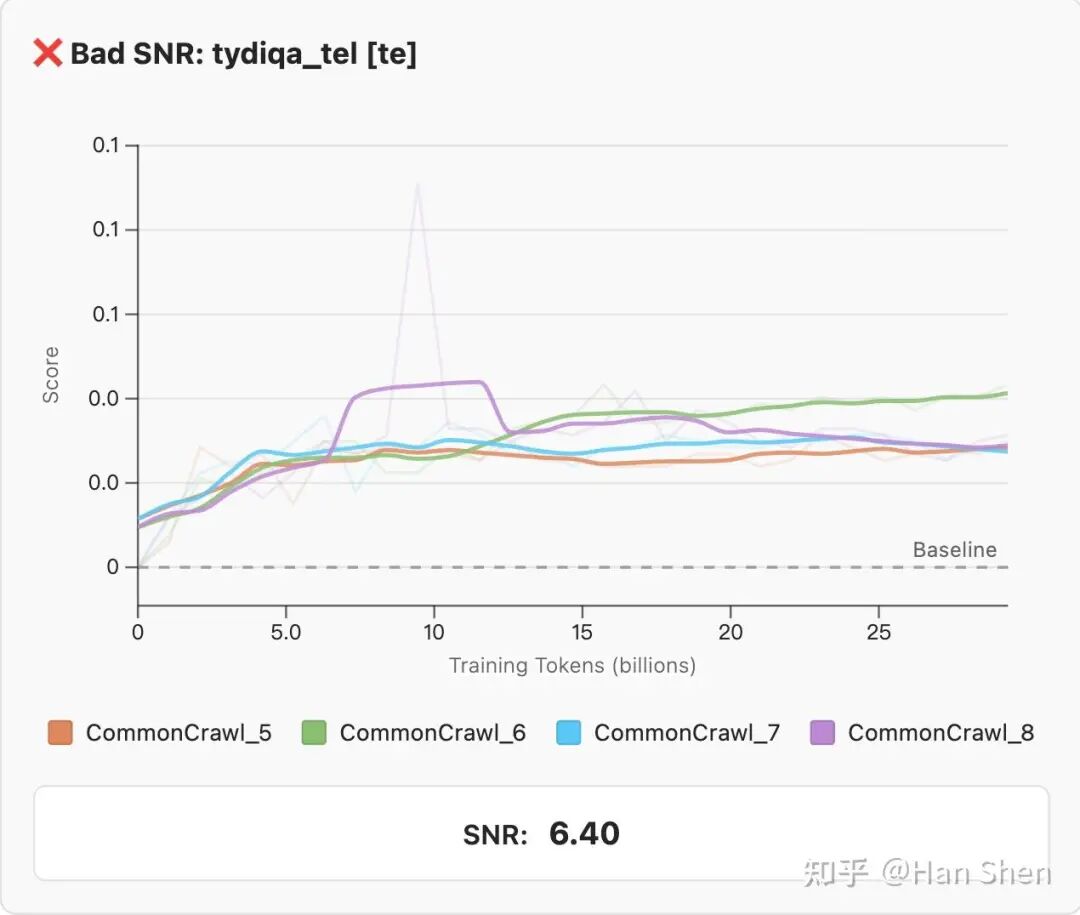
训练中的随机过程(如随机 token 采样、数据打乱、模型初始化)会产生噪声。为衡量各任务对噪声的敏感度,研究人员基于不同随机种子,在单语语料库(各语言未经筛选的 CommonCrawl 数据)上额外训练了 4 个模型,并针对每项任务计算三个核心指标:
1)单步标准差(per-step-std):即模型在每个训练步(约每 10 亿 token)得分的标准差;
2)平均标准差(avg-std):将所有单步标准差取平均值,作为训练全程的整体变异性指标,且该值被视为不同模型架构与数据集下的变异性上限;
3)信噪比(SNR):用 300 亿 token 训练阶段所有模型运行的平均得分除以平均标准差,作为衡量任务变异性的核心指标,反映整体得分相对噪声的显著性。
研究设定任务的信噪比阈值为 SNR > 20,仅生成式任务例外 —— 这类任务信噪比通常较低,但能反映模型无约束生成时的表现,在多语言场景中尤为重要,部分多语言模型虽任务得分高,却可能在生成式任务中突然输出错误语言。

好的SNR
3.非随机性(NON-RANDOMNESS):模型性能应显著高于随机猜测。要求基准运行性能至少比基准随机基线高出3个最终标准差。
研究人员首先计算了任务的随机基准性能—— 对于选择题,其值为所有样本的1/nchoices之和;对于生成式任务,其值为 0。随后,通过计算所有模型在该任务上的最高得分与基准值的差值,得出了任务相对基准的提升幅度。
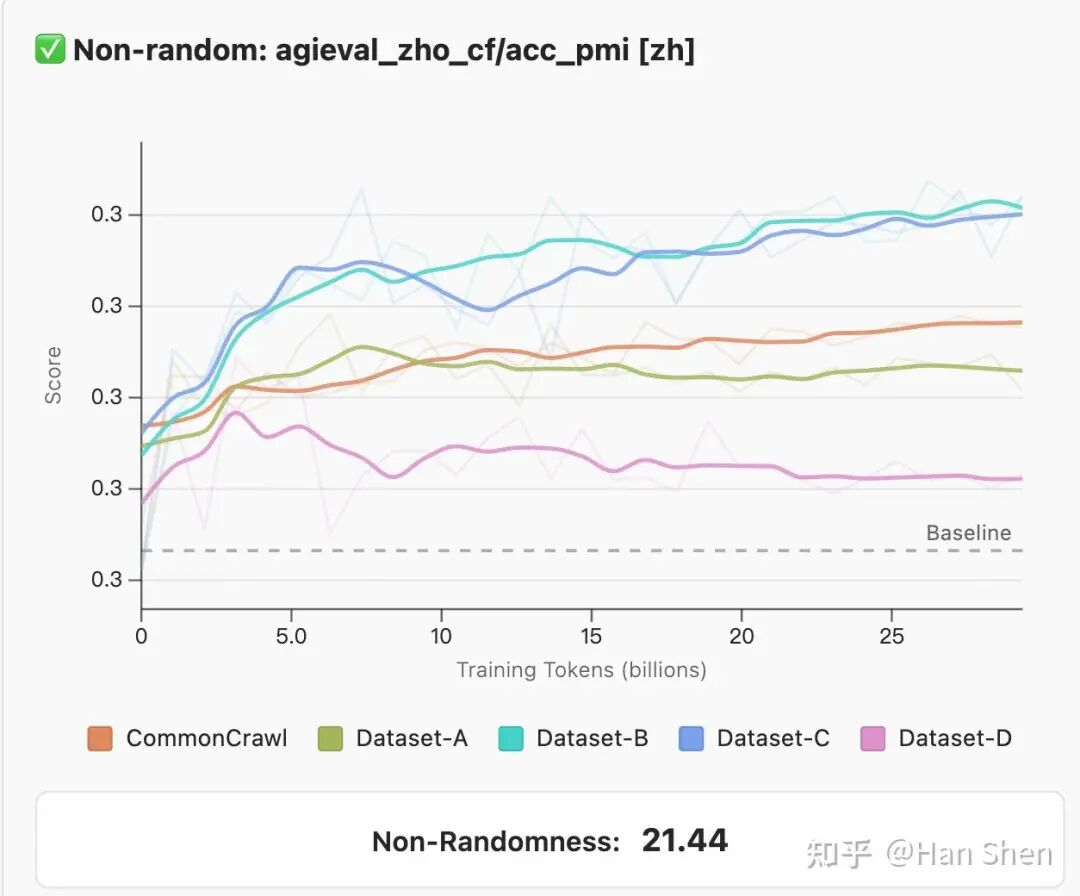
非随机猜测:高于baseline
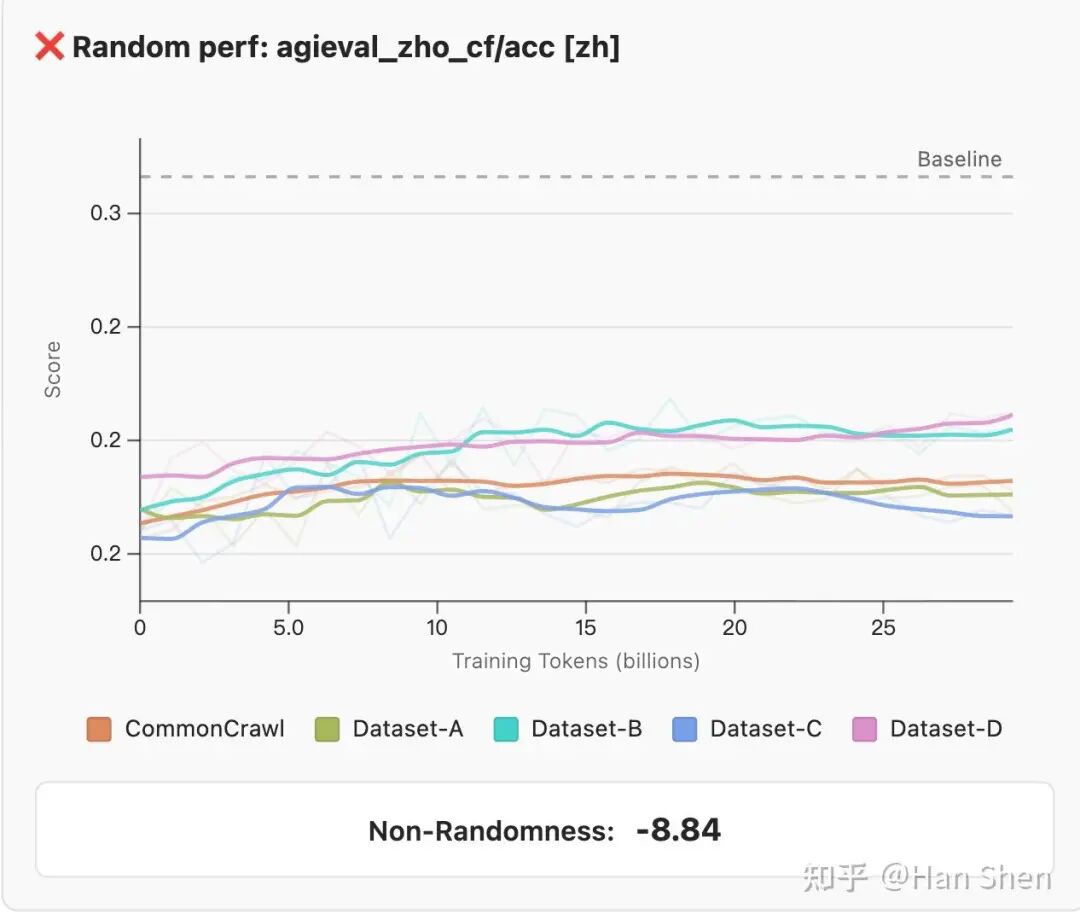
随机猜测:低于baseline
4.排序一致性(CONSISTENT ORDERING):
本次评估的核心目标是对比模型与数据集的表现。未来研究人员计划借助这些评估结果,筛选出适用于模型完整预训练的最优数据集。
这就要求相关任务在小数据量训练(通常为 300 亿 token 的数据集消融实验)下对数据集的排序结果,能与更大数据量、更长训练步数后的排序结果保持一致。
换言之,这些任务需要具备预训练性能的预测能力:若预训练数据集 A 在 300 亿 token 阶段的表现优于数据集 B,那么希望这一优势在 3000 亿 token 阶段也能延续。
这种预测能力虽无法被完全验证,但存在一个可检验的必要前提条件 —— 要实现大规模训练下的结果一致性,必须先保证小尺度训练下的结果一致性。
