







目录
一、下载 Jmeter
二、配置环境变量
三、设置中文语言
四、入门最简单的高并发性能压测流程
1. 添加线程组
2. 添加请求
3. 添加监听器
3.1 添加聚合报告
3.2 添加结果树
4. 启动测试
2 种启动方式:
查看结果树:
聚合报告:
五、其它操作
1. 清理测试数据
一、下载 Jmeter
随便下载一个压缩包版本
解压后进入 bin 打开:
- jmeter.sh :Linux 版本的启动脚本
- jmeter.cmd :Windows 版本的启动脚本
| ApacheJMeter.jar | JAR文件 | JMeter的核心文件,包含所有类和资源,双击可启动JMeter。 |
| BeanShellAssertion.bshrc | BeanShell脚本 | BeanShell断言配置,用于测试过程中执行脚本断言。 |
| BeanShellFunction.bshrc | BeanShell脚本 | BeanShell函数配置,定义和使用自定义BeanShell函数。 |
| BeanShellListeners.bshrc | BeanShell脚本 | BeanShell监听器配置,用于测试过程中的监听操作。 |
| BeanShellSampler.bshrc | BeanShell脚本 | BeanShell取样器配置,用于测试过程中的取样操作。 |
| create-rmi-keystore.bat/.sh | 批处理/脚本文件 | 创建RMI信任存储,用于配置RMI安全。 |
| hc.parameters | 参数文件 | Harmony Class Loader参数,配置类加载器行为。 |
| heapdump.cmd/.sh | 命令/脚本文件 | 生成堆转储文件,用于内存分析。 |
| jaas.conf | 配置文件 | JAAS配置,配置Java认证和授权服务。 |
| jmeter.bat/.sh | 批处理/脚本文件 | 启动JMeter,分别适用于Windows和Unix/Linux。 |
| jmeter.log | 日志文件 | 记录JMeter运行日志,用于问题排查。 |
| jmeter.properties | 属性文件 | JMeter全局配置,如语言、线程数等。 |
| jmeter-n.cmd/-n-r.cmd | 命令文件 | 非GUI模式运行JMeter,后者还重定向输出。 |
| jmeter-server | 目录 | JMeter服务器配置,用于分布式测试。 |
| jmeter-server.bat/.sh | 批处理/脚本文件 | 启动JMeter服务器,分别适用于Windows和Unix/Linux。 |
| krb5.conf | 配置文件 | Kerberos客户端配置,用于Kerberos认证。 |
| log4j2.xml | 日志配置文件 | Log4j2配置,定义日志输出格式和级别。 |
| mirror-server | 目录 | 镜像服务器配置,用于镜像测试。 |
| reportgenerator.properties | 属性文件 | 报告生成器配置,定义报告生成参数。 |
| saveservice.properties | 属性文件 | 保存服务配置,定义测试结果保存格式。 |
| shutdown.cmd/.sh | 命令/脚本文件 | 关闭JMeter,分别适用于Windows和Unix/Linux。 |
| stoptest.cmd/.sh | 命令/脚本文件 | 停止JMeter测试,分别适用于Windows和Unix/Linux。 |
| system.properties | 属性文件 | 系统级配置,定义JVM参数等。 |
