







目录
- 1.TopicCommand
- 2.ConfigCommand
- 3.副本扩缩、分区迁移、跨路径迁移 kafka-reassign-partitions
- 4.Topic的发送kafka-console-producer.sh
- 5. Topic的消费kafka-console-consumer.sh
- 6.kafka-leader-election Leader重新选举
- 7. 持续批量推送消息kafka-verifiable-producer.sh
- 8. 持续批量拉取消息kafka-verifiable-consumer
- 9.生产者压力测试kafka-producer-perf-test.sh
- 10.消费者压力测试kafka-consumer-perf-test.sh
- 11.删除指定分区的消息kafka-delete-records.sh
- 12. 查看Broker磁盘信息
- 12. 消费者组管理 kafka-consumer-groups.sh
- 附件
1.TopicCommand
1.1.Topic创建
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3 --topic test
相关可选参数
| 参数 | 描述 | 例子 |
|---|---|---|
--bootstrap-server 指定kafka服务 | 指定连接到的kafka服务; 如果有这个参数,则 --zookeeper可以不需要 | –bootstrap-server localhost:9092 |
--zookeeper | 弃用, 通过zk的连接方式连接到kafka集群; | –zookeeper localhost:2181 或者localhost:2181/kafka |
--replication-factor | 副本数量,注意不能大于broker数量;如果不提供,则会用集群中默认配置 | –replication-factor 3 |
--partitions | 分区数量,当创建或者修改topic的时候,用这个来指定分区数;如果创建的时候没有提供参数,则用集群中默认值; 注意如果是修改的时候,分区比之前小会有问题 | –partitions 3 |
--replica-assignment | 副本分区分配方式;创建topic的时候可以自己指定副本分配情况; | --replica-assignment BrokerId-0:BrokerId-1:BrokerId-2,BrokerId-1:BrokerId-2:BrokerId-0,BrokerId-2:BrokerId-1:BrokerId-0 ; 这个意思是有三个分区和三个副本,对应分配的Broker; 逗号隔开标识分区;冒号隔开表示副本 |
--config<String: name=value> | 用来设置topic级别的配置以覆盖默认配置;只在–create 和–bootstrap-server 同时使用时候生效; 可以配置的参数列表请看文末附件 | 例如覆盖两个配置 --config retention.bytes=123455 --config retention.ms=600001 |
--command-config <String: command 文件路径> | 用来配置客户端Admin Client启动配置,只在–bootstrap-server 同时使用时候生效; | 例如:设置请求的超时时间 --command-config config/producer.proterties; 然后在文件中配置 request.timeout.ms=300000 |
1.2.删除Topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic test
支持正则表达式匹配Topic来进行删除,只需要将topic 用双引号包裹起来 例如: 删除以create_topic_byhand_zk为开头的topic;
bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic “create_topic_byhand_zk.*”
.表示任意匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 . 。·*·:匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 *。.*: 任意字符
删除任意Topic (慎用)
bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic “.*?”
更多的用法请参考正则表达式
1.3.Topic分区扩容
zk方式(不推荐)
>bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic1 --partitions 2
kafka版本 >= 2.2 支持下面方式(推荐)
单个Topic扩容
bin/kafka-topics.sh --bootstrap-server broker_host:port --alter --topic test_create_topic1 --partitions 4
批量扩容 (将所有正则表达式匹配到的Topic分区扩容到4个)
sh bin/kafka-topics.sh --topic ".*?" --bootstrap-server 172.23.248.85:9092 --alter --partitions 4
".*?" 正则表达式的意思是匹配所有; 您可按需匹配
PS: 当某个Topic的分区少于指定的分区数时候,他会抛出异常;但是不会影响其他Topic正常进行;
相关可选参数 | 参数 |描述 |例子| |–|–|–| |--replica-assignment|副本分区分配方式;创建topic的时候可以自己指定副本分配情况; |--replica-assignment BrokerId-0:BrokerId-1:BrokerId-2,BrokerId-1:BrokerId-2:BrokerId-0,BrokerId-2:BrokerId-1:BrokerId-0 ; 这个意思是有三个分区和三个副本,对应分配的Broker; 逗号隔开标识分区;冒号隔开表示副本|
PS: 虽然这里配置的是全部的分区副本分配配置,但是正在生效的是新增的分区; 比如: 以前3分区1副本是这样的
| Broker-1 | Broker-2 | Broker-3 | Broker-4 |
|---|---|---|---|
| 0 | 1 | 2 |
现在新增一个分区,--replica-assignment 2,1,3,4 ; 看这个意思好像是把0,1号分区互相换个Broker
| Broker-1 | Broker-2 | Broker-3 | Broker-4 |
|---|---|---|---|
| 1 | 0 | 2 | 3 |
但是实际上不会这样做,Controller在处理的时候会把前面3个截掉; 只取新增的分区分配方式,原来的还是不会变
| Broker-1 | Broker-2 | Broker-3 | Broker-4 |
|---|---|---|---|
| 0 | 1 | 2 | 3 |
1.4.查询Topic描述
1.查询单个Topic
sh bin/kafka-topics.sh --topic test --bootstrap-server xxxx:9092 --describe --exclude-internal
2.批量查询Topic(正则表达式匹配,下面是查询所有Topic)
sh bin/kafka-topics.sh --topic ".*?" --bootstrap-server xxxx:9092 --describe --exclude-internal
支持正则表达式匹配Topic,只需要将topic 用双引号包裹起来
相关可选参数
| 参数 | 描述 | 例子 |
|---|---|---|
--bootstrap-server 指定kafka服务 | 指定连接到的kafka服务; 如果有这个参数,则 --zookeeper可以不需要 | –bootstrap-server localhost:9092 |
--at-min-isr-partitions | 查询的时候省略一些计数和配置信息 | --at-min-isr-partitions |
--exclude-internal | 排除kafka内部topic,比如__consumer_offsets-* | --exclude-internal |
--topics-with-overrides | 仅显示已覆盖配置的主题,也就是单独针对Topic设置的配置覆盖默认配置;不展示分区信息 | --topics-with-overrides |
5.查询Topic列表
1.查询所有Topic列表
sh bin/kafka-topics.sh --bootstrap-server xxxxxx:9092 --list --exclude-internal
2.查询匹配Topic列表(正则表达式)
查询
test_create_开头的所有Topic列表sh bin/kafka-topics.sh --bootstrap-server xxxxxx:9092 --list --exclude-internal --topic "test_create_.*"
相关可选参数
| 参数 | 描述 | 例子 |
|---|---|---|
--exclude-internal | 排除kafka内部topic,比如__consumer_offsets-* | --exclude-internal |