为衡量任务排序的一致性,研究人员计算了模型在每两个连续训练步之间排序结果的平均肯德尔等级相关系数(Kendall’s Tau)。需要注意的是,计算仅选取预训练步数达到 150 亿 token 之后的阶段,因为研究发现该节点之前的排序结果噪声极大。该指标数值越高,表明训练过程中数据集的排序一致性越强。
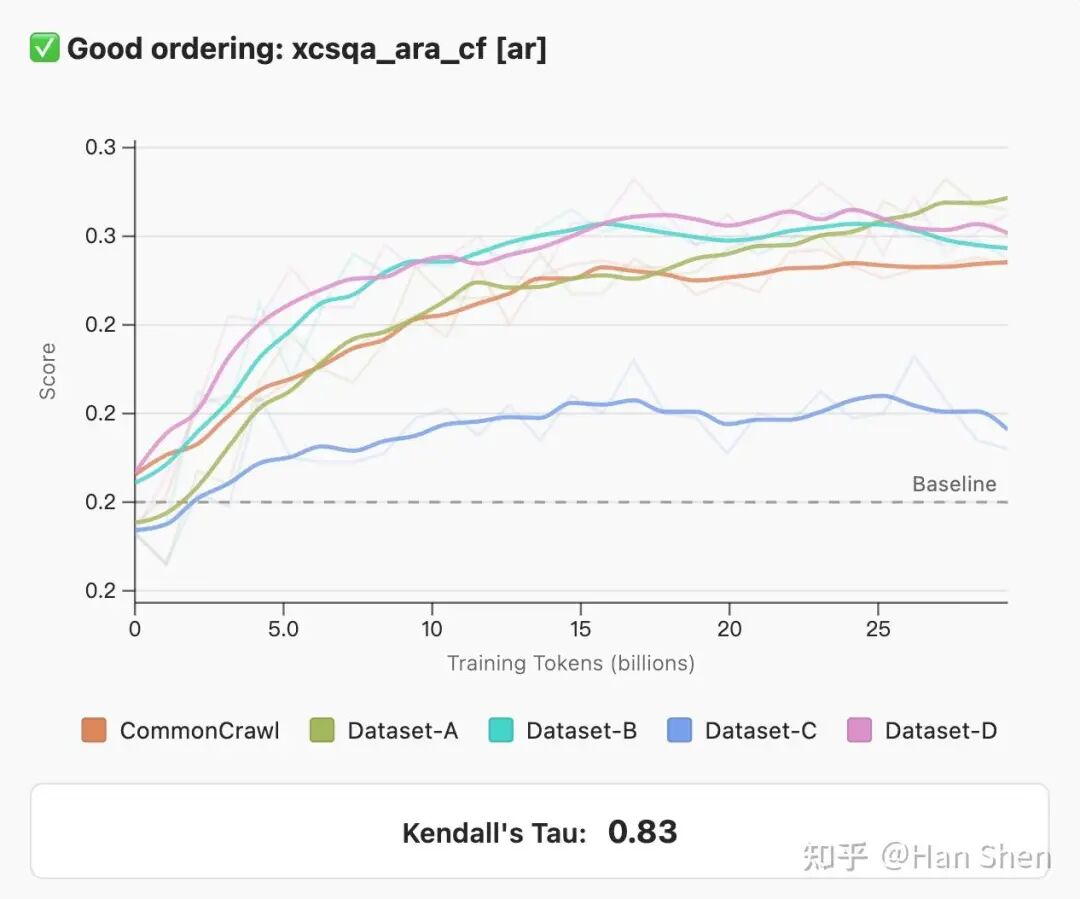

5. 度量标准(METRICS)。
多项选择任务的准确率变体:为解决答案长度和词频偏差,考虑以下准确率:
- • 基础准确率:
- • 按字符长度归一化的准确率:
- • 按token长度归一化的准确率:
- • PMI准确率: ,其中
其中, 代表选项 , 代表问题提示词, 代表在给定提示词 的情况下,模型输出选项 的概率。
A) 生成任务的度量标准:
- • prefix_match: 精确匹配,但只要求答案的前缀匹配。
- • f1: 在预测词和标准词上计算的F1分数。
B) 度量标准选择建议:
- • 多项选择:对于答案选项差异微小的任务(如NLI),基础准确率表现良好。对于困难的推理和知识任务(如AGIEVAL、MMLU),PMI最有效。在大多数情况下,长度归一化度量(字符或token)最为可靠,推荐使用max(acc_char, acc_token)。
- • 生成任务:除非需要精确匹配(如数学任务),否则建议使用F1分数,因为它噪声更小,对生成的微小变化更具鲁棒性。
- 创建自己的评估
==========
4.1 使用现有数据
你可以聚合多个现有数据集来创建一个针对特定能力的评估套件。当需要评估的某项特定能力无法通过单一基准测试充分覆盖时,数据集聚合是一种有效的方法。
无需从零构建,只需整合多个现有数据集的样本,即可打造出针对性的评估套件。例如《Measuring AGI》一文的作者,就通过这种方式构建了全新的 “AGI 评估” 数据集。进行数据集聚合时,需重点关注三个问题:
1.数据集间是否存在数据冗余(多数数学类数据集的题目,本质都是对初始问题的改写或整合);
2.是否需要保证各数据源的代表性均衡(要避免某一个数据集占比过高,导致评估结果出现偏差),这一点也会决定评估分数的计算方式 —— 是对所有样本的分数直接汇总,还是按子集分别计算后再整合;
3.各数据集的格式与难度是否兼容(通常在构建统一数据集时,需注意区分样本是否需要随机抽样,避免混合使用)。