| threaddump.cmd/.sh | 命令/脚本文件 | 生成线程转储文件,用于线程分析。 |
| upgrade.properties | 属性文件 | 升级配置,定义JMeter升级参数。 |
| user.properties | 属性文件 | 用户级配置,定义用户相关参数。 |
| utility.groovy | Groovy脚本 | 实用工具脚本,可能包含自定义函数或工具类。 |
二、配置环境变量
-
在正常情况下,JMeter不需要单独配置
ApacheJMeter_core.jar或jorphan.jar的环境变量即可正常运行测试。 -
即使未设置
JMETER_HOME,只要直接运行jmeter.bat(Windows)或jmeter.sh(Linux/Mac)且 JMeter 目录结构完整,脚本也能通过相对路径找到 JAR 包。 -
为了能快速命令方式启动以及兼容性和避免路径问题,建议设置
JMETER_HOME。
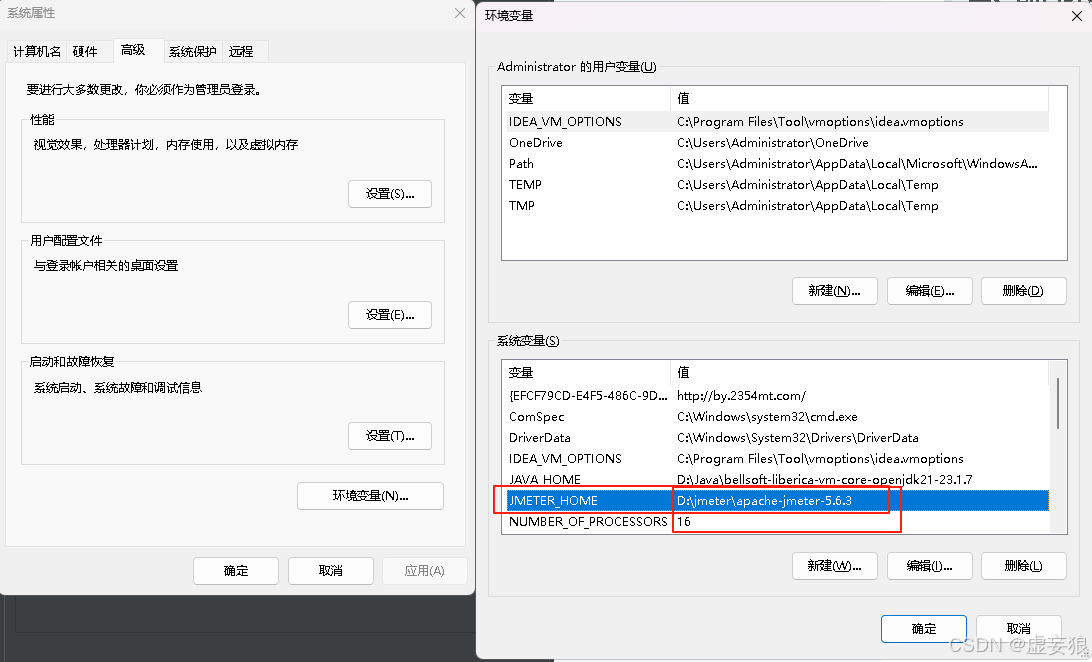
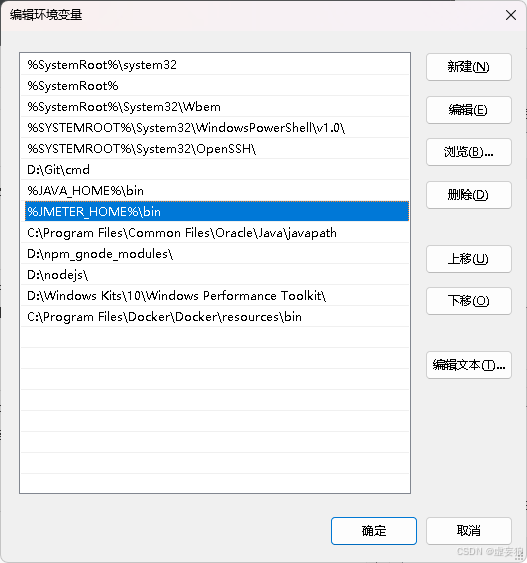
Windows11 直接搜索环境变量:
- 打开环境变量
- 系统变量 —> 增加 JMETER_HOME —> 值建议 jmeter主目录\ Jmeter 版本
- 系统变量 —> 找到 path 双击打开 —> 增加 %JMETER_HOME%\bin
三、设置中文语言
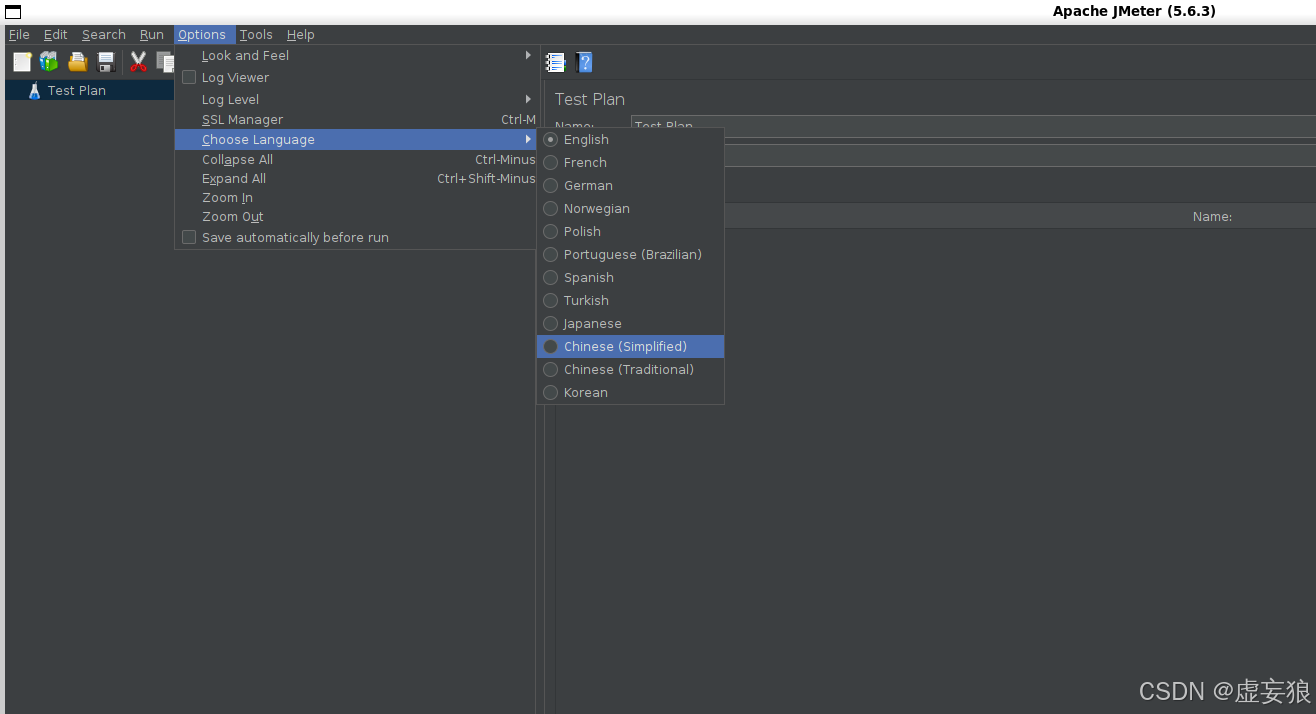
- Options 选项
- Choose Language 更改语言
- Chinese 中文
四、入门最简单的高并发性能压测流程
- 添加线程组
- 添加请求
- 添加监听树
- 启动测试
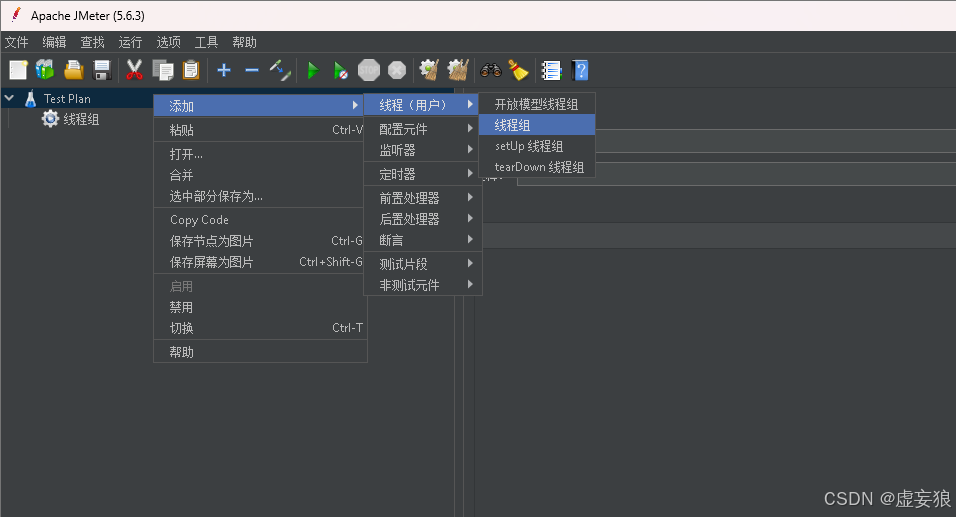
1. 添加线程组
右击 TestPlan --> 添加 --> 线程(用户) --> 线程组
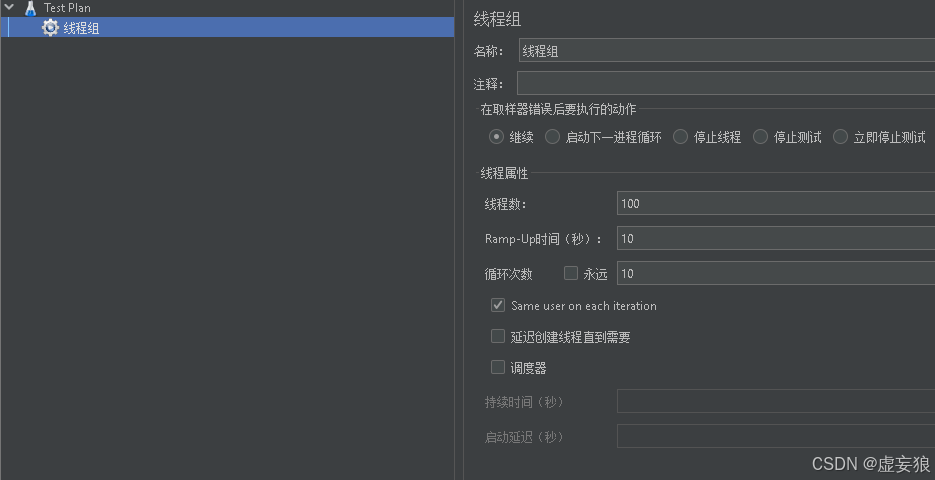
填入测试:
- 线程组:100
- Ramp-Up:10
- 循环次数:10
JMeter 线程组核心参数解释表
| 参数名称 | 含义 | 示例说明 |
|---|---|---|
| 线程数 | 定义测试中要模拟的 最大并发虚拟用户 (VU) 数量。 | 线程数 = 10:表示 JMeter 最终会创建并运行 10 个独立的线程(虚拟用户),每个用户都会执行测试计划中定义的请求。 |
| Ramp-Up 时间 (秒) | 定义 JMeter 启动所有线程 (虚拟用户) 所需的总时间 (秒)。目的是平滑增加负载,避免瞬间压力冲击。 | 线程数 = 10,Ramp-Up = 100 秒: |
| * 0秒: 启动第1个用户。 | ||
| * 10秒: 启动第2个用户 (100秒 / 10用户 = 10秒/用户)。 | ||
| * 20秒: 启动第3个用户。 | ||
| * … | ||
| * 90秒: 启动第10个用户。 | ||
| 所有10个用户将在第90秒时全部启动完毕。 | ||
| 循环次数 | 定义 每个线程 (虚拟用户) 执行其包含的请求 (采样器) 序列的次数。 | 循环次数 = 5: |
| * 每个线程(用户)会从头到尾完整地执行测试计划中定义的请求(比如:登录 -> 浏览商品 -> 下单)5次。 | ||
| * 如果勾选了“永远”,线程会无限循环执行请求序列,直到手动停止测试、达到设置的测试持续时间或线程被停止(如通过定时器)。 |
线程组勾线永久:模拟持续并发量用户请求,常用配置!
