







第一次真正体会到 Redis 的威力,是在一个电商项目的秒杀场景里。那时候所有请求都打在数据库上,结果不到一分钟,MySQL 就被打爆,整个系统一片宕机。后来研发临时加了 Redis,把热点商品的库存缓存进去,读写全走内存,系统立刻稳住了。
从那以后,我明白 Redis 的价值:它不是数据库的替代品,而是高并发场景下的“加速器”和“缓冲层”。
👉 数据库保证正确性,而 Redis 保证速度感。
今天这篇,就从安装到调优,带大家走一遍 Redis 运维实战。今天写教程写的眼睛疼,这几天连续长时间盯着屏幕,放几张风景照养养眼吧,相比各大景区拥挤的人群,我更喜欢一个人在河边走走,短暂的自由吧。


Redis 简介与现状
Redis(Remote Dictionary Server)是一个 基于内存的 Key-Value 数据存储,性能极高,功能丰富。
-
快:读写能轻松达到百万级 QPS。
-
多样化数据结构:支持字符串、哈希、列表、集合、有序集合。
-
高可用:支持主从复制、哨兵、集群模式。
-
应用广:缓存、会话存储、分布式锁、排行榜、消息队列……
在现代企业架构里,Redis 已经成为标配。几乎所有中大型系统都会引入它来抗住高并发。

Redis 解决了什么问题?
传统数据库擅长持久化,但在高并发场景下常常成为瓶颈。Redis 的核心价值就是 用内存换性能,帮企业解决:
-
缓存热点数据:把频繁查询的内容放到内存,减轻数据库压力。
-
会话共享:多台应用服务器统一读取用户 Session。
-
分布式锁:用
SETNX实现进程间互斥。 -
计数器 / 排行榜:点赞数、浏览量、排名,Redis 原子操作比数据库轻量高效。
-
消息队列:基于 List 结构可实现简易队列。
👉 一句话总结:
Redis 让高并发场景下的数据读写,既快又稳,为数据库和应用“挡子弹”。

一、环境准备
-
操作系统:Ubuntu 24.04
-
Redis 版本:7.x
-
服务器配置:1 核 1G 也能跑,推荐 2 核 2G
安装 Redis:
apt update
apt install -y redis-server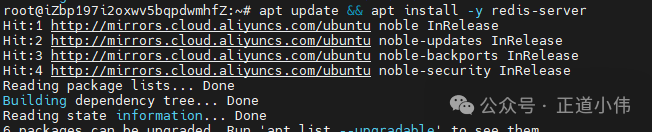