典型的数据集聚合案例包括 MMLU、Big-Bench(涵盖数百项多样化任务)以及 HELM(整合多个现有基准测试,实现全方位评估)。
此外,EpochAI 在 2025 年的最新研究,还展示了如何在统一框架下优化基准测试的聚合方式,让聚合后的数据集整体难度更高,且不易出现评估指标饱和的问题。
4.2 使用人类标注员
构建高质量标注数据集的关键步骤包括:
- • 标注流程:迭代式标注、精心选择数据、设计标注方案和指南、进行试点研究和验证。
- • 标注员:选择合适的团队、进行资格测试和培训、提供合理的金钱激励。
- • 质量估计:使用错误率、控制问题和一致性协议来评估质量。
- • 质量改进:修正错误、更新指南、筛选数据和标注员。
- • 裁决:通过人工策划、多数投票或概率聚合来解决分歧。
你大概率希望参与任务的人员满足以下要求:
1.符合特定人口统计特征。例如:是目标语言的母语者、具备高等教育学历、拥有特定领域的专业知识、地域来源多样化等。具体要求需根据任务需求而定。
2.产出高质量成果。如今,尤为重要的一点是加入检测答案是否由大语言模型生成的环节,同时需要从标注人员池中筛选掉部分不合格者。在我看来,除非你能依靠积极性极高的众包标注员,否则给予标注人员合理报酬始终是更优选择。
核心准则是:明确任务和评分指南,仔细选择并培训标注员,通过多轮迭代和质量控制来确保数据质量。
4.3 以合成方式创建数据集
基于规则的技术:对于数学、逻辑或编码等任务,使用程序化生成基准是一种避免污染并获得无限样本的好方法。
例如,IFEval、GSM-Symbolic等都采用这种方法,通过算法生成测试用例,同时控制难度并实现自动验证,确保模型在训练阶段未接触过相关样本。
典型案例包括 NPHardEval(生成图论等复杂度可控的任务,每月更新以降低过拟合)、MuSR(通过神经符号生成方式构建千词级谋杀谜案等复杂推理任务)、ZebraLogic(借助 SAT 求解器生成逻辑网格谜题)等。这类方法适用于测试模型的数学、逻辑或代码能力。
使用模型创建合成数据:通常从一些种子文档(如Wikipedia)开始,将其分块,然后使用一个前沿模型根据这些数据设计优质提示词,引导模型基于这些数据生成与使用场景相关的问题,最好要求模型标注问题对应的数据源。
若追求全流程合成,还可将种子提示词作为示例,让外部模型编写提示词,再驱动目标模型生成新问题。生成完成后,可引入不同系列的模型作为 “裁判”,结合真值数据、问题及答案进行自动验证。无论自动化程度多高,都必须在每一步手动检查数据以确保评估质量。
