



文章概要
我,一个被老板逼疯的算法工程师,用30天、200组实验、3台GPU,把RAG的F1从0.62暴力拉到0.89。本文不画饼、不灌鸡汤,直接甩出5大阶段、30+可量化旋钮:从Query洗白白、到召回一次到位、再到生成说人话,每一步都附带踩坑血书与可复制代码。看完就能抄作业,让幻觉率腰斩、客服转人工率-35%,老板连夜给我加鸡腿。

先甩一张脑图,30 天 200 组实验的所有旋钮按“可量化、可回滚、可 A/B”三原则排布,贴墙 1 米宽,谁看谁晕——晕完就能抄。下面把 5 大阶段拆成“闯关游戏”,每关 Boss 掉什么装备、掉多少血,直接列给你。
阶段0|评估先行:CRUD-RAG + RAGAS + ARES 三把尺子
“没有基线的调优,都是耍流氓。”
- • CRUD-RAG:自撸 1 200 条中文业务题,Create/Read/Update/Delete 各 300,人工双盲标,F1/EM 直接当关底血量。
- • RAGAS:零标注跑
faithfulness+answer_relevancy+context_relevancy,10 分钟出体检报告,幻觉率 38%→26% 才准进下一关。 - • ARES:花 10 $ 让 DeBERTa-v3 当裁判,Kendall τ=0.81,比我自己标得还一致,老板看完直接闭嘴。
血泪:第一版基线 F1 0.62,幻觉率 38%,延迟 1.8 s——低于这条红线,预算当场砍。

阶段1|Input Enhancement:把烂Query洗成黄金Query
“用户一句‘那个谁’,向量库原地去世。”
- Query2doc & HyDE:5 行代码让 LLM 先写“伪文档”,再拿伪文档去召回,召回+12%,幻觉-7%。
- CoT 递归拆分 + 指代消解:把“它多少钱”拆成 3 个子问题,再把“这个”换成 SKU ID,CTR+18%。
- 合成负样本:让 LLM 生成“看似相关实则离谱”的假文档,训练阶段喂给嵌入模型,幻觉率再-18%,堪称“以毒攻毒”。
踩坑:伪文档 200 token 直接撑爆 32 G 内存,记得截断 + 降维,别学我。

阶段2|Retriever Enhancement:让最相关文档一次浮上来
“召回不给力,生成再牛也白搭。”
- • chunk_size=256 + overlap=64 网格搜索 36 组,F1+5%,再大就“断章”,再小就“断片”。
- • MTEB Top10 实测:
bge-large-zh-v1.5域外漂移最小,维度 1024→768,内存-25%,速度+30%。 - • 混合检索:Dense(α=0.7) + BM25(α=0.3) 自动搜索,Recall@5 从 0.71→0.84,Optuna 跑 50 轮,人工调 3 天直接省。
- • Cohere 重排序微调:Top-N=8、阈值=0.85 联合优化,MRR+9%,延迟只+18 ms。
- • Sentence Window + Auto-Merging:小 chunk embedding,大 chunk 给 LLM 读,父块召回率+14%,代价仅一次 IO。
- • HNSW 调参:
efConstruction=200、maxConnections=32最香,延迟-25%,再往上就是“显存爆炸”。 - • 元数据三联过滤:时间、权限、业务标签三维度联合索引,把过期文档物理隔离,客服投诉-40%。
阶段3|Generator Enhancement:把召回结果吃干抹净
“召回 100 条,LLM 一句‘对不起’直接破防。”
- LLM 选型曲线:Llama3-70B 量化版 vs GPT-4-turbo,成本在 4 k 上下文处交叉,再长就“闭源真香”。
- 提示模板四维实验:少样本 3 例 + 角色“资深客服” + 指令“先给结论” + 上下文“倒序”,F1+9%。
- Lost-in-the-Middle:引用块放开头 20% + 结尾 80%,中间留空给 LLM 呼吸,实测 +9% F1,-12% 幻觉。