2. 添加请求
右击线程组 --> 添加 --> 取样器 --> HTTP 请求
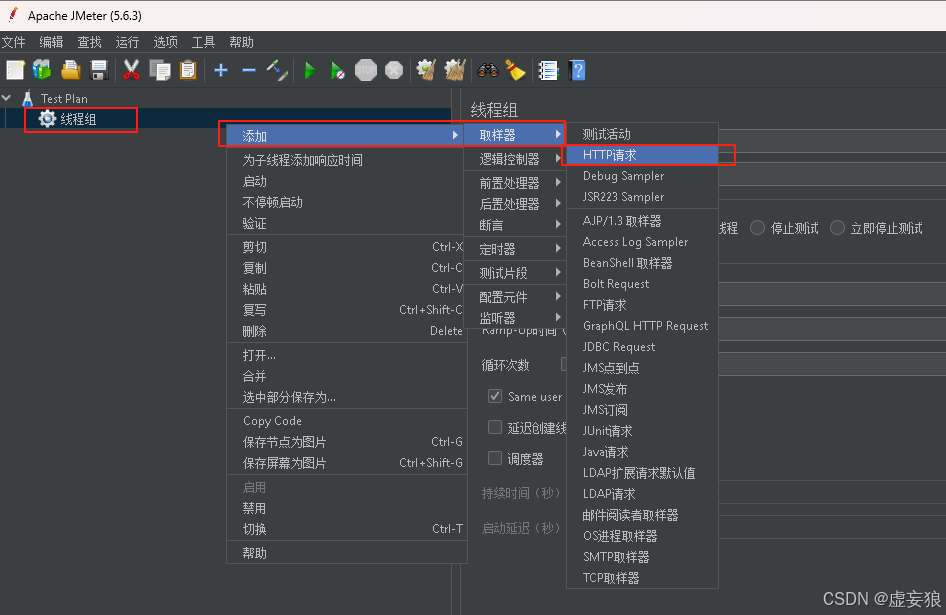
填入参数
- 协议:http
- 服务器名称/IP:127.0.0.1
- 端口号:8080
- HTTP请求方法:GET
- 请求路径(必须 / 开头):/test-thread-2
- 内容编码(不分大小写):UTF-8
- 无参

SpringBoot 项目 Test Demo 接口信息
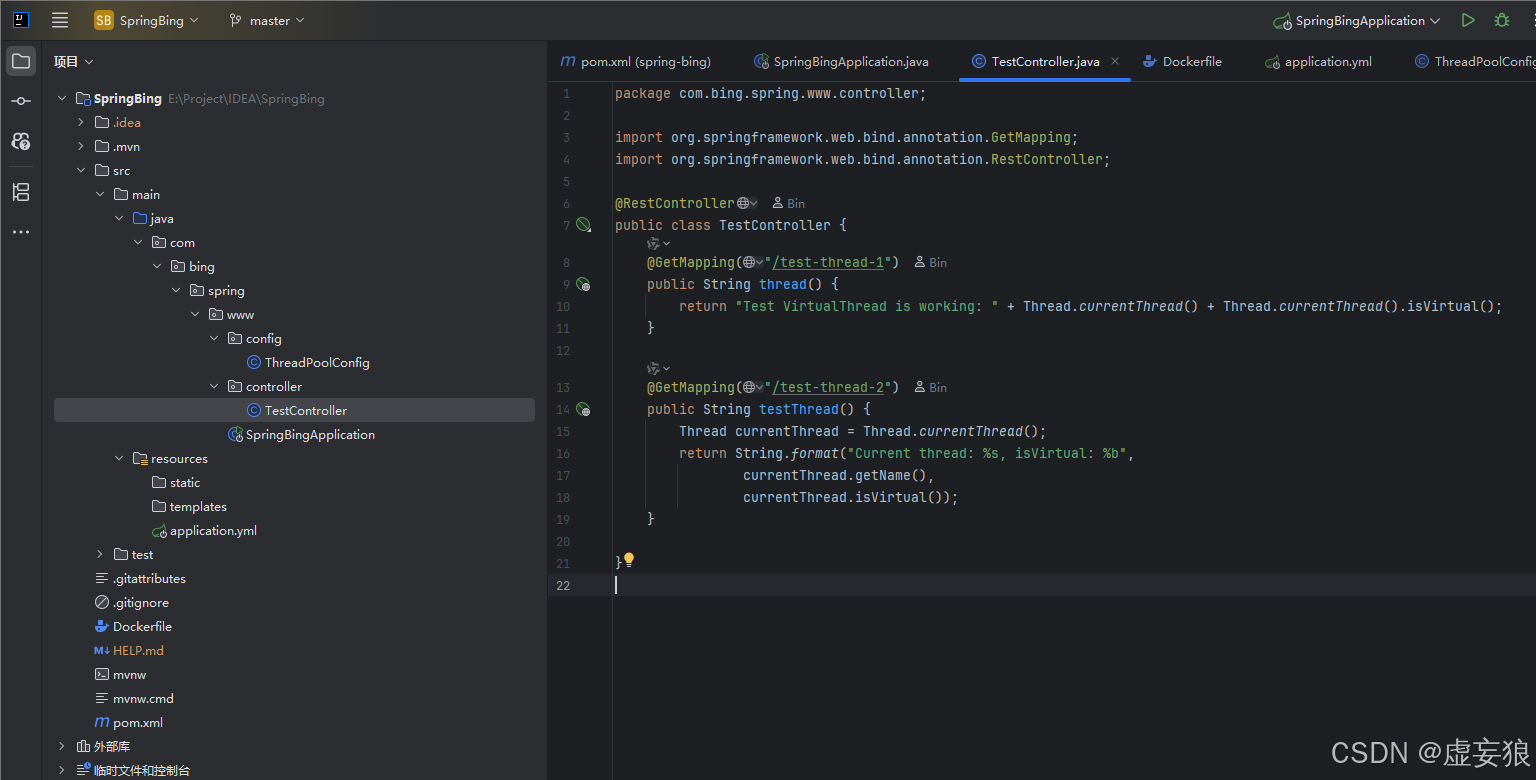
JMeter HTTP 请求配置项详解表
| 配置项 | 解释说明 | 示例/注意事项 |
|---|---|---|
| 名称 (Name) | 为这个 HTTP 请求采样器起一个描述性名称。便于在结果树、报告等组件中识别不同的请求。 | 首页访问,用户登录 API,查询订单详情 |
| 注释 (Comments) | 可选字段,用于添加关于此请求的额外说明。 | |
| 协议 (Protocol) | 指定请求使用的应用层协议。 | * http: 默认值,标准 HTTP。 |
* https: 加密的 HTTP (SSL/TLS)。 | ||
| * 留空: JMeter 会继承线程组或 HTTP 请求默认值中设置的协议(如果有)。 | ||
注意: 使用 https 时,JMeter 会自动处理 SSL 握手,但可能需要配置信任库来处理自签名证书。 | ||
| 服务器名称或 IP (Server Name or IP) | 指定目标 Web 服务器的域名或 IP 地址。这是构建请求 URL 最核心的部分。 | * www.example.com |
* api.myapp.com | ||
* 192.168.1.100 | ||
注意: 不要包含 http:// 或 https:// 前缀,也不要在末尾加 /。 | ||
| 端口号 (Port Number) | 指定目标服务器监听的网络端口号。 | * 80: HTTP 默认端口。 |
* 443: HTTPS 默认端口。 | ||
* 8080, 8443: 常见的应用服务器 HTTP/HTTPS 端口。 | ||
* 留空: 如果使用 http 协议则默认为 80,使用 https 协议则默认为 443。 | ||
| HTTP 请求 (HTTP Request) | 选择 HTTP 请求方法 (Verb)。 | * GET: 获取资源(参数通常在 URL 后 ?key=value)。 |
* POST: 提交数据(数据通常在 Body 中)。 | ||
* PUT: 更新资源。 | ||
* DELETE: 删除资源。 | ||
* HEAD, OPTIONS, PATCH 等。 POST 最常用,特别是带表单或 JSON 时。 | ||
| 路径 (Path) | 指定请求的资源路径 (URI),相对于服务器的根目录。 | * /index.html |
* /api/v1/login | ||
* /products/search | ||
| 注意: | ||
* 必须以 / 开头。 | ||
* 可以包含路径参数 (如 /users/{userId}),但 JMeter 不直接处理占位符,需用变量或硬编码值替换。 | ||
| 内容编码 (Content encoding) | 指定 HTTP 请求体 (Body) 的字符编码。主要影响 POST/PUT 等方法中发送的 Parameters 或 Body Data。 | * utf-8: 最常用,支持多语言。 |
* iso-8859-1 | ||
* gbk (中文) | ||
