







一、oracle建库与删库命令
(1)oracle11g
建库(一般习惯配置gdbname与sid名一样,sys密码与system密码一样,以方便记忆)
[oracledb@ ~]$ dbca -silent -createDatabase -templateName /u01/oracle/product/11.2.0/dbhome_1/assistants/dbca/templates/General_Purpose.dbc -gdbname GDBNAME -sid SIDNAME -characterSet AL32UTF8 -NATIONALCHARACTERSET UTF8 -sysPassword SYSPASSWORD -systemPassword SYSTEMPASSWORD -TOTALMEMORY 2048
删库方法一:
[oracledb@ ~]$ dbca -silent -deleteDatabase -sourceDB SIDNAME -sysDBAUserName sys -sysDBAPassword SYSPASSWORD
删除库方法二:
#步骤1:配置回应文件:
[oracledb@ ~]$ cat /u01/oracle/response/dbca.rsp
OPERATION_TYPE = "deleteDatabase"
SOURCEDB = "SIDNAME"
SYSDBAUSERNAME = "sys"
SYSDBAPASSWORD = "SYSPASSWORD"
#步骤2:执行回应文件删库:
[oracledb@ ~]$ dbca -silent -responseFile /u01/oracle/response/dbca.rsp
(2)oracle12c 建库
[oracledb@ ~]$ dbca -silent -createDatabase -templateName /u01/oracle/product/orahome/assistants/dbca/templates/General_Purpose.dbc -gdbname GDBNAME -sid SIDNAME -characterSet AL32UTF8 -NATIONALCHARACTERSET UTF8 -sysPassword SYSPASSWORD -systemPassword SYSTEMPASSWORD -TOTALMEMORY 2048
#删库命令同上,注意运行删库命令之后,需要手动删除遗留的目录
(3)删除一般会自动删除以下路径或文件中的库信息
A:/u01/oracle/admin/SIDNAME
B:cat /etc/oratab
C:/u01/oracle/oradata/SIDNAME
以下路径需要手动清理
D:/u01/oracle/cfgtoollogs/dbca/SIDNAME
E:/u01/oracle/diag/rdbms/SIDNAME
F:/u01/oracle/product/11.2.0/dbhome_1/dbs/hc_SIDNAME.dat
二、创建库对应的账号密码
1、切换SID
[oracledb@ ~]$ export ORACLE_SID=SIDNAME
2、切换字符集
#查看oracle数据库的字符集
SQL> select userenv('language') from dual;
#查看oracle数据库的编码
SQL> select * from nls_database_parameters where parameter ='NLS_CHARACTERSET';
[oracledb@ ~]$ set NLS_LANG=AMERICAN_AMERICA.AL32UTF8 #windows_os
[oracledb@ ~]$ export NLS_LANG=AMERICAN_AMERICA.AL32UTF8 #linux_os
3、创建库对应的用户信息
SQL> create temporary tablespace SIDNAME_temp tempfile '/u01/oracle/oradata/SIDNAME/SIDNAME_temp.dbf 'size 64m autoextend on next 64m maxsize unlimited extent management local;
SQL> create tablespace SIDNAME_data logging datafile '/u01/oracle/oradata/SIDNAME/SIDNAME_data.dbf' size 64m autoextend on next 64m maxsize 2048m extent management local;
SQL> create user USERNAME identified by USERPASSWORD default tablespace SIDNAME_data temporary tablespace SIDNAME_temp;
SQL> grant connect,resource to USERNAME;
SQL> grant create view to USERNAME;
SQL> grant unlimited tablespace to USERNAME;
SQL> grant create public synonym to USERNAME;
SQL> grant drop public synonym to USERNAME;
SQL> create or replace directory dir_dump as '/u01/oracle/backup';
SQL> grant read,write on directory dir_dump to USERNAME;
SQL> ALTER PROFILE DEFAULT LIMIT PASSWORD_LIFE_TIME UNLIMITED;
—根据实例环境修改processes与sessions参数值(需要重启oracle数据库)
SQL> alter system set processes=1000 scope=spfile;
SQL> alter system set sessions=1105 scope=spfile;
知识点:
-
oracle11g:sessions值的定义应该大于或者定于1.1processes+5,如果小于1.1processes+5,则oracle在启动时自动将该参数设置为1.1processes+5。这主要是考虑到后台进程发起的session和大约10%的递归session。
-
oracle12c:1.1processes+22
#查询当前oracle的并发连接数:
SQL> select count(*) from v$session where status='ACTIVE';
#查看不同用户的连接数:
SQL> select username,count(username) from v$session where username is not null group by username;
#查看所有用户:
select * from all_users;
#当前的连接数