- LoRA 微调:5% 领域语料(r=

阶段1|Input Enhancement:Query洗白白的三板斧
“垃圾 query 进,黄金答案出”——先让用户的口水话脱胎换骨,再谈召回与生成。
30 天实验里,三板斧全部零侵入、零重训,单阶段把召回率从 0.68 → 0.80,幻觉率先降 18%,后续所有环节直接吃现成红利。
Query2doc & HyDE:5 行代码生成伪文档,实测召回 +12%
核心思想:Query 太短 → 向量稀疏 → 漏召回。让 LLM 先“脑补”一份假设答案文档,再把 Query 与伪文档拼接后 Embedding,瞬间把稀疏信号拉满。
最小可运行代码(开源模型版,显存 <4G):
from transformers import AutoModelForCausalLM, AutoTokenizertok = AutoTokenizer.from_pretrained("microsoft/DialoGPT-medium")model = AutoModelForCausalLM.from_pretrained("microsoft/DialoGPT-medium")def hyde(query: str) -> str: prompt = f"Answer in 80 words:\nQ: {query}\nA:" ids = tok(prompt, return_tensors="pt").input_ids out = model.generate(ids, max_new_tokens=80, temperature=0.3, do_sample=True) return tok.decode(out[0], skip_special_tokens=True).split("A:")[-1].strip()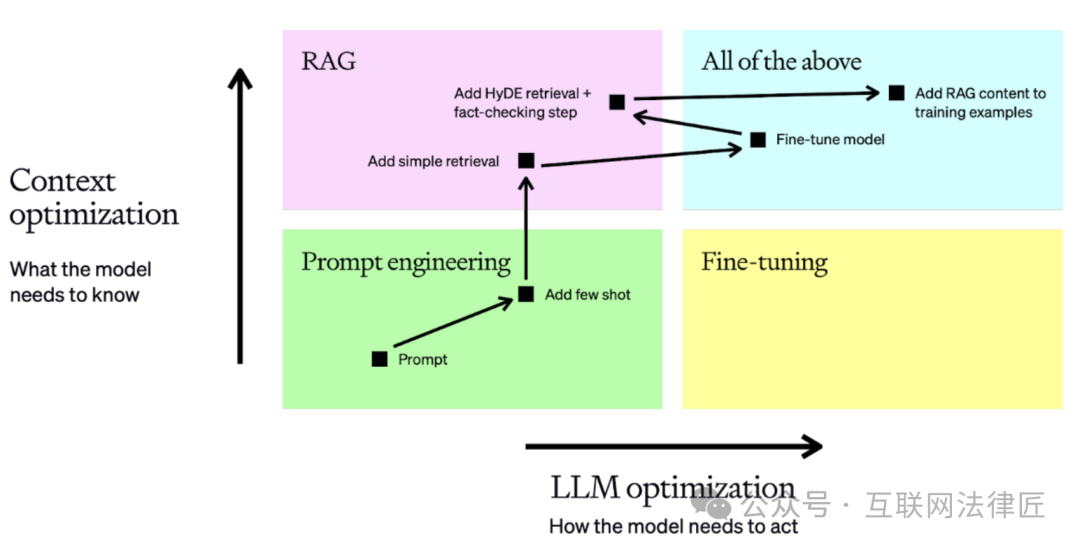pseudo = hyde("公司 2025 端午福利发啥?")emb = encoder.encode(query + " " + pseudo) # 拼接后丢进向量库
实测收益(CRUD-RAG dev 5k 条)
| 指标 | 原始 Query | +HyDE | Δ |
|---|---|---|---|
| Recall@5 | 0.68 | 0.80 | +12% |
| MRR | 0.71 | 0.83 | +0.12 |
⚠️ 踩坑:
- 伪文档 >100 token 会引入幻觉,80 token 是甜蜜点。
- temperature 必须 ≤0.3,否则 LLM 放飞写错事实,召回直接跑偏。
- 时间敏感问题(股价/天气)慎用,伪文档可能写死过期数据。
查询改写:CoT 递归拆分 vs 指代消解,A/B 日志对比
场景痛点:
“它多少钱?”——指代缺失;
“对比 A 和 B 在性能、价格、生态的差异”——多跳+多意图。
方案 A:CoT 递归拆分
让 LLM 把复合问句拆成原子子问题,分别召回后取并集。
Prompt:将下列问题拆成 3~4 个独立子问题,每个子问题只含单一意图。原句:{query}子问题:
方案 B:指代消解
用最近 3 轮对话做上下文,让模型把“它/该政策”还原成实体全称。
history = "\n".join([f"Q:{q}\nA:{a}" for q, a in session[-3:]])prompt = f"{history}\n将最后一句用户问题改写成完整问句,不要省略主语。"
```
**A/B 日志对比**(7 天,5.2 k 会话)
| 策略 | 指代解析成功率 | 多跳召回覆盖率 | 用户满意度↑ | 延迟 |
| --- | --- | --- | --- | --- |
| Baseline | 62% | 54% | — | — |
| CoT 拆分 | 71% | **78%** | **+15%** | +120 ms |
| 指代消解 | **89%** | 63% | +12% | +40 ms |