注意: 如果服务器响应返回乱码,可能需要检查响应头中的 Content-Type 编码或使用 JMeter 的后置处理器(如 BeanShell PostProcessor)进行转码。 通常保持 utf-8 即可。 | ||
| 参数 (Parameters) | 用于添加 GET 请求的查询字符串参数 (URL 后 ?key=value&key2=value2) 或 POST 请求的 application/x-www-form-urlencoded 表单参数。 | * 模式: 名称=值 对。 |
| * GET: 参数会自动附加到 URL 后。 | ||
| * POST (x-www-form-urlencoded): 参数会被编码后放入请求体。 | ||
| 注意: | ||
* 勾选 Encode? 让 JMeter 自动对参数值进行 URL 编码。 | ||
* 勾选 Include Equals? 确保即使值为空也发送 key=。 与 Body Data 互斥! | ||
| 消息体数据 (Body Data) | 用于 直接输入 HTTP 请求体 (Body) 的原始内容。适用于 POST/PUT 等方法发送 非表单数据,如 JSON, XML, 纯文本。 | * {"username": "test", "password": "secret"} (JSON) |
* <request><id>123</id></request> (XML) | ||
* This is plain text | ||
| 注意: | ||
* 必须设置正确的 Content-Type 请求头(如 application/json)告诉服务器如何解析。 | ||
* 与 Parameters 和 Files Upload 互斥! | ||
| 文件上传 (Files Upload) | 用于模拟 文件上传 场景 (multipart/form-data)。 | * 文件路径: 选择要上传的本地文件路径。 |
* 参数名称: 服务器端接收文件字段的名称 (通常是 file 或 upload)。 | ||
* MIME 类型: 指定上传文件的 MIME 类型 (如 image/png, text/plain, application/pdf)。 | ||
| 注意: | ||
* 会自动设置 Content-Type: multipart/form-data 请求头。 | ||
* 与 Parameters 和 Body Data 互斥! JMeter 会在此模式下忽略它们(除非在下面单独添加额外参数)。 |
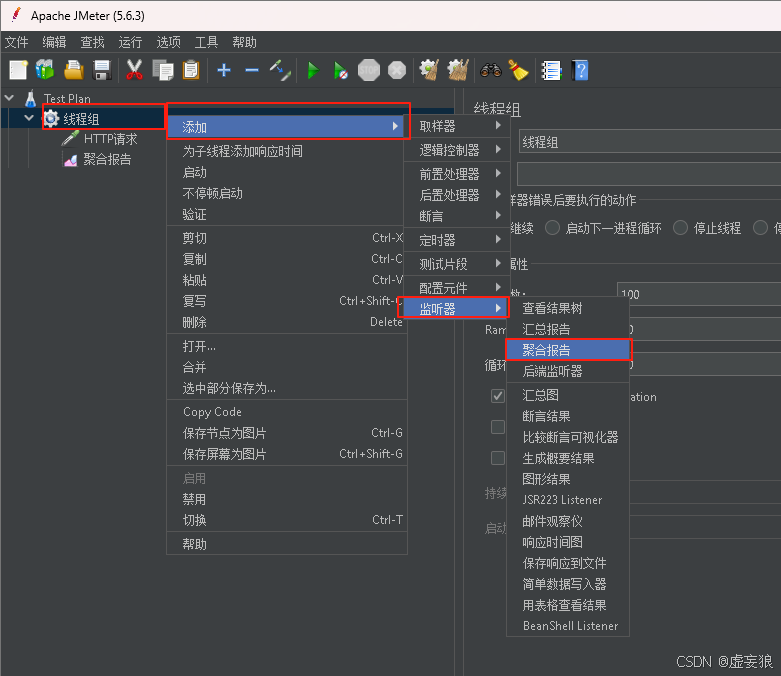
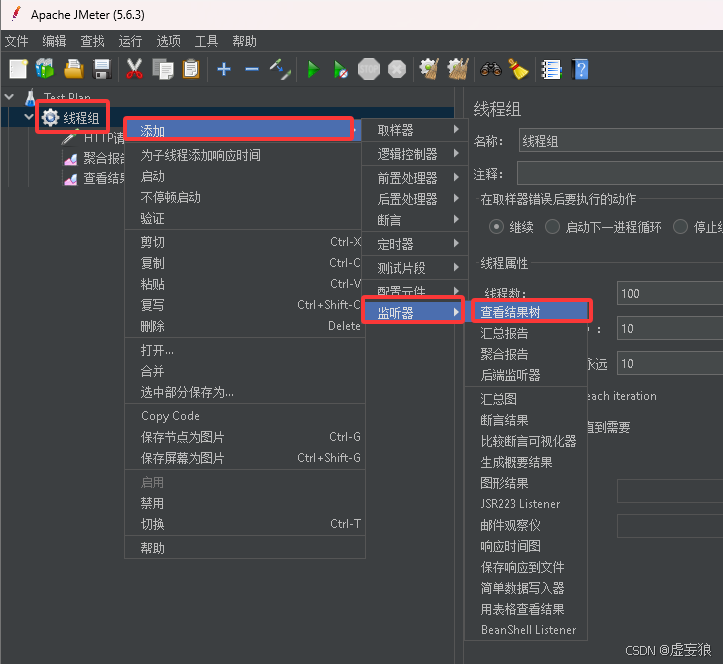
3. 添加监听器
3.1 添加聚合报告
右击线程组 --> 添加 --> 监听器 --> 监听器 --> 聚合报告
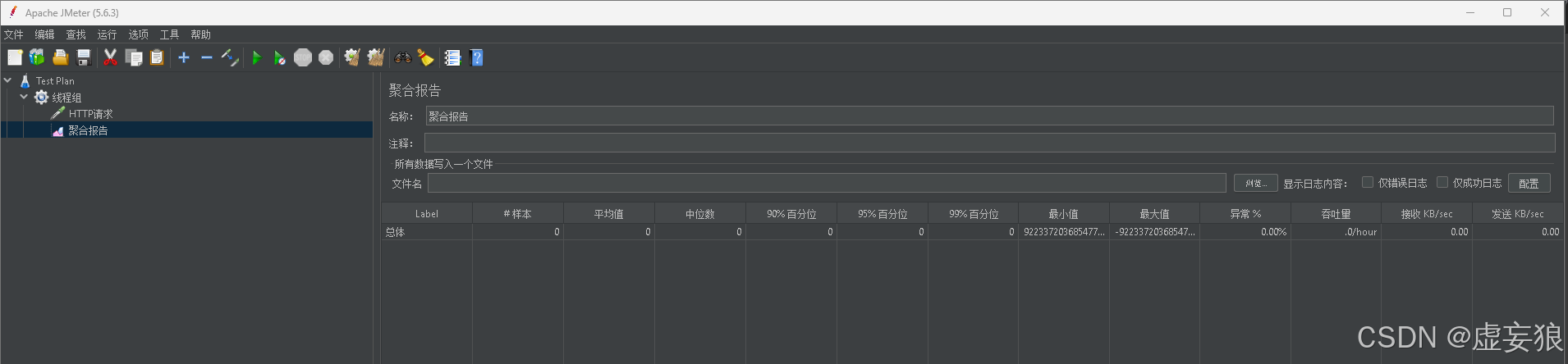
JMeter 聚合报告 (Aggregate Report) 各统计列详解表
| 列名 | 解释说明 | 重要性/解读 |
|---|---|---|
| Label (标签) | 对应 采样器 (Sampler) 的名称。就是你为 HTTP 请求、JDBC 请求等设置的“名称”。 | 关键标识。用于区分不同请求类型的性能数据。确保为每个重要请求设置清晰、唯一的名称。 |
| # Samples (样本数) | 在测试运行期间,该采样器总共被执行的次数。即这个请求一共发送了多少次。 | 基础量度。表示该请求承受的总负载量。结合线程数、循环次数、持续时间理解。样本数少可能意味着测试配置错误(如持续时间太短)或请求本身没有被正确调用。 |