管理污染(contamination)。应假设任何公开发布在互联网上的数据集都可能或将会被污染。缓解措施包括:在评估集中加入“金丝雀字符串”(如BigBench)、以加密或门控形式提供评估集、运行动态更新的基准、以及事后尝试检测污染(如通过查看生成困惑度)。然而,没有任何一种方法是万无一失的污染检测手段。
选择Prompt。Prompt定义了向模型提供任务信息的方式。即使是语义等价的prompt,微小的变化也可能导致结果显著不同。可以通过多次运行不同prompt变体或在一次评估中使用多种prompt格式来缓解这个问题。使用few-shot示例可以帮助模型遵循预期格式。
为你的模型选择推理方法。
- • 对数似然评估:适用于多项选择题(MCQA),用于测试知识或消歧能力。优点是确保所有模型均可获取正确答案、可作为衡量模型 “置信度”参考、快速、能为小模型提供信号。缺点是可能高估了那些本会生成范围外答案的小模型的得分,并且可能受选项顺序影响。
MCQA 评估提速技巧
让模型仅预测单个 token(如选项对应的 A/B/C/D 标识),可大幅提升 MCQA 评估的速度。
传统方法需针对每个选项(context + 选项 1、context + 选项 2……)分别运行推理,而新方法只需基于题干文本运行一次推理,计算全词汇表的概率分布(包含所有单 token 选项),即可直接获取目标对数概率。
- • 生成式评估:是目前大多数评估采用的方式,适用于测试流畅性、推理或实际回答问题的能力。优点是与LLM的实际应用能力相关性强,且是评估闭源和开源模型的唯一途径。缺点是评分更困难且成本更高。
若采用对数概率进行评估,对应的指标设置会较为简单:核心指标通常是某种形式的准确率(即最可能的选项为正确答案的频率)。需要注意的是,该指标需按序列长度(字符、token 或点互信息 PMI 均可)进行归一化处理;除此之外,也可以选用困惑度、召回率或 F1 分数作为辅助指标。
而如果采用生成式评估,指标设置的难度就会大幅上升 —— 下一章将专门围绕这一内容展开。
- 评估的主要挑战:为自由形式文本评分
====================
5.1 自动化评估
当有groundtruth存在时:
5.1.1 度量指标(METRICS)
文本与参考答案的自动比对方法大多基于匹配原理,这类方法更适合用于未纳入模型训练集的数据,以此检验模型的泛化能力。
A)基于匹配的度量:
最简单的是精确匹配(Exact Match),但它不提供部分分数——哪怕预测结果仅错一个词,也会和完全错误的结果得到相同的分数。