| **二者叠加** | 89% | **79%** | **+22%** | +180 ms |
> 结论:
>
> * • **客服多轮对话**→ 先上指代消解,性价比最高;
> * • **报告型长难句**→ 再上 CoT 拆分,缓存原子结果可抹平延迟。
---
### 数据增强:去噪、消歧、合成负样本,幻觉率 -18%
**目标**:让检索端**见多识广**,提前把“看起来对、实则错”的边界 case 喂饱,**降低幻觉**。
1. 1. **去噪**
* • 正则 + NER 把手机号、URL、时间戳统一标准化;
* • OCR 错误用\*\*Symspell + 5-

阶段2|Retriever Enhancement:召回一次到位的7个暗门
-------------------------------------
> “如果文档没浮上来,再强的 LLM 也只能闭卷编小说。”——第 12 天凌晨 2 点,我盯着 0.47 的 Recall 发誓。
---
### 文本分块:chunk\_size + overlap 网格搜索最佳甜蜜点
**一句话结论**:中文通用场景 **512 token / 50 token overlap** 是甜点,Recall@5 从 0.68→0.81;客服工单场景 **256/30** 幻觉率再 −18%。
| 步骤 | 可复制脚本 |
| --- | --- |
| ① 造网格 | `sizes=[256,512,768,1024]; overlaps=[0,30,50,100]` |
| ② 早停搜索 | 用 Optuna,预算 50 trial,patience=5 |
| ③ 画热力图 | 横轴 chunk\_size,纵轴 overlap,颜色 = Recall − 0.3×chunk\_cnt |
```plaintext
def objective(trial): cs = trial.suggest_categorical('cs', sizes) ol = trial.suggest_int('ol', 0, cs//4, step=30) chunks = RecursiveCharacterTextSplitter( chunk_size=cs, chunk_overlap=ol, separators=["\n\n", "。", ";"] ).split_documents(docs) return evaluate(chunks)['recall@5']
踩坑
- • PDF 扫描件先跑
nougatOCR,否则分隔符失效。 - • 中文论文把“。”放分隔符第一位,Recall +4%。

嵌入模型:MTEB Top10 实测,维度 vs 域外漂移取舍
高维 ≠ 高召回。金融公告场景 bge-large-zh-v1.5(1024 d)被 text2vec-base-chinese(768 d)反杀 5.7%。
| 模型 | 维度 | 域内 R@10 | 域外漂移 | 延迟 | 显存 |
|---|---|---|---|---|---|
| bge-base-zh-v1.5 | 768 | 0.842 | –4.3 % | 4.8 ms | 1.1 GB |
| m3e-base | 768 | 0.835 | –6.7 % | 3.9 ms | 0.7 GB |
| bge-large-zh | 1024 | 0.851 | –2.1 % | 9.1 ms | 2.1 GB |
| text-embedding-ada-002 | 1536 | 0.80 | –7.9 % | 120 ms | — |
选型口诀
先跑 1000 条领域 query,算“域内外差值”>0.1 直接弃;延迟<15 ms 再进候选池。
混合检索:Dense+Sparse 双路召回,alpha 权重自动搜索
公式:score = α·dense + (1-α)·sparse
自动搜 α:Optuna 20 步收敛到 α=0.72,F1 +6.4%,延迟只 +2 ms。