--topic | 可以正则表达式进行匹配,展示topic名称 | --topic |
2.ConfigCommand
Config相关操作; 动态配置可以覆盖默认的静态配置;
2.1 查询配置
Topic配置查询
展示关于Topic的动静态配置
1.查询单个Topic配置(只列举动态配置)
sh bin/kafka-configs.sh --describe --bootstrap-server xxxxx:9092 --topic test_create_topic或者sh bin/kafka-configs.sh --describe --bootstrap-server 172.23.248.85:9092 --entity-type topics --entity-name test_create_topic
2.查询所有Topic配置(包括内部Topic)(只列举动态配置)
sh bin/kafka-configs.sh --describe --bootstrap-server 172.23.248.85:9092 --entity-type topics
3.查询Topic的详细配置(动态+静态)
只需要加上一个参数
--all
其他配置/clients/users/brokers/broker-loggers 的查询
同理 ;只需要将
--entity-type改成对应的类型就行了 (topics/clients/users/brokers/broker-loggers)
查询kafka版本信息
sh bin/kafka-configs.sh --describe --bootstrap-server xxxx:9092 --version
所有可配置的动态配置 请看最后面的 *附件* 部分
2.2 增删改 配置 --alter
–alter
删除配置: --delete-config k1=v1,k2=v2 添加/修改配置: --add-config k1,k2 选择类型: --entity-type (topics/clients/users/brokers/broker- loggers) 类型名称: --entity-name
Topic添加/修改动态配置
--add-config
sh bin/kafka-configs.sh --bootstrap-server xxxxx:9092 --alter --entity-type topics --entity-name test_create_topic1 --add-config file.delete.delay.ms=222222,retention.ms=999999
Topic删除动态配置
--delete-config
sh bin/kafka-configs.sh --bootstrap-server xxxxx:9092 --alter --entity-type topics --entity-name test_create_topic1 --delete-config file.delete.delay.ms,retention.ms
其他配置同理,只需要类型改下--entity-type
类型有: (topics/clients/users/brokers/broker- loggers)
哪些配置可以修改 请看最后面的附件:ConfigCommand 的一些可选配置
3.副本扩缩、分区迁移、跨路径迁移 kafka-reassign-partitions
请戳 【kafka运维】副本扩缩容、数据迁移、副本重分配、副本跨路径迁移 (如果点不出来,表示文章暂未发表,请耐心等待)
(3.1)脚本的使用介绍
关键参数--generate
1=》构造文件
cd /data/kafka
vim move.json

{
"topics": \[
{"topic": "test"}
\],
"version": 1
}

运行 generate 参数生成 当前副本的配置介绍 json,以及建议修改的 json

kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file ./move.json --broker-list "0,1,2" --generate
Current partition replica assignment
{"version":1,"partitions":\[{"topic":"test","partition":0,"replicas":\[1,0,2\],"log\_dirs":\["any","any","any"\]},{"topic":"test","partition":1,"replicas":\[0,2,1\],"log\_dirs":\["any","any","any"\]},{"topic":"test","partition":2,"replicas":\[2,1,0\],"log\_dirs":\["any","any","any"\]}\]}
Proposed partition reassignment configuration
{"version":1,"partitions":\[{"topic":"test","partition":0,"replicas":\[1,0,2\],"log\_dirs":\["any","any","any"\]},{"topic":"test","partition":1,"replicas":\[2,1,0\],"log\_dirs":\["any","any","any"\]},{"topic":"test","partition":2,"replicas":\[0,2,1\],"log\_dirs":\["any","any","any"\]}\]}

我找json 在线格式化看看
JSON在线 | JSON解析格式化—SO JSON在线工具
对比一下发现,partition 1 和 2 的replicas 不一样了;

4.Topic的发送kafka-console-producer.sh
4.1 生产无key消息
## 生产者
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test --producer.config config/producer.properties
4.2 生产有key消息 加上属性--property parse.key=true
## 生产者
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test --producer.config config/producer.properties --property parse.key=true
默认消息key与消息value间使用“Tab键”进行分隔,所以消息key以及value中切勿使用转义字符(\t)
可选参数
| 参数 | 值类型 | 说明 | 有效值 |
|---|---|---|---|
| –bootstrap-server | String | 要连接的服务器必需(除非指定–broker-list) | 如:host1:prot1,host2:prot2 |
| –topic | String | (必需)接收消息的主题名称 | |
| –batch-size | Integer | 单个批处理中发送的消息数 | 200(默认值) |
| –compression-codec | String | 压缩编解码器 | none、gzip(默认值)snappy、lz4、zstd |
| –max-block-ms | Long | 在发送请求期间,生产者将阻止的最长时间 | 60000(默认值) |
| –max-memory-bytes | Long | 生产者用来缓冲等待发送到服务器的总内存 | 33554432(默认值) |
| –max-partition-memory-bytes | Long | 为分区分配的缓冲区大小 | 16384 |
| –message-send-max-retries | Integer | 最大的重试发送次数 | 3 |
| –metadata-expiry-ms | Long | 强制更新元数据的时间阈值(ms) | 300000 |
| –producer-property | String | 将自定义属性传递给生成器的机制 | 如:key=value |
| –producer.config | String | 生产者配置属性文件[–producer-property]优先于此配置 配置文件完整路径 | |
| –property | String | 自定义消息读取器 | parse.key=true/false key.separator=<key.separator>ignore.error=true/false |
| –request-required-acks | String | 生产者请求的确认方式 | 0、1(默认值)、all |
| –request-timeout-ms | Integer | 生产者请求的确认超时时间 | 1500(默认值) |
| –retry-backoff-ms | Integer | 生产者重试前,刷新元数据的等待时间阈值 | 100(默认值) |
| –socket-buffer-size | Integer | TCP接收缓冲大小 | 102400(默认值) |
| –timeout | Integer | 消息排队异步等待处理的时间阈值 | 1000(默认值) |
| –sync | 同步发送消息 | ||
| –version | 显示 Kafka 版本 | 不配合其他参数时,显示为本地Kafka版本 | |