在机器翻译和文本摘要领域,研究者提出了通过序列 n 元语法重叠度衡量相似度的自动指标,常见的有:
1.BLEU:通过计算与参考译文的 n 元语法重叠度评分,应用广泛,但存在偏向短译文的缺陷,且在句子层面与人类评价的相关性较差,对语义等价但表述不同的预测结果评分效果不佳。
2.ROUGE:原理与 BLEU 类似,但更侧重召回率导向的 n 元语法重叠度。
3.TER:即翻译错误率,计算将预测文本修正为参考文本所需的编辑次数,原理近似编辑距离。
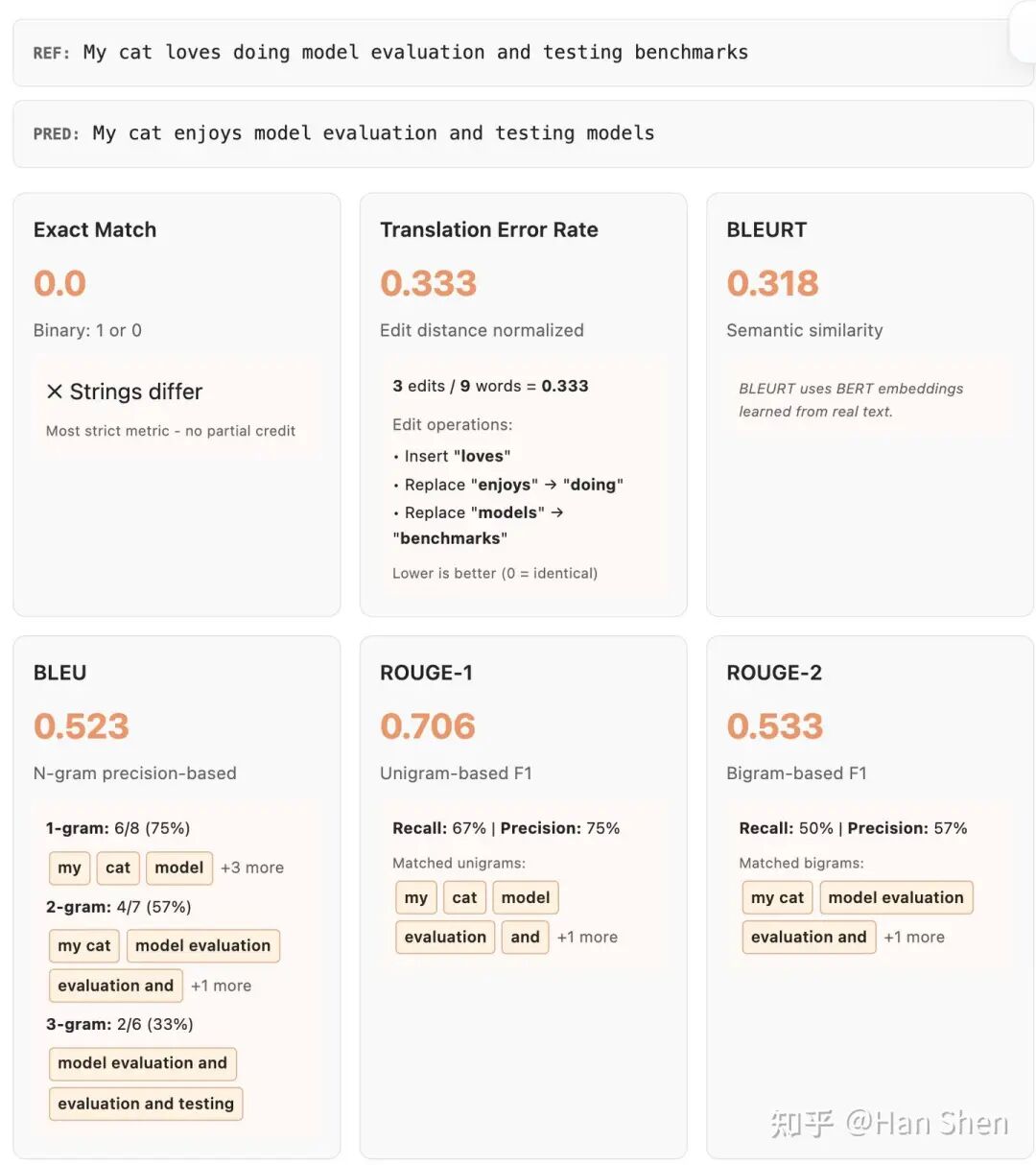
得到单样本准确率后,可通过多种方式对全数据集的分数进行聚合,常规做法是计算平均值,也可根据需求采用更复杂的聚合方式(部分指标本身自带聚合逻辑,如 CorpusBLEU)。
聚合方式的选择需结合分数类型:
二分类分数:可选用精确率(在假阳性代价高昂的场景至关重要)、召回率(在漏检阳性代价高昂的场景至关重要)、F1 分数(平衡精确率与召回率,适合不平衡数据)或马修斯相关系数(MCC,综合考虑混淆矩阵所有元素,对不平衡数据集表现优异)。
连续型分数(此类情况相对少见):可选用均方误差(MSE,对大误差进行惩罚,但会过度加权异常值)或平均绝对误差(MAE,相比 MSE 更为均衡)。
若假设数据符合特定线性回归模型(例如研究模型校准度时),还可采用R2、皮尔逊相关系数(适用于线性关系,需满足正态性假设)或斯皮尔曼相关系数(适用于单调关系,无需正态性假设)等指标,但这类指标超出了当前讨论范围。
更重要的是,选择指标及聚合方式时,需紧扣任务的核心目标。在部分领域(如医疗领域、面向公众的对话机器人领域),关注点不应是平均性能,而是最差性能的评估方式(例如医疗场景的输出质量、对话场景的毒性风险等)。
自动化指标的优缺点:
- • 优点:一致性与可复现性、低成本易扩展、易理解性
- • 缺点:自动化指标在复杂任务上的适用性受限:这类指标通常需要依托唯一、明确且无歧义的标准答案,因此更适用于任务目标和评估标准清晰的场景(如毒性分类、单一答案的知识问答)。
To go further
This blog covers some of the challenges of evaluating LLMs.
f you’re looking for metrics, you’ll also find a good list with description, score ranges and use cases in this organisation.