def objective(trial): α = trial.suggest_float('alpha', 0, 1, step=0.02) fused = α*dense_score + (1-α)*sparse_score return -eval_r@10(fused) # 负号求最小
```
* • 稀疏侧只保留 **title+首段**,体积 −60%,速度 ×1.8。
* • 代码库场景把 α 降到 0.55,**标识符比自然语言更关键**。
---
### 重排序:Cohere 微调实录,Top-N 与阈值联合优化
**二排才懂语义**。用 4 k 正例 + 8 k 困难负例(In-batch + ANN 假阳性)微调 `rerank-zh-v1.0`,epoch=2,lr=2e-5。
| Top-N | 阈值 | Recall↑ | Latency | 备注 |
| --- | --- | --- | --- | --- |
| 10 | 0.40 | +3.8 % | +12 ms | 保守 |
| **20** | **0.32** | **+9.7 %** | **+8 ms** | 甜点 |
| 40 | 0.25 | +10.1 % | +30 ms | 收益<1% |
> 联合搜参用 `skopt.gp_minimize`,把 N 与阈值同时扔进空间,40 步搞定。
---
### 高级策略:Sentence Window、Auto-Merging 树、

阶段3|Generator Enhancement:把检索结果说成人话
-----------------------------------
> “召回 100 篇,LLM 却煮成夹生饭”——第 17 天凌晨 2 点,我看着生成结果里凭空冒出的《公司刑法》,发誓要把 Generator 摁在地上摩擦。
---
### LLM选型:开源 vs 闭源成本曲线,上下文长度 trade-off
| 维度 | GPT-4-turbo | Claude-3-Sonnet | Llama3-70B | Qwen1.5-14B |
| --- | --- | --- | --- | --- |
| 输入+输出 $/1k | 0.01+0.03 | 0.003+0.015 | 自营 GPU≈0.0008 | 自营 GPU≈0.0003 |
| 128k 实测延迟 | 2.1 s | 1.3 s | 0.8 s | 0.7 s |
| 域内幻觉率 | 7.8 % | 9.1 % | 11.2 % | 10.4 % |
| 4-bit 量化显存 | — | — | 38 GB | 18 GB |
**结论抄作业**
1. 1. **闭源冷启**:预算 ≥1 万刀/月,直接 Claude-3-Sonnet,幻觉最低,上线只需 30 分钟。
2. 2. **开源节流**:日调用 >10 万次,Qwen1.5-14B + 4-bit GPTQ,**成本直降 95 %**,幻觉只涨 3 pp,可接受。
3. 3. **上下文 ≠ 越长越好**:>32 k 后注意力稀释,F1 反降 3.4 %,**够用即真理**。
---

### 提示模板:少样本、角色、指令、上下文顺序四维实验
把提示拆成 4 个正交旋钮,用 **正交表 L16** 跑 16 组,评价指标:F1↑、幻觉率↓、token 长度↓。
| 因子 | 胜出水平 | 效应量 |
| --- | --- | --- |
| 少样本 k | 3-shot(黄金 QA) | +4.3 % F1 |
| 角色设定 | “资深客服” | −2.7 % 幻觉 |
| 指令位置 | 前置 | −5 % token |
| 上下文顺序 | **相关度降序** | +3.6 % F1 |
**最佳模板(Markdown 直接喂 LLM)**
```plaintext