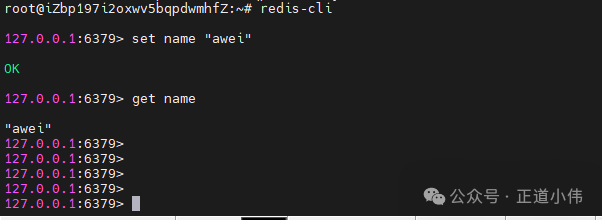
验证:redis-cli
127.0.0.1:6379> set name "awei"
OK
127.0.0.1:6379> get name
"awei"
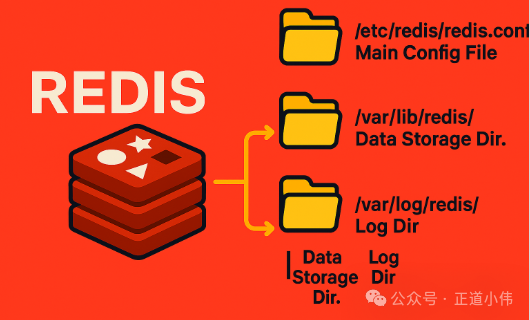
二、目录结构讲解
Redis 默认目录:
-
/etc/redis/redis.conf→ 主配置文件 -
/var/lib/redis/→ 数据存储目录 -
/var/log/redis/→ 日志目录
三、常用操作
Redis 提供了多种数据结构,不仅仅是“key-value”,每种结构都有对应的应用场景。下面用最常见的几个类型做演示。
1. 字符串(String)
最基础的键值对存储,适合缓存单个值。
set name awei
get name
incr counter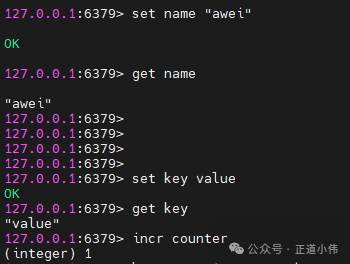
-
set/get→ 存取一个字符串 -
incr→ 自增计数器
💡 应用场景:
-
缓存用户 token / 配置参数
-
统计访问量、点赞数
2. 哈希(Hash)
可以在一个 key 下存多组键值对,就像小字典。
hset user:1 name awei age 30
hgetall user:1
结果:
name → awei
age → 30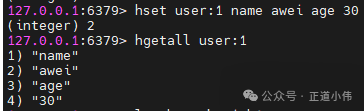
💡 应用场景:
-
存储用户信息、商品属性
-
用
user:1、user:2这种命名组织数据
3. 列表(List)
一个有序链表,可以从头/尾插入或弹出元素。
lpush tasks job1
lpush tasks job2
rpop tasks
执行后:
-
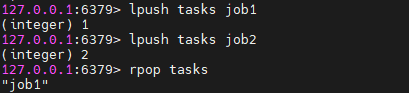
插入
job1、job2到列表 -
从右边取出一个任务
💡 应用场景:
-
简单的消息队列
-
待办任务列表、聊天消息
4. 集合(Set)
无序集合,自动去重。
sadd online_users user1 user2
smembers online_users
💡 应用场景:
-
统计在线用户
-
给用户打标签,天然去重
5. 有序集合(Sorted Set,ZSet)
集合 + 分数,用于排序。
zadd ranking 100 user1
zadd ranking 200 user2
zrevrange ranking 0 -1 withscores
结果:
user2 200
user1 100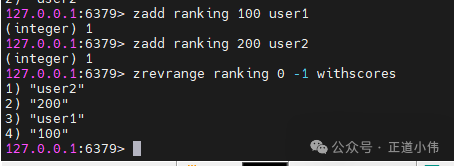
💡 应用场景:-
排行榜(积分、热度、销量)
-
定时任务(分数用作时间戳)
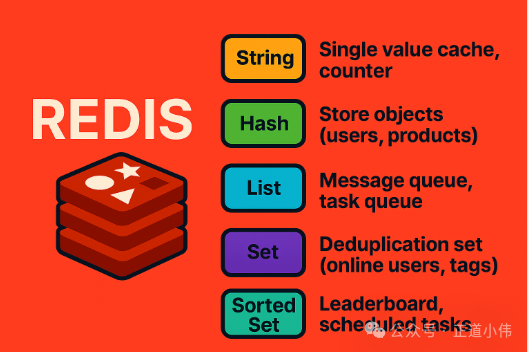
📌 小结:
-
String → 单值缓存、计数器
-
Hash → 存对象(用户、商品)
-
List → 消息队列、任务队列
-
Set → 去重集合(在线用户、标签)
-
Sorted Set → 排行榜、定时任务
四、常用配置
编辑 /etc/redis/redis.conf:
监听地址
bind 0.0.0.0
protected-mode yes
设置密码
requirepass strongpassword
内存限制与淘汰策略
maxmemory 512mb
maxmemory-policy allkeys-lru
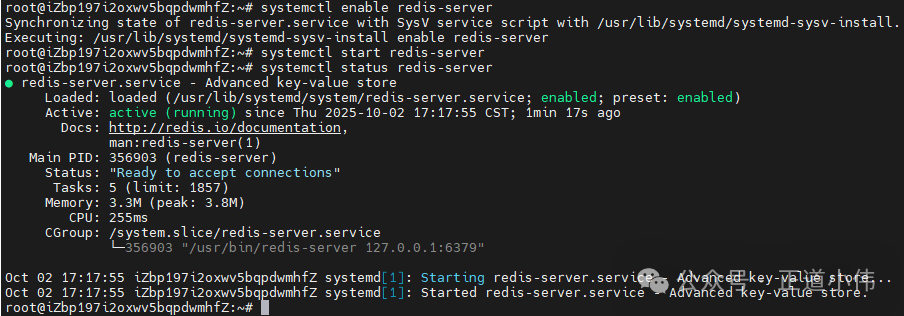
修改后重启:
systemctl restart redis-server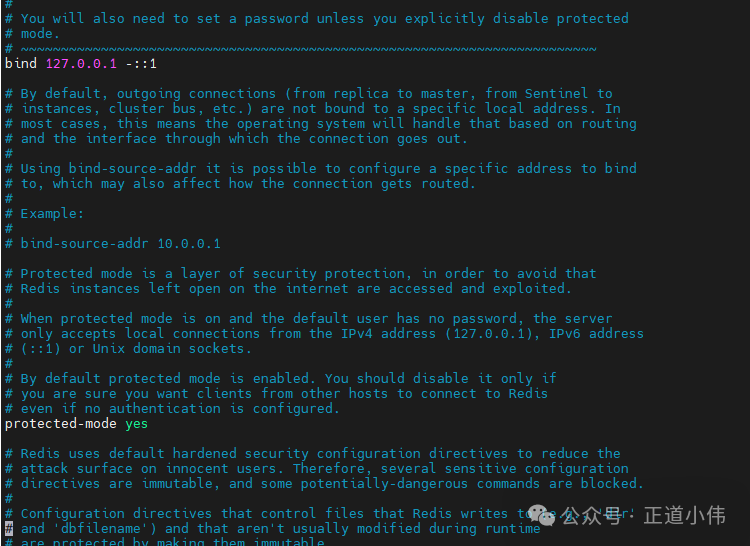
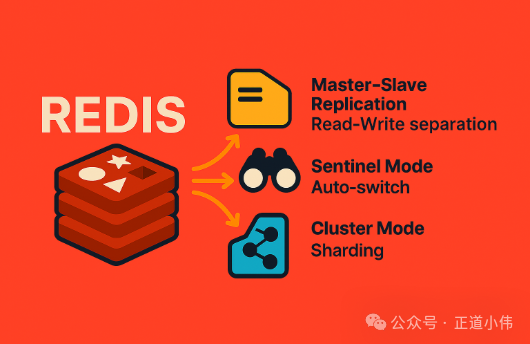
五、高可用初探
在企业里,Redis 很少单机使用,常见的高可用方式有三种:
-
主从复制:读写分离,提升吞吐量。
-
哨兵模式:主节点挂了能自动切换。
-
集群模式:分片存储,支撑海量数据和高并发。
这篇文章只做概览,后续我会单独写《Redis 高可用实战》展开。
常见问题排查(FAQ)
1. Redis 装好后远程连不上
原因:默认只监听 127.0.0.1。
演示排查:
# 查看监听端口
ss -tlnp | grep 6379
如果只看到 127.0.0.1:6379,说明没对外开放。