5.1.2 归一化
归一化指将字符文本转换为符合特定参考格式的过程。在比对模型预测结果与参考答案时,通常不需要因为预测文本存在额外空格、标点或大小写差异而扣分,这正是进行归一化处理的目的。
归一化对于部分特定任务至关重要,例如数学类评估任务—— 这类任务需要从模型的长文本预测结果中提取公式,并与参考答案进行比对。
文中还提及会以表格形式列举,在 MATH 数据集上直接使用 SymPy 提取预测结果时遇到的各类问题,以及专用数学解析工具 Math-Verify 针对这些问题的解决方法。
若设计不当,归一化操作可能导致评估有失公允,但总体而言,它仍能为任务层面提供有效评估信号。归一化在思维链(CoT)或推理类任务的预测评估中尤为关键 —— 这类任务需要从模型输出中剔除推理过程(不属于最终答案的部分),才能提取出用于比对的真实答案。
5.1.3 采样
模型生成结果时,多次采样并聚合结果,相比单次贪心生成,能提供更稳健的评估信号,这一点在复杂推理任务中表现突出,因为模型可能通过不同路径得出正确答案。
常见的基于采样的评估指标包括:
- • pass@k over n:在 n 次生成样本中,衡量至少有 k 个样本通过测试的概率。有两种计算方式,一种是简单判定(当正确样本数 时即视为通过),另一种是使用无偏估计公式计算: (c 为 n 个样本中的正确样本数)。
- • maj@n(多数投票):生成 n 个样本,选取出现频率最高的答案。该指标能过滤异常输出,在模型正确推理路径比错误路径更稳定的场景(如数学、推理任务)中效果显著。
- • cot@n(思维链采样):生成 n 条推理轨迹并逐一评估,可结合多数投票或 pass@k 指标使用(生成 n 条推理链,提取最终答案后进行投票或阈值判定)。
- • avg@n(稳定平均分):对 n 个样本的得分取平均值,相比选取 “最佳样本” 或 “最常见样本” 的得分,是更稳定的模型性能评估指标。

使用采样评估时,需完整报告所有采样参数(如温度、top-p、k 值),这些参数会对评估结果产生显著影响。
采样评估的适用场景与禁忌如下:
1.训练阶段评估 / 消融实验:❌ 通常应避免使用。采样评估成本高且会增加结果方差,建议采用固定随机种子的贪心解码方式。
2.训练后评估:✅ 推荐使用。采样评估能够挖掘出贪心解码难以体现的模型能力,尤其适用于推理、数学、代码等复杂任务。
3.推理阶段:✅ 适用。这类指标可预估推理时多次采样带来的性能提升空间,对于探索如何通过测试阶段的算力投入提升小模型效果尤为有用。
5.1.4 功能性评分器(Functional scorers)
功能性评分器区别于基于模糊字符串匹配的文本比对方法,它的核心逻辑是评估模型输出是否满足特定可验证的约束条件。这种方法优势显著,不仅灵活性更高,还能结合基于规则的生成方式实现测试用例的 “无限” 更新,从而有效降低模型过拟合的风险。
在指令遵循类评估任务中,IFEval 和 IFBench 是该方法的典型应用案例。这类评分器不会纠结于 “输出文本是否与参考答案匹配”,而是聚焦于 “输出文本是否满足指令中给定的格式约束”,例如:
- • 验证输出是否包含恰好 3 个项目符号
- • 检查文本是否仅首句首字母大写
- • 统计 “algorithm” 一词的出现次数是否不少于 2 次
- • 确认输出是否为包含 “answer” 和 “reasoning” 键的合法 JSON 格式
每个约束条件都能通过专门的规则验证器进行检查,这让这类评估具备*无歧义、易解读、速度快8的特点,且成本远低于使用模型作为评判器的方式。
功能性评估方法在指令遵循任务上表现突出,但要拓展到文本的其他属性评估,需要更多创新思路。其关键在于,要找到文本中能够通过程序化方式验证的特征,而非依赖语义层面的比对。
5.2 人类评分
方法:
- • Vibe-checks:社区成员进行的非正式手动评估,以获得模型在特定用例上的“感觉”。优点是成本低。
- • 竞技场(Arena):如LMSYS聊天机器人竞技场,通过大规模社区投票对模型进行Elo排名。核心问题是主观性极强。
- • 系统性标注:向经过挑选的付费标注员提供极其具体的指南,以尽可能减少主观偏见。缺点是成本会快速攀升。系统化人工评估的三种具体落地方式:
- • 无数据集时:给标注者设定任务和评分准则(如 “尝试诱导两个模型生成有毒内容,生成得分为 0,未生成为 1”),并开放模型交互权限,让其打分并给出理由。
- • 已有数据集时(如用于安全评估的敏感提示词集):先让模型基于提示词生成内容,再将提示词、模型输出和评分准则一并交给标注者评估。
- • 已有数据集和评分结果时:让标注者进行错误标注,以此检验评估方法的合理性,这一步骤虽对完善评估体系至关重要,但本质属于 “评估评估方法”,超出了常规模型评估的范畴。

偏见:人类评估存在多种偏见,如第一印象、语气偏见、自我偏好(与标注员价值观一致)和身份偏见(不同身份群体评分不同)。

5.3 使用模型作为裁判
- • 概念:使用神经网络(通常是LLM)来评估其他神经网络的输出。
两种主流实现思路
- • 通用大模型评判:直接使用能力较强的通用大语言模型[26],通过设计明确的提示词告知其评分标准(如 “按 0-5 分评估文本流畅度,0 分为完全无法理解”),让模型完成打分。