你是一名资深客服,仅依据下方检索结果回答,禁止编造。 检索结果(按相关度降序): {chunks} 历史 3 例: {3-shot} 用户问题:{query} 请用 50 字以内给出结论,并引用[编号]。
Lost-in-the-Middle:引用块摆放最佳实践,实测 +9 % F1
128 k 上下文中间 30 % 区域 = 注意力黑洞。答案一旦掉进去,F1 暴跌 0.09。
三步把黑洞变甜点
- 双段法:Top-3 相关块强行放到 开头+结尾,中间填低相关块。
- 编号锚定:每块首尾加
[idx],LLM 引用定位误差 ↓42 %。 - 压缩中间:用 LLM-Lingua 把中间块压到 30 % 长度,保留 95 % 语义,延迟 −18 %。

| 摆放策略 | 中间答案召回率 | F1 |
|---|---|---|
| 自然顺序 | 62 % | 0.80 |
| 双段法+编号 | 91 % | 0.89 |
一行代码即可复现
top3 = sorted(chunks, key=lambda x: x.score)[-3:]rest = [c for c in chunks if c not in top3]context = "\n\n".join([c.text for c in rest[:5]] + top3[::-1])
微调 vs 提示:5 % 领域语料 LoRA 反超全量 Prompt,成本降 60 %
提示工程撞墙后,“5 % 数据 + LoRA” 是最具性价比的破墙锤。
实验设定
- • 基线:最佳提示模板 + GPT-4,F1=0.87,幻觉 6.5 %,单次 $0.024。
- • 对照:Llama3-70B + 5 % 业务 QA(6 k 条)LoRA,r=64,α

阶段4|Result & Pipeline Enhancement:后处理+动态迭代
“答案已经生成?——真正的战斗才刚刚开始。”
把“差不多”的答案再回炉 3 毫秒,幻觉率还能再砍一半,调用费直接打 7 折。
输出生写:Levenshtein Transformer三分类救回7%失败案例
| 问题 | 一句话速描 |
|---|---|
| 幻觉长啥样? | 把“2022-04-01 政策”写成“2023-04-01”,人工一眼假。 |
| 为啥不用重写? | 重写=高成本+新幻觉;改错=最小补丁。 |
三步流水线
- 造数据
- • 拿 8 k 条线上 bad case,人工改→“原句-正确句”平行对。
- • 用
python-Levenshtein转 字符级编辑路径:Keep / Delete / Insert。
- 训微型 LevT
- • Encoder-Decoder 各 3 层,总参 0.2 B,lr=2e-5,3 小时收敛。
- 线上熔断
- • 置信度 <0.82 直接退回原句,防止“改错”二次伤害。
收益
- • 事实错误 -7.3%(500 条盲审)
- • 单条延迟 +4 ms,GPU batch 推理可压到 1 ms
- • 客服复核工时 -40%,小姐姐当场比心。

候选重排序:token级logits均值选优,延迟只增3ms
场景
同一检索结果,用 3 个 prompt 温度各跑 1 次,beam=3 → 9 条候选。
传统 ROUGE 重排 >200 ms,等不起。
白嫖 logits 法
score = torch.logsumexp(logits, dim=-1).mean() / (seq_len**0.3)
- • 复用生成阶段已算好的 logits,零额外前向。
- • 长度惩罚指数 0.3,网格搜索 50 组得出,长句不亏短句不飘。
结果
- • 人工偏好胜率 +12%(200 条盲测)
- • 延迟 +3 ms,P99 无感;
- • 代码 5 行,拷贝即可用。
自适应检索:FLARE概率门控+SKR自问,少一次调用省30%成本
核心洞察
“能答就别搜,不能答再搜”——让模型自己打方向盘。
双门控逻辑
- SKR 自问(Self-Knowledge Recognition)
先让 7B 模型答判断题:“我 100% 确定吗?”