| Average (平均值) ms | 所有 样本响应时间的算术平均值。单位是毫秒 (ms)。 | 总体趋势参考。反映请求的“平均”响应速度。注意: 平均值容易受极少数特别长或特别短的响应时间影响,可能掩盖实际用户体验(如大部分用户很快,但少数极慢请求拉高了平均值)。 |
| Median (中位数) ms | 将所有样本的响应时间从小到大排序,位于最中间的那个值。如果样本数是偶数,则取中间两个值的平均值。单位是毫秒 (ms)。 | 更贴近“典型”用户体验。表示至少 50% 的请求响应时间小于或等于这个值。相比平均值,中位数对极端值不敏感,更能代表大多数用户的感受。例如,中位数 200ms 表示一半请求在 200ms 内完成。 |
| 90% Line (90% 百分位) ms | 将所有样本的响应时间从小到大排序,90% 的样本响应时间小于或等于这个值。单位是毫秒 (ms)。 | 关键性能指标 (KPI)。也称为 P90。表示 90% 的用户体验在这个时间范围内。这是评估系统性能满足 服务水平协议 (SLA) 的常用指标(如 SLA 要求 95% 请求 < 1s,则看 95% Line)。它揭示了尾部延迟 (Tail Latency),比平均值/中位数更能反映“慢请求”的影响。值越接近中位数越好。 |
| 95% Line (95% 百分位) ms | 将所有样本的响应时间从小到大排序,95% 的样本响应时间小于或等于这个值。单位是毫秒 (ms)。 | 更严格的 KPI。也称为 P95。表示 95% 的用户体验在这个时间范围内。对要求更高的场景(如金融交易核心接口)非常重要。关注其与 90% Line 的差距,差距过大可能意味着系统不稳定或存在瓶颈。 |
| 99% Line (99% 百分位) ms | 将所有样本的响应时间从小到大排序,99% 的样本响应时间小于或等于这个值。单位是毫秒 (ms)。 | 揭示最差情况。也称为 P99。表示 99% 的用户体验在这个时间范围内,只有 1% 的请求比这个慢。用于评估极端情况下的用户体验和系统稳定性。这个值过高,即使平均值/90%很低,也会让那 1% 的用户感觉非常糟糕,可能影响口碑。 |
| Min (最小值) ms | 所有样本响应时间中的最短时间。单位是毫秒 (ms)。 | 参考值。表示该请求理论上能达到的最快速度。通常由缓存命中或极简操作导致。单独看意义不大,需与其他值对比。 |
| Max (最大值) ms | 所有样本响应时间中的最长时间。单位是毫秒 (ms)。 | 揭示问题点。表示该请求遇到的最慢情况。这个值非常高通常是问题的信号(如数据库死锁、资源耗尽、网络中断、特定请求触发了慢逻辑)。需要结合日志和监控排查具体原因。 |
| Error % (异常率/错误率) % | 该采样器执行失败的请求占总样本数的百分比。失败可能由多种原因引起:HTTP 状态码 4xx/5xx、连接超时、响应断言失败等。 | 核心健康指标。最重要指标之一! 理想情况下应为 0%。非零表示有请求失败,直接影响用户体验和系统可用性。即使是 0.1% 也需要关注。高错误率通常意味着系统存在严重问题(代码缺陷、配置错误、资源不足等)。必须分析错误类型(查看结果树、日志)并解决。 |
| Throughput (吞吐量) / sec | 单位时间内(每秒)服务器成功处理的该请求的数量。单位通常是 requests per second (请求数/秒)。JMeter 计算方式:Throughput = (样本数 - 错误数) / 测试运行总时长(秒)。 | 核心性能容量指标。表示系统处理该请求的能力。数值越高越好。是评估系统性能、容量规划(需要多少服务器支撑预期流量)的关键依据。注意:这是该特定请求的吞吐量,不是整个系统的总吞吐量。总吞吐量需要看聚合报告最底部的汇总行或使用其他监听器(如 Summary Report)。 |