- • 专用小模型评判:训练专门的小型模型[27],这类模型基于偏好数据学习判别能力,类似 “垃圾信息过滤器” 的逻辑,可针对性评估某一属性(如文本毒性)。
三大核心应用场景
-
• 按给定评分尺度,评估模型生成文本的特定属性(如流畅度、毒性、连贯性、说服力等)。
两两比对模型输出,选出在某一属性上表现更优的文本。 -
• 计算模型输出文本与参考文本之间的相似度。
-
• 优缺点:支持者认为模型裁判比人类更具客观性、可扩展性且成本更低。然而,它们引入了许多难以察觉的隐藏偏见,并且可能产生“回声室效应”,从而强化偏见。
-
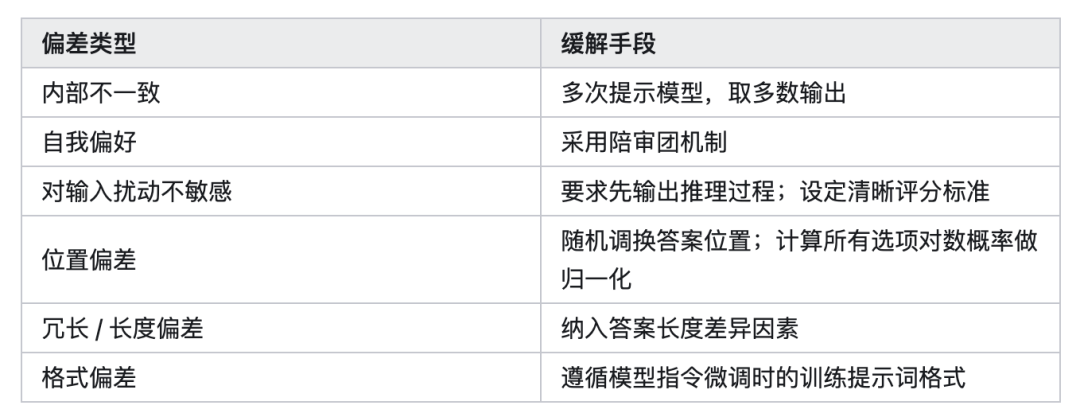
• 偏见:模型裁判存在多种偏见,包括内部不一致、自我偏好、对输入扰动的盲目性、位置偏见、冗长偏见和格式偏见。
核心弊端:隐性且不可解释的偏差
作者个人认为,模型评判法最大的问题在于,它会在答案筛选过程中引入极其隐蔽、难以解释的偏差。这种情况类似于遗传学研究中过度杂交的后果 —— 可能会培育出功能异常的动植物;
同理,用大语言模型去筛选和训练其他大语言模型,很可能会引入细微的改变,而这些改变会在后续的模型迭代中引发更严重的影响。
不过作者也提出,小型专用评判模型(如毒性分类器)出现这类偏差的概率相对较低,但这一点仍需经过严谨的测试和验证。
5.3.1 实践指南
建议先阅读一份优质的入门指南,学习如何搭建首个大语言模型评判系统。
可以尝试使用 distilabel 库[28],该工具支持利用大语言模型生成和更新合成数据,同时还提供了相关教程:包括应用 Ultrafeedback 论文方法论的教程,以及实现 Arena Hard 基准测试的教程。
- • 模型选择:可使用闭源模型(如Claude,GPT-o)、开源模型(如DeepSeek R1)(较好复现性)、微型专用模型(如Prometheus)或自己训练的模型(不建议)。
- • Prompt设计:例子:MixEval[29],MTBench[30]
提供清晰的任务描述: 清晰告知模型要完成的任务(如 “你需要完成 X 任务”)、会提供的输入内容(如 “将为你提供 Y”)
界定评估标准:说明评估的具体属性,如需评分则给出详细分值定义(如 “按 1-5 分评估属性 Z,1 分代表……”);如需判定属性是否存在,需明确判定条件。、
补充推理步骤:规定评估的操作流程(如 “先仔细阅读样本 Y,确认……,再进行……”)。
指定输出格式:统一输出规范以保证一致性,推荐结构化格式(如 JSON 格式包含 “Score” 和 “Reasoning” 字段)。
-
提高准确性:成对比较比直接打分更可靠;使用few-shot示例、参考答案、思维链(CoT)或多个裁判组成的“陪审团”可以提高准确性。
-
小样本示例:提供示例辅助模型推理,但会增加上下文长度。
-
加入参考文本:可提升评估准确率。
-
思维链(CoT):让模型先输出推理过程再评分,对旧代模型效果显著。
-
多轮分析:有助于检测事实性错误。
-
陪审团机制:聚合多个评判模型的结果(可用多个小模型替代大模型降低成本,也可调整单一模型温度多次评估),效果优于单模型。
-
提示词添加 “激励表述”:部分场景下可提升正确率,需按需调整。
-
关键任务特殊要求:如医疗领域,需采用人文领域方法 —— 计算标注者间一致性指标、用规范问卷设计方法制定评分标准,降低偏差。
评估你的评估器:
在使用模型裁判前,应将其判断与基线(如人类标注)进行比较,以评估其质量。
- 选基准:对比参照可为人为标注、优质评判模型输出、标准答案等,基准样本无需多(50 个即可),但需具备代表性、区分度、高质量。
- 选指标:二分类 / 两两比对任务可选用准确率、精确率、召回率(易解读);评分类任务的相关性评估较难,文献中常以 0.8 皮尔逊相关系数为理想标准。
- 执行评估:用评判器评估测试样本,再用选定指标对比基准数据,设定可接受阈值(如两两比对任务准确率目标 80%-95%)。
LLM 评判器常见偏差及缓解方法
5.3.2 奖励模型(REWARD MODELS)。
概念:奖励模型学习从人类标注中预测给定提示 - 输出对的分数,以代表人类偏好。训练完成后可作为奖励函数,替代人类判断来优化其他模型。
主流类型与原理
- 布拉德利 - 特里模型(Bradley-Terry):最常见类型,输出两两比对分数,公式为 。训练仅需两两比较数据(比直接打分更易收集),但局限是仅能对比同一提示下的不同输出,无法跨提示比较。
- 进阶两两模型:可预测输出间更细微的优劣概率,但难以跨提示保存和对比分数,且长文本对比受限于上下文长度和内存。
- 绝对分数模型(如 SteerLM):直接输出绝对分数,无需两两比对,评估更便捷;但人类标注绝对分数的稳定性低于两两比较,数据收集难度更高。
- 混合模型(如 HelpSteer2-Preference、ArmoRM):同时输出绝对分数和相对分数,兼顾两种评估方式的优势。
评估使用方法
- 绝对分数模型:直接对模型输出打分,取平均分即可得到汇总结果。
- 相对分数模型:不可直接平均原始分数(易受异常值、不同提示难度差异影响),推荐用两种方式:
1.胜率(win rates):计算模型输出优于参考输出的占比,结果更直观。