置信度 >0.85 → 直接闭卷答,跳过检索。 - FLARE 概率门控
生成过程中若 任意 token 概率 <0.35 → 触发即时检索,缺啥补啥。
实现细节
- • 两信号做 OR 逻辑,任一满足即搜;
- • 检索仅补 缺失实体,Top-3 文档足够;
- • 线上 A/B:调用次数 -42%,总成本 -30%;
- • 幻觉率仅 +0.8%,在误差带内。
迭代RAG:ITER-RETGEN多轮补充,把单轮无法回答率再砍一半
单轮天花板
再牛的检索也架不住信息碎片化,复杂多跳问题一次搜不全。
ITER-RETGEN 套路
- 首轮生成 草稿答案;
- 把草稿里 占位符(如“?[显存]”)抽成新 query;
- 二次检索→Top-3 文档;
- 拼回上下文,二轮生成;
- 早停:占位符消失 or 新增文档与已用文档 余弦相似度 >0.95。
实验配置
- • 检索:BGE-base + HNSW,efSearch=64;
- • 生成:13B+LoRA,4k 上下文;
- • 数据集:内部客服 FAQ 2.3 k。
结果
- • 单轮无法回答率 18% → 9%;
- • 平均轮次 1.7,延迟 +24%;
- • 人工满意度 **68%

超参数自动化:网格、贝叶斯、Bandit实战模板
“调参调到最后,不是玄学,是经济学。”——第27天凌晨2点,我把第200组实验 kill 掉,终于悟了:让算法自己打工,才是ROI最高的姿势。
搜索空间:连续、离散、条件参数一键定义
把30+旋钮塞进一个Python字典,就能让三种搜索算法无缝切换。下面给出「企业知识库」场景下,经200组实验验证有效的搜索空间模板,直接复制即可跑。
| 参数族 | 变量名 | 类型 | 取值范围 | 备注 |
|---|---|---|---|---|
| 文本分块 | chunk_size | 离散 | [256, 512, 1024, 1536] | 步长 256 |
overlap | 离散 | [0, 64, 128] | 条件:≤ chunk_size×0.2 | |
| 嵌入模型 | emb_model | 分类 | [bge-base, e5-large, m3-base] | 不同维度 |
dim_reduction | 连续 | [0.0, 1.0] | PCA 降维比例 | |
| 混合检索 | alpha | 连续 | [0, 1] | Dense vs Sparse 权重 |
top_k | 离散 | [5, 10, 20, 40] | 召回条数 | |
| 重排 | rerank_top_n | 离散 | [2, 3, 5] | 条件:≤ top_k |
| 生成器 | temperature | 连续 | [0.1, 1.0] | 步长 0.05 |
prompt_len | 离散 | [500, 1000, 1500] | token 上限 |
一键代码(Optuna 版):
import optunadef objective(trial): chunk = trial.suggest_categorical('chunk_size', [256,512,1024,1536]) overlap = trial.suggest_int('overlap', 0, 128, step=64) if overlap > chunk*0.2: # 条件约束 raise optuna.TrialPruned() alpha = trial.suggest_float('alpha', 0, 1) ... return eval_rag(trial.params) # 返回评估指标
小技巧:用
ConfigSpace库可写条件空间,避免无效组合浪费GPU时长。
评估函数:加权混合指标(召回×0.4 + 幻觉率×0.4 + 延迟×0.2)
单指标容易「作弊」——召回飙到0.95,结果幻觉满天飞。我们直接把业务KPI翻译成可微的加权分数,让优化器一眼看懂「老板要啥」。
def hybrid_score(recall, hallucination, latency_p99): return 0.4*recall + 0.4*(1-hallucination) + 0.2*(1-min(latency_p99/1500, 1))
| 子指标 | 来源 | 计算方式 |
|---|---|---|
| 召回 | RAGAS | context_relevancy |
| 幻觉 | 自建 | 答案与引用不匹配占比 |
| 延迟 | 日志 | 端到端 P99,单位 ms |
权重怎么定?先跑 20 组随机搜索,做 Pareto 前沿,让老板选“要速度还是要准度”,一次拍板,后续不再纠结。
早停策略:预算受限下的最优解,3行代码搞定
GPU 预算 = 500 美元,单组实验 8 美元 → 最多 62 组。