解决:编辑 /etc/redis/redis.conf,改:
bind 0.0.0.0
protected-mode yes
然后重启:
systemctl restart redis-server
2. 内存被撑爆
原因:Redis 默认没有内存限制,写爆为止。
演示排查:
info memory | grep used_memory_human
如果看到内存占用越来越高,就说明被写满了。
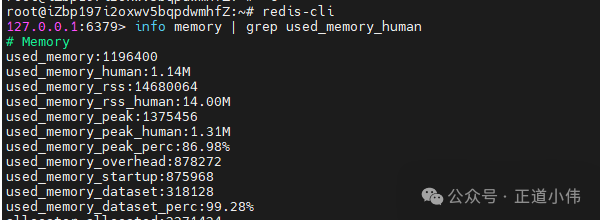
解决:在配置里加:
maxmemory 512mb
maxmemory-policy allkeys-lru
让 Redis 自动淘汰不常用的 key。
3. 数据丢失
原因:RDB 快照是定时写盘,可能丢最后几秒。
演示排查:
# 查看持久化配置
grep save /etc/redis/redis.conf

解决:打开 AOF:
appendonly yes
这样每条写命令都会落盘,代价是性能稍降。
下图rdb开头意思:RDB 在写文件的时候启用 增量 fsync,提升写盘效率,避免一次性卡顿。这个是 OK 的。

4. 命令卡顿
原因:执行了 keys * 这种全表扫描,大量 key 时会阻塞。
演示排查:
keys *
👉 说明 Redis 里当前有 6 个 key,keys * 一次性把它们全扫描出来。
这在测试/小数据量时没问题,但如果是生产环境有百万级 key,就会阻塞整个 Redis,导致线上卡顿。
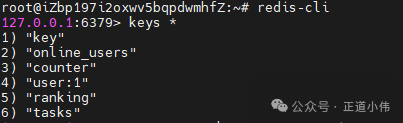
解决:
用 scan 替代:
scan 0 match user:* count 100
分批迭代,避免阻塞。

5. 日志没信息
原因:默认日志级别太低。
演示排查:
tail -f /var/log/redis/redis-server.log我这里没问题

如果几乎没输出,可以在 /etc/redis/redis.conf 里改
loglevel debug
解决:重启后,就能看到详细请求和错误日志。
总结
本文我们完成了:
✅ Redis 的安装与验证
✅ 常见数据结构操作
✅ 配置调优(密码、内存限制)
✅ 高可用模式初探
✅ 常见问题排查
Redis 看似只是“缓存”,但它其实是现代高并发系统的“护心针”。
它的价值不在于取代数据库,而是在于用极快的速度,替数据库挡下洪峰。
就像高速公路上的应急车道,平时你可能意识不到它的存在,但一旦车流爆发,它能瞬间分流、救场。
掌握 Redis,就是掌握了企业系统里应对高并发的加速器。
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
网工/运维副业方向
运维网工,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维和网工人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
网工运维转行学习网络安全路线
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取