| –help | 打印帮助信息 |
5. Topic的消费kafka-console-consumer.sh
1. 新客户端从头消费--from-beginning (注意这里是新客户端,如果之前已经消费过了是不会从头消费的) 下面没有指定客户端名称,所以每次执行都是新客户端都会从头消费
sh bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
2. 正则表达式匹配topic进行消费--whitelist 消费所有的topic
sh bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --whitelist ‘.*’
消费所有的topic,并且还从头消费
sh bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --whitelist ‘.*’ --from-beginning
3.显示key进行消费--property print.key=true
sh bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --property print.key=true
4. 指定分区消费--partition 指定起始偏移量消费--offset
sh bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --partition 0 --offset 100
5. 给客户端命名--group
注意给客户端命名之后,如果之前有过消费,那么--from-beginning就不会再从头消费了
sh bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --group test-group
6. 添加客户端属性--consumer-property
这个参数也可以给客户端添加属性,但是注意 不能多个地方配置同一个属性,他们是互斥的;比如在下面的基础上还加上属性--group test-group 那肯定不行
sh bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
--consumer-property group.id=test-consumer-group
7. 添加客户端属性--consumer.config
跟--consumer-property 一样的性质,都是添加客户端的属性,不过这里是指定一个文件,把属性写在文件里面, --consumer-property 的优先级大于 --consumer.config
sh bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --consumer.config config/consumer.properties
| 参数 | 描述 | 例子 |
|---|---|---|
--group | 指定消费者所属组的ID | |
--topic | 被消费的topic | |
--partition | 指定分区 ;除非指定–offset,否则从分区结束(latest)开始消费 | --partition 0 |
--offset | 执行消费的起始offset位置 ;默认值: latest; /latest /earliest /偏移量 | --offset 10 |
--whitelist | 正则表达式匹配topic;--topic就不用指定了; 匹配到的所有topic都会消费; 当然用了这个参数,--partition --offset等就不能使用了 | |
--consumer-property | 将用户定义的属性以key=value的形式传递给使用者 | --consumer-propertygroup.id=test-consumer-group |
--consumer.config | 消费者配置属性文件请注意,[consumer-property]优先于此配置 | --consumer.config config/consumer.properties |
--property | 初始化消息格式化程序的属性 | print.timestamp=true,false 、print.key=true,false 、print.value=true,false 、key.separator=<key.separator> 、line.separator=<line.separator>、key.deserializer=<key.deserializer>、value.deserializer=<value.deserializer> |
--from-beginning | 从存在的最早消息开始,而不是从最新消息开始,注意如果配置了客户端名称并且之前消费过,那就不会从头消费了 | |
--max-messages | 消费的最大数据量,若不指定,则持续消费下去 | --max-messages 100 |
--skip-message-on-error | 如果处理消息时出错,请跳过它而不是暂停 | |
--isolation-level | 设置为read_committed以过滤掉未提交的事务性消息,设置为read_uncommitted以读取所有消息,默认值:read_uncommitted | |
--formatter | kafka.tools.DefaultMessageFormatter、kafka.tools.LoggingMessageFormatter、kafka.tools.NoOpMessageFormatter、kafka.tools.ChecksumMessageFormatter |
6.kafka-leader-election Leader重新选举
6.1 指定Topic指定分区用重新PREFERRED:优先副本策略 进行Leader重选举
> sh bin/kafka-leader-election.sh --bootstrap-server xxxx:9090 --topic test_create_topic4 --election-type PREFERRED --partition 0
6.2 所有Topic所有分区用重新PREFERRED:优先副本策略 进行Leader重选举
sh bin/kafka-leader-election.sh --bootstrap-server xxxx:9090 --election-type preferred --all-topic-partitions
6.3 设置配置文件批量指定topic和分区进行Leader重选举
先配置leader-election.json文件
{
"partitions": [
{
"topic": "test_create_topic4",
"partition": 1
},
{
"topic": "test_create_topic4",
"partition": 2
}
]
}
sh bin/kafka-leader-election.sh --bootstrap-server xxx:9090 --election-type preferred --path-to-json-file config/leader-election.json
相关可选参数
| 参数 | 描述 | 例子 |
|---|---|---|
--bootstrap-server 指定kafka服务 | 指定连接到的kafka服务 | –bootstrap-server localhost:9092 |
--topic | 指定Topic,此参数跟--all-topic-partitions和path-to-json-file 三者互斥 | |
--partition | 指定分区,跟--topic搭配使用 | |
--election-type | 两个选举策略(PREFERRED:优先副本选举,如果第一个副本不在线的话会失败;UNCLEAN: 策略) | |
--all-topic-partitions | 所有topic所有分区执行Leader重选举; 此参数跟--topic和path-to-json-file 三者互斥 | |
--path-to-json-file | 配置文件批量选举,此参数跟--topic和all-topic-partitions 三者互斥 |
7. 持续批量推送消息kafka-verifiable-producer.sh
单次发送100条消息--max-messages 100
一共要推送多少条,默认为-1,-1表示一直推送到进程关闭位置
sh bin/kafka-verifiable-producer.sh --topic test_create_topic4 --bootstrap-server localhost:9092
--max-messages 100
每秒发送最大吞吐量不超过消息 --throughput 100
推送消息时的吞吐量,单位messages/sec。默认为-1,表示没有限制
sh bin/kafka-verifiable-producer.sh --topic test_create_topic4 --bootstrap-server localhost:9092
--throughput 100
发送的消息体带前缀--value-prefix
sh bin/kafka-verifiable-producer.sh --topic test_create_topic4 --bootstrap-server localhost:9092
--value-prefix 666
注意--value-prefix 666必须是整数,发送的消息体的格式是加上一个 点号. 例如: 666.