| Received KB/sec (接收 KB/秒) | 单位时间内(每秒)JMeter 从服务器接收到的该请求响应数据的总量。单位是千字节每秒 (KB/sec)。 | 网络消耗指标。反映该请求返回数据的大小和频率对下行带宽的压力。对于返回大量数据(如图片、文件下载)的请求,这个值会很高。需关注是否可能成为网络瓶颈。 |
| Sent KB/sec (发送 KB/秒) | 单位时间内(每秒)JMeter 向服务器发送的该请求请求数据的总量。单位是千字节每秒 (KB/sec)。 | 网络消耗指标。反映该请求发送数据的大小和频率对上行带宽的压力。对于上传文件或提交大量表单数据的请求(POST with large body),这个值会很高。需关注是否可能成为网络瓶颈。 |
| Avg. Bytes (平均字节数) | 每个样本响应体大小的平均值。单位是字节 (Bytes)。 | 数据量参考。帮助理解单个响应通常返回多少数据。结合吞吐量可以估算网络流量 |
3.2 添加结果树
右击线程组 --> 添加 --> 监听器 --> 查看结果树
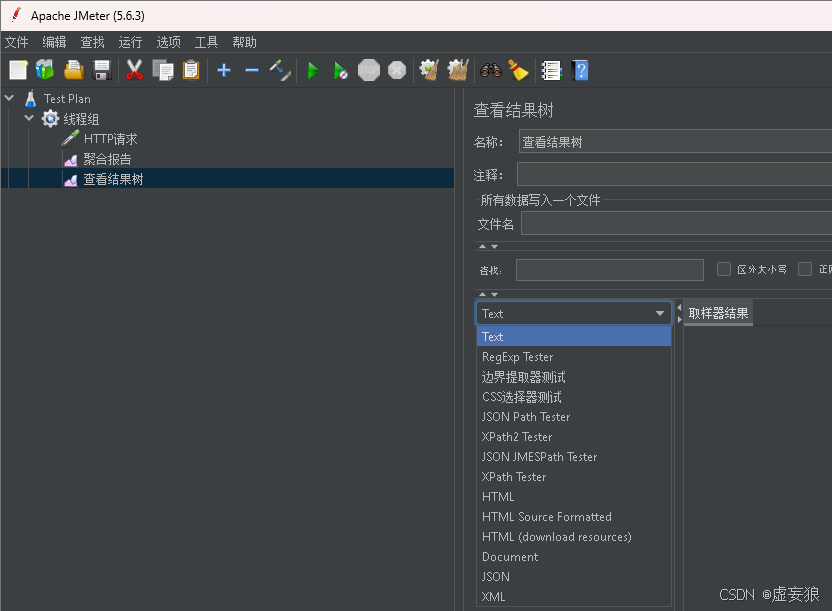
JMeter 查看结果树 (View Results Tree) 显示格式详解表
| 格式名称 | 适用数据 | 核心功能与特点 | 典型使用场景 | 注意事项 |
|---|---|---|---|---|
| Text | 任何文本响应 | * 最原始格式。 直接将响应体作为纯文本显示。 | ||
| * 对于非文本响应(如图片),会显示二进制乱码或提示。 | * 快速查看原始响应内容。 | |||
| * 查看非结构化文本。 | ||||
| * 当其他解析器不可用时。 | * 二进制内容(如图片、PDF)会显示乱码。 | |||
| * 长文本无格式化,可读性差。 | ||||
| RegExp Tester | 任何文本响应 | * 专门用于测试正则表达式。 | ||
| * 提供一个输入框输入正则表达式。 | ||||
| * 高亮显示匹配到的文本。 | ||||
| * 显示匹配组结果。 | * 调试和验证 正则表达式提取器 (Regular Expression Extractor) 的正则表达式。 | |||
| * 快速测试正则是否能匹配响应内容。 | 仅用于测试正则表达式,不是常规查看响应的格式。 | |||
| Boundary Extractor Tester | 任何文本响应 | * 专门用于测试边界提取器。 | ||
| * 提供输入框设置左边界和右边界。 | ||||
| * 高亮显示根据边界提取到的文本。 | ||||
| * 显示提取结果。 | * 调试和验证 边界提取器 (Boundary Extractor) 的左右边界设置。 | 仅用于测试边界提取器,不是常规查看响应的格式。 | ||
| CSS Selector Tester | HTML 响应 | * 专门用于测试 CSS/JQuery 选择器。 | ||
| * 提供一个输入框输入 CSS 选择器表达式。 | ||||
| * 高亮显示匹配到的 HTML 元素。 | ||||
| * 显示提取结果(如 text, html, 属性值)。 | * 调试和验证 CSS/JQuery 提取器 (CSS/JQuery Extractor) 的选择器表达式。 | 仅用于测试 CSS/JQuery 选择器,不是常规查看响应的格式。 | ||
| JSON Path Tester | JSON 响应 | * 专门用于测试 JSON Path 表达式。 | ||
| * 提供一个输入框输入 JSON Path 表达式。 | ||||
| * 高亮显示或定位匹配的 JSON 节点。 | ||||
