



背景
最近,公司的一个项目经理找我聊了个头疼的问题:他们给外部交付的项目POC效果不太理想,他发现从向量库中检索不到想要的信息。起初,我建议他换个更好的embedding模型,别再用text-embedding-ada-002了。结果他反馈说,试了text-embedding-3-large和bge-m3,效果也没啥显著提升。
我仔细看了他们的数据,发现他们上传了大量用户的文档,并对文档进行了切分,分成一个个chunk,然后召回这些chunk送给LLM生成回答。问题就在于他们切分chunk的方式用的是RecursiveCharacterTextSplitter,单独看一个切分后的chunk,根本不知道它在讲什么。比如,有个chunk提到了opening hours,但因为递归切分的原因,缺少了主体信息。结果,即使召回了这个chunk,LLM也会回复“从提供的上下文中无法找到答案”。
我给了他一个建议:可以试试contextual-embedding。引入这个方案不需要太多开发成本,而且配合prompt cache,还能有效减少LLM调用的开销。
什么是contextual embedding
在传统的RAG中,文档通常被分成更小的块以进行有效的检索。虽然这种方法对于许多应用程序都很有效,但当单个块缺乏足够的上下文时,它可能会导致问题。Contextual Embedding 通过使用LLM给每段chunk补充上下文信息,用户更精准召回和更高质量的回答。
举个简单的例子,比如有段chunk的内容如下:
The company's revenue grew by 3% over the previous quarter.
当我们提问:“What was the revenue growth for ACME Corp in Q2 2023?”,虽然这段chunk是真实答案,但是却检索不到。这是因为原始chunk,是两个"The"对象,导致不管使用embedding还是BM25都抓不出来它。但是如果我们通过某种手段,给转换成下面这种contextualized_chunk,把上下文信息给注入到chunk里:
This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter.
那么还是刚才的问题,就一问一个准了。
原理
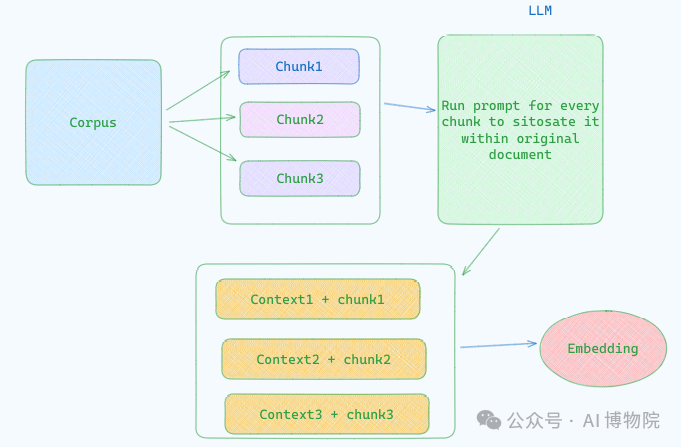
我们通过一个特定的提示生成每个分块的简洁上下文,生成的上下文通常为 50-100 个 token,然后 索引之前将其添加到分块中。对应的prompt示例:
system prompt
Here is the whole document:
<document>
{{WHOLE_DOCUMENT}}
</document>
user prompt
Here is the chunk we want to situate within the whole document:
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
实战案例
这里我们还是以sentosa的一个网页为例:https://www.sentosa.com.sg/en/places-to-stay/amara-sanctuary-sentosa/。
从这个网页中,我们切分出了一段chunk,内容如下:
description: Bed: King
Room Size: 37 sqm
Maximum Occupants: 2 Adults or 2 Adults and 1 child age 11 and below
Room Essentials
Flat-screen TV with cable channel access
Individually controlled air-conditioning
Spacious bathroom with separate bathtub and shower facilities
Luxury bathroom amenities
Bathrobes and hair dryer
Electronic safe
Tea and coffee making facilities
Iron and ironing board
Baby cot is available on request (subject to availability)
name: Couple Suite
name: Courtyard Suite
name: Junior Suite
name: Verandah Suite
Opening Hours:
Check in: from 3pm
Check out: until 12pm
单独看这段chunk,我们只能看出它在描述一些房间信息,但具体是哪些房间的信息,却并不清楚。于是,我们使用gpt-4o-mini为这段chunk生成了上下文,结果如下:
This chunk provides detailed information about the room types and amenities available at Amara Sanctuary Sentosa, including the Deluxe Room specifications, other suite options, opening hours, accessibility features, and pet-friendly services, enhancing the overall description of the resort's accommodations.