其他参数: --producer.config CONFIG_FILE 指定producer的配置文件 --acks ACKS 每次推送消息的ack值,默认是-1
8. 持续批量拉取消息kafka-verifiable-consumer
持续消费
sh bin/kafka-verifiable-consumer.sh --group-id test_consumer --bootstrap-server localhost:9092 --topic test_create_topic4
单次最大消费10条消息--max-messages 10
sh bin/kafka-verifiable-consumer.sh --group-id test_consumer --bootstrap-server localhost:9092 --topic test_create_topic4
--max-messages 10
相关可选参数
| 参数 | 描述 | 例子 |
|---|---|---|
--bootstrap-server 指定kafka服务 | 指定连接到的kafka服务; | –bootstrap-server localhost:9092 |
--topic | 指定消费的topic | |
--group-id | 消费者id;不指定的话每次都是新的组id | |
group-instance-id | 消费组实例ID,唯一值 | |
--max-messages | 单次最大消费的消息数量 | |
--enable-autocommit | 是否开启offset自动提交;默认为false | |
--reset-policy | 当以前没有消费记录时,选择要拉取offset的策略,可以是earliest, latest,none。默认是earliest | |
--assignment-strategy | consumer分配分区策略,默认是org.apache.kafka.clients.consumer.RangeAssignor | |
--consumer.config | 指定consumer的配置文件 |
9.生产者压力测试kafka-producer-perf-test.sh
1. 发送1024条消息--num-records 100并且每条消息大小为1KB--record-size 1024 最大吞吐量每秒10000条--throughput 100
sh bin/kafka-producer-perf-test.sh --topic test_create_topic4 --num-records 100 --throughput 100000 --producer-props bootstrap.servers=localhost:9092 --record-size 1024
你可以通过LogIKM查看分区是否增加了对应的数据大小

从LogIKM 可以看到发送了1024条消息; 并且总数据量=1M; 1024条*1024byte = 1M;
2. 用指定消息文件--payload-file发送100条消息最大吞吐量每秒100条--throughput 100
-
先配置好消息文件
batchmessage.txt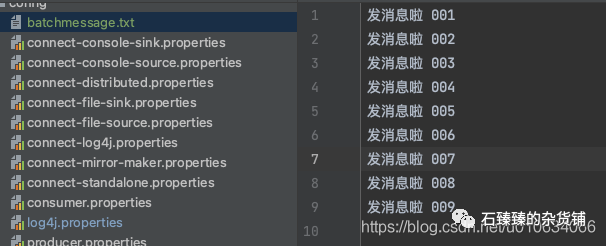
-
然后执行命令 发送的消息会从
batchmessage.txt里面随机选择; 注意这里我们没有用参数--payload-delimeter指定分隔符,默认分隔符是\n换行;bin/kafka-producer-perf-test.sh --topic test_create_topic4 --num-records 100 --throughput 100 --producer-props bootstrap.servers=localhost:9090 --payload-file config/batchmessage.txt
-
验证消息,可以通过 LogIKM 查看发送的消息
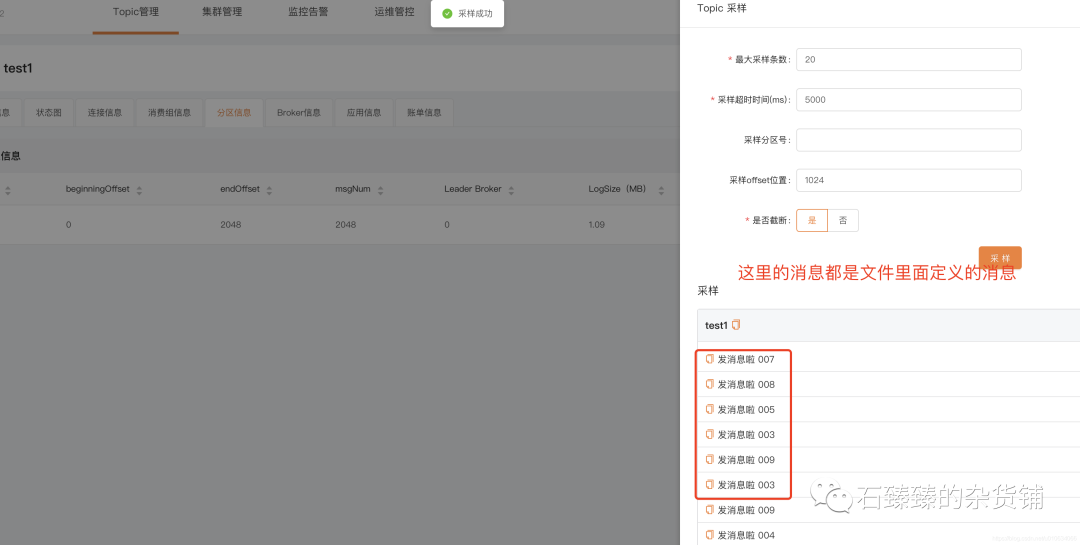
相关可选参数
| 参数 | 描述 | 例子 |
|---|---|---|
--topic | 指定消费的topic | |
--num-records | 发送多少条消息 | |
--throughput | 每秒消息最大吞吐量 | |
--producer-props | 生产者配置, k1=v1,k2=v2 | --producer-props bootstrap.servers= localhost:9092,client.id=test_client |
--producer.config | 生产者配置文件 | --producer.config config/producer.propeties |
--print-metrics | 在test结束的时候打印监控信息,默认false | --print-metrics true |
--transactional-id | 指定事务 ID,测试并发事务的性能时需要,只有在 --transaction-duration-ms > 0 时生效,默认值为 performance-producer-default-transactional-id | |