| * 显示提取结果。 | * 调试和验证 JSON 提取器 (JSON Extractor) 或 JSON Path 断言 的 JSON Path 表达式。 | 仅用于测试 JSON Path,不是常规查看响应的格式。 | ||
| XPath2 Tester | XML 响应 | * 专门用于测试 XPath 2.0 表达式。 | ||
| * 提供一个输入框输入 XPath 2.0 表达式。 | ||||
| * 高亮显示或定位匹配的 XML 节点。 | ||||
| * 显示提取结果。 | * 调试和验证 XPath2 提取器 (XPath2 Extractor) 或 XPath2 断言 的 XPath 2.0 表达式。 | 仅用于测试 XPath 2.0,不是常规查看响应的格式。 | ||
| JSON JMESPath Tester | JSON 响应 | * 专门用于测试 JMESPath 表达式。 | ||
| * 提供一个输入框输入 JMESPath 表达式。 | ||||
| * 高亮显示或定位匹配的 JSON 节点。 | ||||
| * 显示提取结果。 | * 调试和验证 JMESPath 提取器 (JMESPath Extractor) 或 JMESPath 断言 的 JMESPath 表达式。 | 仅用于测试 JMESPath,不是常规查看响应的格式。JMESPath 是 JSON 查询的更强大语言,功能类似 JSON Path 的超集。 | ||
| XPath Tester | XML 响应 | * 专门用于测试 XPath 1.0 表达式。 | ||
| * 提供一个输入框输入 XPath 1.0 表达式。 | ||||
| * 高亮显示或定位匹配的 XML 节点。 | ||||
| * 显示提取结果。 | * 调试和验证 XPath 提取器 (XPath Extractor) 或 XPath 断言 的 XPath 1.0 表达式。 | 仅用于测试 XPath 1.0,不是常规查看响应的格式。 | ||
| HTML | HTML 响应 | * 渲染 HTML 视图。 尝试像浏览器一样渲染 HTML 页面。 | ||
| * 显示基本的页面布局和元素。 | ||||
| * 不加载外部资源(图片、CSS、JS)。 | * 快速检查页面渲染的基本结构和内容是否符合预期。 | |||
| * 查看纯 HTML 内容呈现的效果。 | * 渲染非常基础,不支持现代 CSS/JS,效果远不如真实浏览器。 | |||
| * 性能消耗大,在压测中开启会严重影响结果,调试时使用,压测时务必禁用。 | ||||
| HTML Source Formatted | HTML 响应 | * 格式化显示 HTML 源代码。 | ||
| * 对原始 HTML 进行缩进、换行等格式化,提高可读性。 | * 最常用! 清晰、可读地查看 HTML 响应的原始源代码。 | |||
| * 分析 HTML 结构,查找特定元素或内容。 | 比原始的 Text 模式更易读,但仍是源代码视图。 | |||
| HTML (download resources) | HTML 响应 | * 渲染 HTML 视图并尝试下载资源。 类似 HTML 模式,但会尝试下载页面中引用的图片、CSS、JS 等资源。 | ||
| * 极其消耗资源且不稳定。 | * 理论上可以更完整地模拟浏览器,但实际很少用且强烈不推荐。 | * 性能消耗巨大! 严重影响 JMeter 性能和压测结果。 | ||
| * 下载过程可能失败或卡住。 | ||||
| * 强烈建议避免使用此模式,尤其在压测时绝对禁用。 | ||||
| Document | HTML / XML 响应 | * 基于 DOM 的视图。 将 HTML/XML 解析成文档对象模型 (DOM) 并以树形结构展示。 | ||