接下来,我们将原始的chunk和生成的上下文结合起来(使用\n\n 连接chunk),形成一个新的chunk:
description: Bed: King
Room Size: 37 sqm
Maximum Occupants: 2 Adults or 2 Adults and 1 child age 11 and below
Room Essentials
Flat-screen TV with cable channel access
Individually controlled air-conditioning
Spacious bathroom with separate bathtub and shower facilities
Luxury bathroom amenities
Bathrobes and hair dryer
Electronic safe
Tea and coffee making facilities
Iron and ironing board
Baby cot is available on request (subject to availability)
name: Couple Suite
name: Courtyard Suite
name: Junior Suite
name: Verandah Suite
Opening Hours:
Check in: from 3pm
Check out: until 12pm
This chunk provides detailed information about the room types and amenities available at Amara Sanctuary Sentosa, including the Deluxe Room specifications, other suite options, opening hours, accessibility features, and pet-friendly services, enhancing the overall description of the resort's accommodations.
这样一来,当我们再询问关于“Amara Sanctuary Sentosa的Deluxe Room”相关问题时,LLM就能准确回答上来了。这种方法不仅提升了信息的连贯性,还大大减少了LLM的误判率。
prompt cache
对于OpenAI模型,当你的提示(prompt)长度超过1,024个token时,API调用将自动受益于Prompt Caching功能。(deepseek也支持prompt cache)如果你重复使用具有相同前缀的提示,系统会自动应用Prompt Caching折扣,而你无需对API集成做任何修改。缓存通常在5-10分钟的不活动后被清除,并且无论如何都会在最后一次使用后的一小时内被移除。
当我们对某个文档进行切分,生成多个chunk时,通常需要为每个chunk生成上下文信息。如果每次调用都传入全部文档信息,会导致重复计算,增加LLM的调用成本。这时,我们可以将全部文档信息放在system prompt中,利用Prompt Cache来节省费用。
以下是我调用LLM的Response中的usage字段,展示了Prompt Cache的实际效果:
CompletionUsage(
completion_tokens=24,
prompt_tokens=1584,
total_tokens=1608,
completion_tokens_details=CompletionTokensDetails(
accepted_prediction_tokens=0,
audio_tokens=0,
reasoning_tokens=0,
rejected_prediction_tokens=0
),
prompt_tokens_details=PromptTokensDetails(
audio_tokens=0,
cached_tokens=1536 # 这里显示有1,536个token被缓存
)
)
从上面的数据可以看出:
- prompt_tokens: 1,584个token被用于提示。
- cached_tokens: 1,536个token被缓存,这意味着这部分token的计算成本被节省了下来。
- completion_tokens: 24个token用于生成回答。
通过将文档信息放在system prompt中,我们成功利用Prompt Cache减少了重复计算,显著降低了LLM的调用成本。
总结
传统的文档切分方法(如RecursiveCharacterTextSplitter)可能会导致chunk缺乏足够的上下文信息,从而影响检索效果。通过引入Contextual Embedding,我们能够为每个chunk补充上下文信息,显著提升检索的精准度和回答的质量。
总的来说,Contextual Embedding和Prompt Cache的结合,为RAG系统提供了一种低成本、高效率的优化方案。尤其是在项目时间紧张、资源有限的情况下,这种方案能够快速提升系统的表现。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 282
282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