--transaction-duration-ms | 指定事务持续的最长时间,超过这段时间后就会调用 commitTransaction 来提交事务,只有指定了 > 0 的值才会开启事务,默认值为 0 | |
--record-size | 一条消息的大小byte; 和 --payload-file 两个中必须指定一个,但不能同时指定 | |
--payload-file | 指定消息的来源文件,只支持 UTF-8 编码的文本文件,文件的消息分隔符通过 --payload-delimeter指定,默认是用换行\nl来分割的,和 --record-size 两个中必须指定一个,但不能同时指定 ; 如果提供的消息 | |
--payload-delimeter | 如果通过 --payload-file 指定了从文件中获取消息内容,那么这个参数的意义是指定文件的消息分隔符,默认值为 \n,即文件的每一行视为一条消息;如果未指定--payload-file则此参数不生效;发送消息的时候是随机送文件里面选择消息发送的; |
10.消费者压力测试kafka-consumer-perf-test.sh
消费100条消息--messages 100
sh bin/kafka-consumer-perf-test.sh -topic test_create_topic4 --bootstrap-server localhost:9090 --messages 100
相关可选参数
| 参数 | 描述 | 例子 |
|---|---|---|
--bootstrap-server | ||
--consumer.config | 消费者配置文件 | |
--date-format | 结果打印出来的时间格式化 | 默认:yyyy-MM-dd HH:mm:ss:SSS |
--fetch-size | 单次请求获取数据的大小 | 默认1048576 |
--topic | 指定消费的topic | |
--from-latest | ||
--group | 消费组ID | |
--hide-header | 如果设置了,则不打印header信息 | |
--messages | 需要消费的数量 | |
--num-fetch-threads | feth 数据的线程数 | 默认:1 |
--print-metrics | 结束的时候打印监控数据 | |
--show-detailed-stats | ||
--threads | 消费线程数; | 默认 10 |
11.删除指定分区的消息kafka-delete-records.sh
删除指定topic的某个分区的消息删除至offset为1024
先配置json文件offset-json-file.json
{"partitions":
[{"topic": "test1", "partition": 0,
"offset": 1024}],
"version":1
}
在执行命令
sh bin/kafka-delete-records.sh --bootstrap-server 172.23.250.249:9090 --offset-json-file config/offset-json-file.json
验证 通过 LogIKM 查看发送的消息
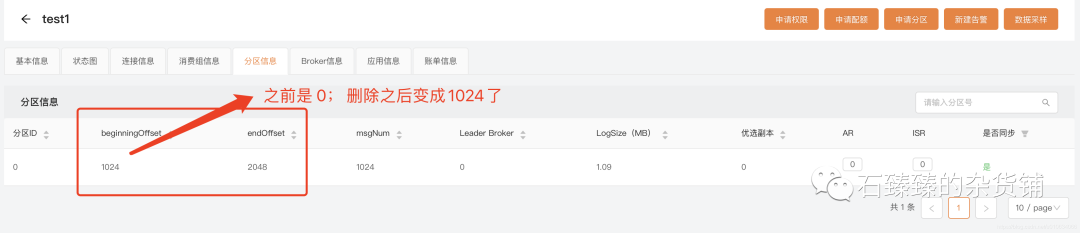
从这里可以看出来,配置"offset": 1024 的意思是从最开始的地方删除消息到 1024的offset; 是从最前面开始删除的
12. 查看Broker磁盘信息
查询指定topic磁盘信息--topic-list topic1,topic2
sh bin/kafka-log-dirs.sh --bootstrap-server xxxx:9090 --describe --topic-list test2
查询指定Broker磁盘信息--broker-list 0 broker1,broker2
sh bin/kafka-log-dirs.sh --bootstrap-server xxxxx:9090 --describe --topic-list test2 --broker-list 0
例如我一个3分区3副本的Topic的查出来的信息 logDir Broker中配置的log.dir
{
"version": 1,
"brokers": [{
"broker": 0,
"logDirs": [{
"logDir": "/Users/xxxx/work/IdeaPj/ss/kafka/kafka-logs-0",
"error": null,
"partitions": [{
"partition": "test2-1",
"size": 0,
"offsetLag": 0,
"isFuture": false
}, {
"partition": "test2-0",
"size": 0,
"offsetLag": 0,
"isFuture": false
}, {
"partition": "test2-2",
"size": 0,
"offsetLag": 0,
"isFuture": false
}]
}]
}, {
"broker": 1,
"logDirs": [{
"logDir": "/Users/xxxx/work/IdeaPj/ss/kafka/kafka-logs-1",
"error": null,
"partitions": [{
"partition": "test2-1",