| * 可以展开/折叠节点。 | ||||
| * 显示元素标签、属性、文本内容等。 | * 以结构化方式分析 HTML/XML 文档的层次结构。 | |||
| * 辅助编写 XPath 或 CSS 选择器。 | 比纯文本更结构化,但不如源代码视图直观。 | |||
| JSON | JSON 响应 | * 格式化显示 JSON 数据。 | ||
| * 对原始 JSON 进行缩进、换行、语法高亮(取决于 JMeter 版本/主题)。 | ||||
| * 可展开/折叠 JSON 对象和数组。 | * 最常用! 清晰、可读地查看 JSON 响应的结构。 | |||
| * 快速定位特定字段的值。 | ||||
| * 调试 JSON 接口的必备视图。 | 极大地提高了 JSON 数据的可读性和调试效率。 | |||
| XML | XML 响应 | * 格式化显示 XML 数据。 | ||
| * 对原始 XML 进行缩进、换行、语法高亮(取决于 JMeter 版本/主题)。 | ||||
| * 可展开/折叠 XML 元素节点。 | * 最常用! 清晰、可读地查看 XML 响应的结构。 | |||
| * 快速定位特定元素或属性。 | ||||
| * 调试 XML 接口的必备视图。 | 极大地提高了 XML 数据的可读性和调试效率。 |
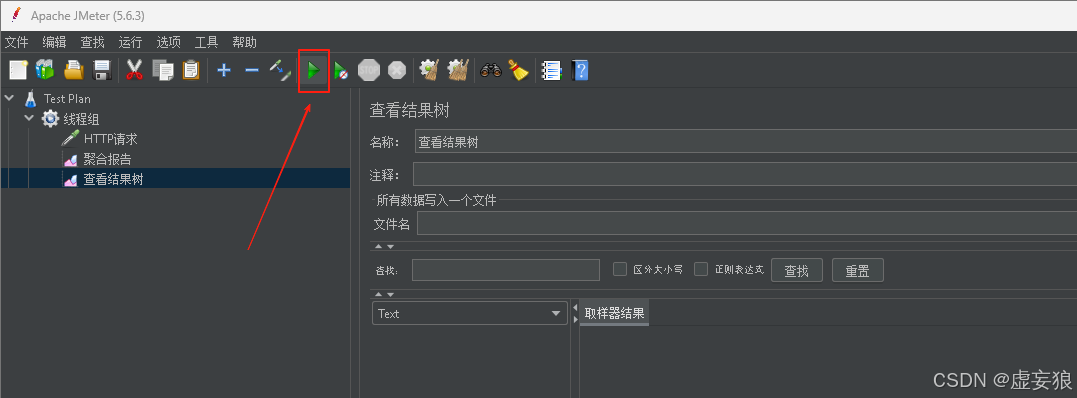
4. 启动测试
2 种启动方式:
- 在顶部导航栏图标下的绿色按钮即可启动/停止
- 右击线程组 --> 启动 (start)
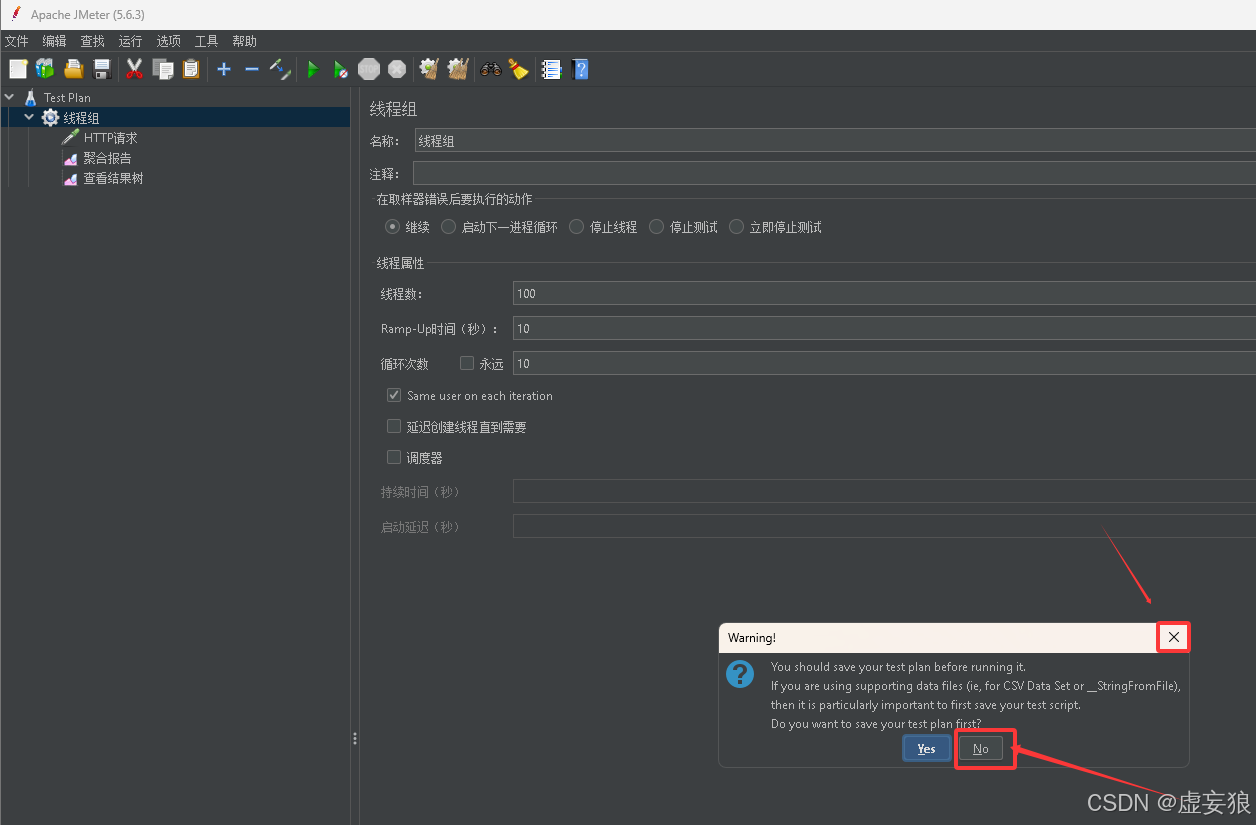
注意:
- 这里让保存现有已配置的信息,可以直接 No 或者 × 掉,但是下次信息无
- 保存配置信息,下次打开
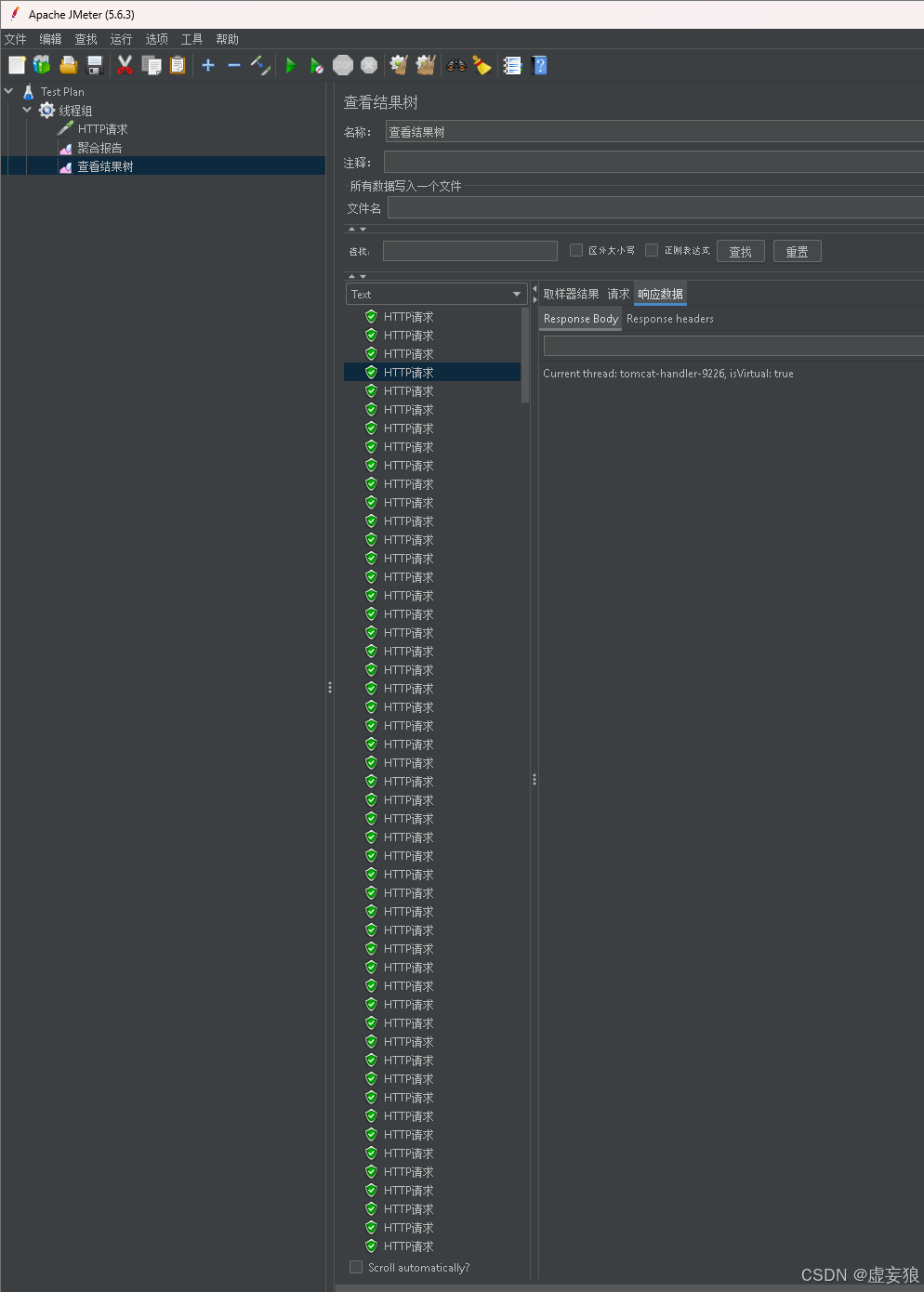
查看结果树:
- 请求:包含请求头、请求体
- 响应:包含响应头、响应体
- 取样结果:可以查看配置信息
聚合报告:

当前测试吞吐量:每秒请求 100次
五、其它操作
1. 清理测试数据
当测试后,我们一般需要清除这一次的数据
- 在顶部导航栏图标下的扫把按钮即可清除当前测试数据,
- 注意两个扫把,需选中监听测试组件 --> 点击
- 另一个直接点击清除全部的扫把按钮
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
网工/运维/测试副业方向
运维网工,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维和网工测试人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
网工运维测试转行学习网络安全路线
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
(三)第三阶段:渗透测试技能学习
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
(四)第四阶段:企业级安全攻防(含红蓝对抗)、应急响应
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
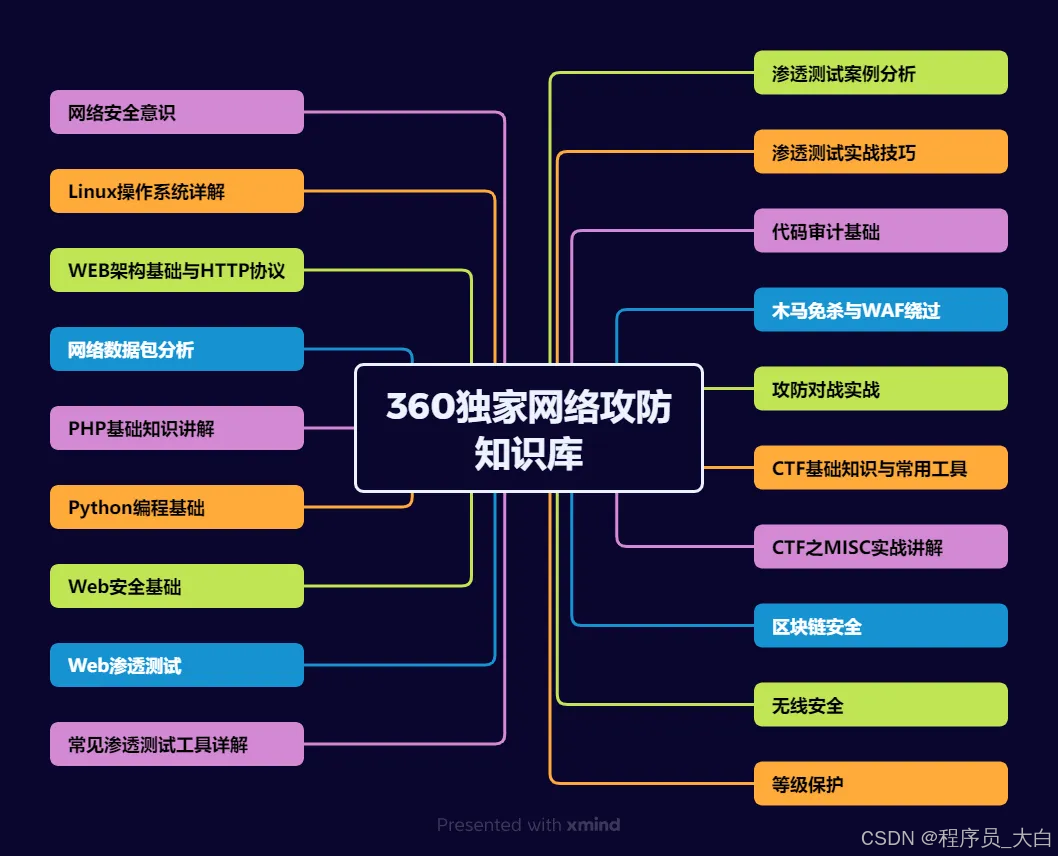
运维网工测试转行网络攻防知识库分享
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧

7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