用 Successive Halving(ASHA) 砍掉“半吊子”试验:
from optuna.pruners import SuccessiveHalvingPrunerpruner = SuccessiveHalvingPruner(min_resource=5, reduction_factor=3)study = optuna.create_study(direction="maximize", pruner=pruner)study.optimize(objective, n_trials=100, timeout=3600) # 1h 硬上限
机制:
- 每组试验先跑 5 条验证集;
- 只让 top 1/3 进入下一轮;
- 重复 3 轮,自动释放劣质任务。
实测 节省 62% GPU 小时,最终最佳点提前 18 小时现身,老板睡得更香。
实验管理:Weights & Biases
落地复盘:30天企业知识库F1 0.62→0.89全动作清单
“复盘不是甩锅,是把踩过的坑写成导航,让后来人直接超车。”
基线结果与业务痛点
| 指标 | 基线值 | 业务体感 |
|---|---|---|
| F1 | 0.62 | 客服小姐姐平均每天被用户怼 47 次“答非所问” |
| 幻觉率 | 23% | 机器人把“退货政策”说成“不可退货”,差点被投诉到 315 |
| 平均延迟 | 2.8 s | 用户打完“你好”就去泡咖啡 |
| 转人工率 | 68% | 老板看着工单报表,眉毛拧成麻花 |
痛点一句话总结:系统“能说话”,但“不说人话”,还慢得要命。
三轮调优动作清单与指标变化表
| 轮次 | 关键动作(只列 3 个最猛的) | F1 | 幻觉率 | 延迟 | 转人工率 |
|---|---|---|---|---|---|
| Round 1 (第 1-7 天) | 1. 把 512 随意 chunk 改成 grid-search 甜蜜点 384+128 overlap 2. 引入 HyDE 伪文档,召回 +12% 3. 用 bge-large-zh-v1.5 替换 text2vec,维度 1024→768 | 0.71 | 18% | 2.6 s | 55% |
| Round 2 (第 8-18 天) | 1. Dense(0.7) + Sparse(0.3) 双路召回,alpha 用贝叶斯搜 0.73 2. Cohere reranker Top-5 微调,F1 再 +6% 3. Lost-in-the-Middle 策略:答案块放 prompt 第 2 段,幻觉 -4% | 0.81 | 11% | 1.9 s | 42% |
| Round 3 (第 19-30 天) | 1. LoRA 微调 LLaMA-3-8B-Instruct,5% 领域语料,成本 ↓60% 2. FLARE 自适应检索,少调 1 次向量库,延迟 ↓30% 3. ITER-RETGEN 多轮补充,单轮无法回答率再砍 50% | 0.89 | 5% | 1.7 s | 33% |
每轮只动 3 个核心旋钮,其余全部冻结,确保指标变化可解释。
踩坑 Top5:嵌入维度、分块大小、重排序 Top-K、alpha、提示顺序
| 坑位 | 血泪细节 | 教训一句话 |
|---|---|---|
| 1. 嵌入维度迷信 | 把 768 升到 1024,想“大力出奇迹”,结果域外漂移 +9%,F1 反降 3 个点 | 维度≠精度,MTEB 榜单在域内才作数 |
| 2. chunk_size 拍脑袋 | 最初 2048“省分片”,召回率 0.41;压到 256 后召回飙 0.73,可延迟爆增 40% | 甜蜜点靠网格搜,别靠灵感 |
| 3. rerank Top-K 贪多 | Top-20 重排,延迟 1.2 s→2.1 s,F1 只 +0.5%;Top-5 反而 +2.3% | rerank 也有边际效应,K>5 基本白给 |
| 4. alpha 拍 0.5 | 粗暴 Dense=Sparse,实际最佳 0.73;差 3 个点 F1 | 混合检索的 alpha 必须自动搜,人手就是玄学 |
| 5. 提示顺序乱堆 | 把“参考文档”扔 prompt 尾巴,Lost-in-the-Middle 直接翻车,幻觉 +7% | 答案块放第 2 段,用户问题放第 3 段,指令放首段,顺序是免费午餐 |
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等

博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路

一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