"size": 0,
"offsetLag": 0,
"isFuture": false
}, {
"partition": "test2-0",
"size": 0,
"offsetLag": 0,
"isFuture": false
}, {
"partition": "test2-2",
"size": 0,
"offsetLag": 0,
"isFuture": false
}]
}]
}, {
"broker": 2,
"logDirs": [{
"logDir": "/Users/xxxx/work/IdeaPj/ss/kafka/kafka-logs-2",
"error": null,
"partitions": [{
"partition": "test2-1",
"size": 0,
"offsetLag": 0,
"isFuture": false
}, {
"partition": "test2-0",
"size": 0,
"offsetLag": 0,
"isFuture": false
}, {
"partition": "test2-2",
"size": 0,
"offsetLag": 0,
"isFuture": false
}]
}]
}, {
"broker": 3,
"logDirs": [{
"logDir": "/Users/xxxx/work/IdeaPj/ss/kafka/kafka-logs-3",
"error": null,
"partitions": []
}]
}]
}
折叠
如果你觉得通过命令查询磁盘信息比较麻烦,你也可以通过 LogIKM 查看
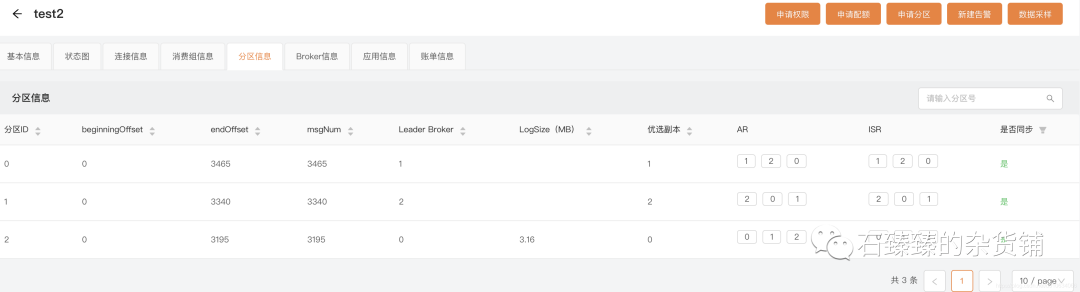
12. 消费者组管理 kafka-consumer-groups.sh
1. 查看消费者列表--list
sh bin/kafka-consumer-groups.sh --bootstrap-server xxxx:9090 --list

先调用MetadataRequest拿到所有在线Broker列表 再给每个Broker发送ListGroupsRequest请求获取 消费者组数据
2. 查看消费者组详情--describe
DescribeGroupsRequest
查看消费组详情--group 或 --all-groups
查看指定消费组详情
--groupsh bin/kafka-consumer-groups.sh --bootstrap-server xxxxx:9090 --describe --group test2_consumer_group
查看所有消费组详情
--all-groupssh bin/kafka-consumer-groups.sh --bootstrap-server xxxxx:9090 --describe --all-groups查看该消费组 消费的所有Topic、及所在分区、最新消费offset、Log最新数据offset、Lag还未消费数量、消费者ID等等信息

查询消费者成员信息--members
所有消费组成员信息
sh bin/kafka-consumer-groups.sh --describe --all-groups --members --bootstrap-server xxx:9090指定消费组成员信息sh bin/kafka-consumer-groups.sh --describe --members --group test2_consumer_group --bootstrap-server xxxx:9090

查询消费者状态信息--state
所有消费组状态信息
sh bin/kafka-consumer-groups.sh --describe --all-groups --state --bootstrap-server xxxx:9090指定消费组状态信息sh bin/kafka-consumer-groups.sh --describe --state --group test2_consumer_group --bootstrap-server xxxxx:9090

3. 删除消费者组--delete
DeleteGroupsRequest
删除消费组–delete
删除指定消费组
--groupsh bin/kafka-consumer-groups.sh --delete --group test2_consumer_group --bootstrap-server xxxx:9090删除所有消费组--all-groupssh bin/kafka-consumer-groups.sh --delete --all-groups --bootstrap-server xxxx:9090
PS: 想要删除消费组前提是这个消费组的所有客户端都停止消费/不在线才能够成功删除;否则会报下面异常
Error: Deletion of some consumer groups failed:
* Group 'test2_consumer_group' could not be deleted due to: java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.GroupNotEmptyException: The group is not empty.