2.获胜概率(win probabilities):计算模型输出优于参考输出的平均概率,信号更精细平滑。
- 优缺点:优点是速度快、确定性高、不易受位置偏见影响且无需prompt工程。缺点是需要特定的微调,且当用于强化学习和评估时可能会导致语言模型过拟合奖励模型的偏好。
可在 RewardBench Leaderboard[31]查找高性能模型,参考《Nemotron[32]》论文了解应用案例。
单输出奖励模型可缓存参考模型分数,快速对比新模型性能;训练过程中跟踪胜率 / 获胜概率,可检测模型退化、筛选最优检查点。
5.4 约束模型输出。
- 使用Prompt:
在任务prompt中加入非常具体的格式指令。特点:实现最简单,对高性能模型效果较好,例如《GAIA》论文即采用此方法;但无法保证模型 100% 遵守规则。
- Few Shots和上下文学习:
在prompt中提供示例(few-shot prompting)来引导模型遵循特定格式。2023 年底前整体效果稳定;但受两方面限制 —— 一是近期模型因指令微调、持续预训练,易出现 “测试任务过拟合”,对格式的遵循不再依赖示例;二是推理类模型受推理轨迹干扰,且小样本示例会占用上下文窗口,对小上下文旧模型不友好。
- 结构化文本生成:
通过语法或正则表达式或有限状态机(如outlines库)来约束模型的输出,确保其遵循特定结构。这可以减少prompt方差,使结果更稳定,但有研究表明可能会降低模型在某些任务(如推理)上的性能。
Going further⭐ Understanding how Finite State Machine when using structured generation, by Outlines. Super clear guide on how their method works!https://blog.dottxt.co/coalescence.htmlThe outlines method paper, a more academic explanation of the abovehttps://arxiv.org/abs/2307.09702Interleaved generation, another method to constrain generations for some specific output formatshttps://github.com/guidance-ai/guidance?tab=readme-ov-file#guidance-acceleration
6. Last by not the least
1.统计有效性
核心要求 :报告评估结果时,必须在点估计值之外附上置信区间,以此体现结果的可靠性。
计算方式
- 自动指标:可直接通过分数标准差或自助法(bootstrapping)计算,操作较简单。
模型评判器:需借助校正偏差的估计量来计算置信区间(相关方法已有文献提出)。 - 人工评估:应报告标注者之间的一致性指标,而非单纯的置信区间。
- 补充手段:还可以通过提示词变体计算 —— 用不同表述的同个问题、或不同格式的提示词重新评估相同样本,进一步验证结果稳定性。
2.成本与效率。在设计和报告评估结果时,我们应开始集体报告模型运行成本。一个需要10分钟思考和10K token才能回答简单问题的推理模型,其效率远低于一个用少量token就能快速回答的小模型。建议报告以下内容:
Token消耗:报告评估期间使用的总输出token数,这直接影响金钱成本。
时间:记录模型完成评估所需的推理时间,包括API速率限制等开销。
环境足迹:报告模型训练和推理的碳排放和能源消耗,这取决于模型大小、硬件和生成的token数。
7. 结论
评估既是一门艺术,也是一门科学。本指南探讨了2025年LLM评估的全景——从理解我们为何评估模型、分词和推理的基本机制,到驾驭不断演变的基准生态系统,最终到为特定用例创建评估。
核心要点回顾:
- 1.批判性地思考你正在衡量什么。评估是能力的代理指标,因此在基准测试上的高分不保证在真实世界中的表现。不同的评估方法(自动度量、人类裁判或模型裁判)各有其偏见、局限和权衡。
- 2.使你的评估与你的目标相匹配。如果你在训练期间进行消融实验,请使用即使在小模型上也能提供强信号的快速、可靠的基准。如果你为选择最终模型而进行比较,请专注于更难、未被污染的、测试综合能力的数据集。如果你为特定用例构建,请创建能反映你问题和数据的自定义评估。
- 3.可复现性需要关注细节。在prompt、分词、归一化、模板或随机种子上的微小差异都可能使分数产生几个百分点的波动。报告结果时,要对你的方法论保持透明。
- 4.优先选择可解释的评估方法。在可能的情况下,应选择功能性测试和基于规则的验证器,而不是模型裁判。能够被理解和调试的评估将提供更清晰、更可行的见解。
- 5.评估永无止境。随着模型的改进,基准会饱和。随着训练数据的增长,污染变得更有可能。随着用例的演变,需要衡量新的能力。评估是一场持续的战斗。
总而言之,我们构建的模型的优劣,取决于我们衡量重要事物的能力。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