4. 重置消费组的偏移量 --reset-offsets
能够执行成功的一个前提是 消费组这会是不可用状态;
下面的示例使用的参数是: --dry-run ;这个参数表示预执行,会打印出来将要处理的结果; 等你想真正执行的时候请换成参数--excute ;
下面示例 重置模式都是 --to-earliest 重置到最早的;
请根据需要参考下面 相关重置Offset的模式 换成其他模式;
重置指定消费组的偏移量 --group
重置指定消费组的所有Topic的偏移量
--all-topicsh bin/kafka-consumer-groups.sh --reset-offsets --to-earliest --group test2_consumer_group --bootstrap-server xxxx:9090 --dry-run --all-topic重置指定消费组的指定Topic的偏移量--topicsh bin/kafka-consumer-groups.sh --reset-offsets --to-earliest --group test2_consumer_group --bootstrap-server xxxx:9090 --dry-run --topic test2
重置所有消费组的偏移量 --all-group
重置所有消费组的所有Topic的偏移量
--all-topicsh bin/kafka-consumer-groups.sh --reset-offsets --to-earliest --all-group --bootstrap-server xxxx:9090 --dry-run --all-topic重置所有消费组中指定Topic的偏移量--topicsh bin/kafka-consumer-groups.sh --reset-offsets --to-earliest --all-group --bootstrap-server xxxx:9090 --dry-run --topic test2
--reset-offsets 后面需要接重置的模式
相关重置Offset的模式
| 参数 | 描述 | 例子 |
|---|---|---|
--to-earliest : | 重置offset到最开始的那条offset(找到还未被删除最早的那个offset) | |
--to-current: | 直接重置offset到当前的offset,也就是LOE | |
--to-latest: | 重置到最后一个offset | |
--to-datetime: | 重置到指定时间的offset;格式为:YYYY-MM-DDTHH:mm:SS.sss; | --to-datetime "2021-6-26T00:00:00.000" |
--to-offset | 重置到指定的offset,但是通常情况下,匹配到多个分区,这里是将匹配到的所有分区都重置到这一个值; 如果 1.目标最大offset<--to-offset, 这个时候重置为目标最大offset;2.目标最小offset>--to-offset ,则重置为最小; 3.否则的话才会重置为--to-offset的目标值; 一般不用这个 | --to-offset 3465 |
 |
|
| --shift-by | 按照偏移量增加或者减少多少个offset;正的为往前增加;负的往后退;当然这里也是匹配所有的; | --shift-by 100 、--shift-by -100 |
| --from-file | 根据CVS文档来重置; 这里下面单独讲解 | |
--from-file着重讲解一下
上面其他的一些模式重置的都是匹配到的所有分区; 不能够每个分区重置到不同的offset;不过**
--from-file**可以让我们更灵活一点;
-
先配置cvs文档 格式为: Topic:分区号: 重置目标偏移量
test2,0,100 test2,1,200 test2,2,300 -
执行命令
sh bin/kafka-consumer-groups.sh --reset-offsets --group test2_consumer_group --bootstrap-server xxxx:9090 --dry-run --from-file config/reset-offset.csv
5. 删除偏移量delete-offsets
能够执行成功的一个前提是 消费组这会是不可用状态;
偏移量被删除了之后,Consumer Group下次启动的时候,会从头消费;
sh bin/kafka-consumer-groups.sh --delete-offsets --group test2_consumer_group2 --bootstrap-server XXXX:9090 --topic test2
相关可选参数
| 参数 | 描述 | 例子 |
|---|---|---|
--bootstrap-server | 指定连接到的kafka服务; | –bootstrap-server localhost:9092 |
--list | 列出所有消费组名称 | --list |
--describe | 查询消费者描述信息 | --describe |
--group | 指定消费组 | |
--all-groups | 指定所有消费组 | |
--members | 查询消费组的成员信息 | |
--state | 查询消费者的状态信息 | |
--offsets | 在查询消费组描述信息的时候,这个参数会列出消息的偏移量信息; 默认就会有这个参数的; | |
dry-run | 重置偏移量的时候,使用这个参数可以让你预先看到重置情况,这个时候还没有真正的执行,真正执行换成--excute;默认为dry-run | |
--excute | 真正的执行重置偏移量的操作; | |
--to-earliest | 将offset重置到最早 | |
to-latest | 将offset重置到最近 |
附件
ConfigCommand 的一些可选配置
Topic相关可选配置
| key | value | 示例 |
|---|---|---|
| cleanup.policy | 清理策略 | |
| compression.type | 压缩类型(通常建议在produce端控制) | |
| delete.retention.ms | 压缩日志的保留时间 | |
| file.delete.delay.ms | ||
| flush.messages | 持久化message限制 | |
| flush.ms | 持久化频率 | |
| follower.replication.throttled.replicas | flowwer副本限流 格式:分区号:副本follower号,分区号:副本follower号 | 0:1,1:1 |
| index.interval.bytes | ||
| leader.replication.throttled.replicas | leader副本限流 格式:分区号:副本Leader号 | 0:0 |
| max.compaction.lag.ms | ||
| max.message.bytes | 最大的batch的message大小 | |
| message.downconversion.enable | message是否向下兼容 | |
| message.format.version | message格式版本 | |
| message.timestamp.difference.max.ms | ||
| message.timestamp.type | ||
| min.cleanable.dirty.ratio | ||
| min.compaction.lag.ms | ||
| min.insync.replicas | 最小的ISR | |
| preallocate | ||
| retention.bytes | 日志保留大小(通常按照时间限制) | |
| retention.ms | 日志保留时间 | |
| segment.bytes | segment的大小限制 | |
| segment.index.bytes | ||
| segment.jitter.ms | ||
| segment.ms | segment的切割时间 | |
| unclean.leader.election.enable | 是否允许非同步副本选主 |
Broker相关可选配置
| key | value | 示例 |
|---|---|---|
| advertised.listeners | ||
| background.threads | ||
| compression.type | ||
| follower.replication.throttled.rate | ||
| leader.replication.throttled.rate | ||
| listener.security.protocol.map | ||
| listeners | ||
| log.cleaner.backoff.ms | ||
| log.cleaner.dedupe.buffer.size | ||
| log.cleaner.delete.retention.ms | ||
| log.cleaner.io.buffer.load.factor | ||
| log.cleaner.io.buffer.size | ||
| log.cleaner.io.max.bytes.per.second | ||
| log.cleaner.max.compaction.lag.ms | ||
| log.cleaner.min.cleanable.ratio | ||
| log.cleaner.min.compaction.lag.ms | ||
| log.cleaner.threads | ||
| log.cleanup.policy | ||
| log.flush.interval.messages | ||
| log.flush.interval.ms | ||
| log.index.interval.bytes | ||
| log.index.size.max.bytes | ||
| log.message.downconversion.enable | ||
| log.message.timestamp.difference.max.ms | ||
| log.message.timestamp.type | ||
| log.preallocate | ||
| log.retention.bytes | ||
| log.retention.ms | ||
| log.roll.jitter.ms | ||
| log.roll.ms | ||
| log.segment.bytes | ||
| log.segment.delete.delay.ms | ||
| max.connections | ||
| max.connections.per.ip | ||
| max.connections.per.ip.overrides | ||
| message.max.bytes | ||
| metric.reporters | ||
| min.insync.replicas | ||
| num.io.threads | ||
| num.network.threads | ||
| num.recovery.threads.per.data.dir | ||
| num.replica.fetchers | ||
| principal.builder.class | ||
| replica.alter.log.dirs.io.max.bytes.per.second | ||
| sasl.enabled.mechanisms | ||
| sasl.jaas.config | ||
| sasl.kerberos.kinit.cmd | ||
| sasl.kerberos.min.time.before.relogin | ||
| sasl.kerberos.principal.to.local.rules | ||
| sasl.kerberos.service.name | ||
| sasl.kerberos.ticket.renew.jitter | ||
| sasl.kerberos.ticket.renew.window.factor | ||
| sasl.login.refresh.buffer.seconds | ||
| sasl.login.refresh.min.period.seconds | ||
| sasl.login.refresh.window.factor | ||
| sasl.login.refresh.window.jitter | ||
| sasl.mechanism.inter.broker.protocol | ||
| ssl.cipher.suites | ||
| ssl.client.auth | ||
| ssl.enabled.protocols | ||
| ssl.endpoint.identification.algorithm | ||
| ssl.key.password | ||
| ssl.keymanager.algorithm | ||
| ssl.keystore.location | ||
| ssl.keystore.password | ||
| ssl.keystore.type | ||
| ssl.protocol | ||
| ssl.provider | ||
| ssl.secure.random.implementation | ||
| ssl.trustmanager.algorithm | ||
| ssl.truststore.location | ||
| ssl.truststore.password | ||
| ssl.truststore.type | ||
| unclean.leader.election.enable |
Users相关可选配置
| key | value | 示例 |
|---|---|---|
| SCRAM-SHA-256 | ||
| SCRAM-SHA-512 | ||
| consumer_byte_rate | 针对消费者user进行限流 | |
| producer_byte_rate | 针对生产者进行限流 | |
| request_percentage | 请求百分比 |
clients相关可选配置
| key | value | 示例 |
|---|---|---|
| consumer_byte_rate | ||
| producer_byte_rate | ||
| request_percentage |
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维副业方向
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
运维转行学习路线
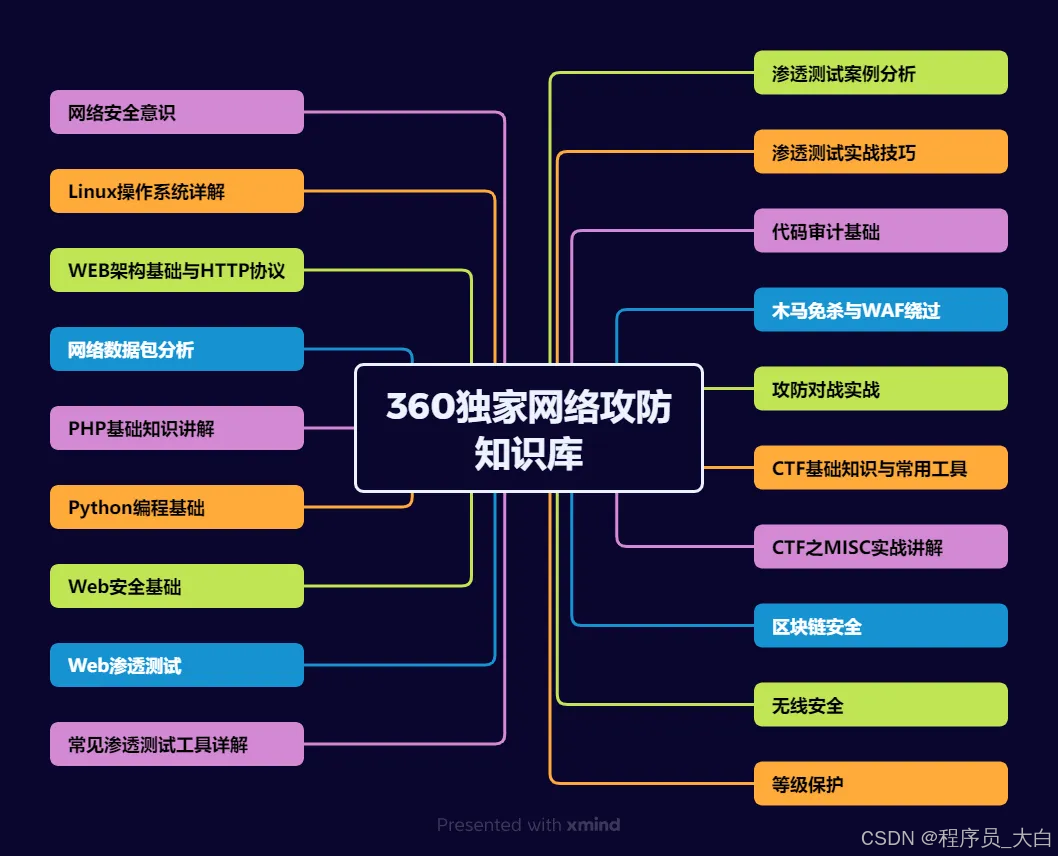
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
(三)第三阶段:渗透测试技能学习
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
(四)第四阶段:企业级安全攻防(含红蓝对抗)、应急响应
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
运维转行网络攻防知识库分享
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧

7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