select count(*) from v$process;
#数据库允许的最大连接数
select value from v$parameter where name = 'processes';
三、数据库的还原与备份命令
查看expdp导出备份存储路径:
sql> select * from dba_directories;
1、针对整个库备份与还原操作
-
(1)、数据库的备份(注意有时SIDNAME与SCHEMASNAME不一致,要注意使用时区分,一般配置一样的名称,方便记忆的同时,也方便运维。parallel参数根据服务器内存等配置情况添加合理的数值。)
#备份:
[oracledb@ ~]$ expdp USERNAME/USERPASSWORD@SIDNAME schemas=SCHEMASNAME dumpfile=SIDNAME`date +%Y%m%d`.dmp directory=dir_dump parallel=2
12
-
(2)、还原
情况1、原始库与目标库实例名不同(注意有些环境的数据表空间名不是SIDNAME_data,使用时注意核实)
#格式:
[oracledb@ ~]$ impdp USERNAME/USERPASSWORD@SIDNAME schemas=SCHEMASNAME DUMPFILE=XXXX.dmp DIRECTORY=dir_dump remap_schema=源SCHEMASNAME:目标SCHEMASNAME remap_tablespace=源_data:目标_data
情况2:源库与目标库实例名相同
#格式:
[oracledb@ ~]$ impdp USERNAME/USERPASSWORD@SIDNAME schemas=SCHEMASNAME DUMPFILE=XXXX.dmp DIRECTORY=dir_dump EXCLUDE=STATISTICS
知识扩展:使用EXCLUDE=STATISTICS还原时排除统计,可以使用如下命令完成统计
#命令如下:
SQL> exec dbms_stats.gather_schema_stats(ownname=>'SIDNAME',estimate_percent=>10,degree=>8,cascade=>true,granularity=>'ALL');
2、针对单表备份与还原操作
-
(1)、备份单表
格式:
[oracledb@ ~]$ expdp USERNAME/USERPASSWORD@SIDNAME dumpfile=tablenameXXXX.dmp DIRECTORY=dir_dump tables=TABLENAME
-
(2)、还原单表
#格式:
[oracledb@ ~]$ impdp USERNAME/USERPASSWORD@SIDNAME dumpfile=tablenameXXXX.dmp DIRECTORY=dir_dump TABLES=TABLENAME TABLE_EXISTS_ACTION=REPLACE
扩展:table_exists_action参数说明
使用imp进行数据导入时,若表已经存在,要先drop掉表,再进行导入。
而使用impdp完成数据库导入时,若表已经存在,有四种的处理方式:
参数(1) skip:默认操作
参数(2) replace:先drop表,然后创建表,最后插入数据
参数(3) append:在原来数据的基础上增加数据
参数(4) truncate:先truncate,然后再插入数据
-
(3)备份多张表
#格式:
[oracledb@ ~]$ expdp USERNAME/USERPASSWORD@SIDNAME dumpfile=tablenameXXXX.dmp DIRECTORY=dir_dump TABLES=源TABLENAME1,源TABLENAME2,.....
-
(4)还原多张表
#格式:
[oracledb@ ~]$ impdp USERNAME/USERPASSWORD@SIDNAME dumpfile=tablenameXXXX.dmp DIRECTORY=dir_dump remap_table=源TABLENAME1:目标TABLENAME11 TABLE_EXISTS_ACTION=REPLACE
[oracledb@ ~]$ impdp USERNAME/USERPASSWORD@SIDNAME dumpfile=tablenameXXXX.dmp DIRECTORY=dir_dump remap_table=源TABLENAME2:目标TABLENAME22 TABLE_EXISTS_ACTION=REPLACE
3、扩展知识
-
1)扩展1:
情况1、高版本往低版本导出还原时,如12往11还原时,在12c执行导出时,添加低版本的版本号version=11.1.0.2.0
#格式:
[oracledb@ ~]$ expdp USERNAME/USERPASSWORD@SIDNAME schemas=SCHEMASNAME dumpfile=XXX.dmp DIRECTORY=dir_dump version=11.1.0.2.0
情况2、低版本往高版本还原时,高版本一般兼容低版本,目前个人运维工作中11往12还原没遇到什么问题。
-
2)扩展2:
(1)、按指定大小备份,如每份5G大小(parallel是多线程处理,线程数要小于生成文件个数,线程要小于 cpu 线程数)
#备份格式
[oracledb@ ~]$ expdp USERNAME/USERPASSWORD@SIDNAME schemas=SCHEMASNAME DIRECTORY=dir_dump dumpfile=XXX_%U.dmp logfile=expdpXXX.log filesize=5G parallel=16
(2)、多个备份文件还原:
#还原格式
[oracledb@ ~]$ impdp USERNAME/USERPASSWORD@SIDNAME schemas=SCHEMASNAME DIRECTORY=dir_dump dumpfile=XXX_%U.dmp logfile=impdpXXX.log parallel=16
3)扩展3
导出过滤不导出某张表:
#格式
[oracledb@ ~]$ expdp USERNAME/USERPASSWORD@SIDNAME schemas=SCHEMASNAME DIRECTORY=dir_dump dumpfile=XXX.dmp exclude=TABLE:\"IN \'TABLENAME\'\"
4)扩展4
不同库还原时不改变数据结构使用truncate参数:
#格式
[oracledb@ ~]$ impdp USERNAME/USERPASSWORD@SIDNAME schemas=SCHEMASNAME DIRECTORY=dir_dump dumpfile=XXX.dmp remap_schema=源SCHEMASNAME:目标SCHEMASNAME remap_tablespace=源_data:目标_data TABLE_EXISTS_ACTION=truncate
5)扩展5
导出备份时保留表,清除表数据(query参数):
#格式
[oracledb@ ~]$ expdp USERNAME/USERPASSWORD@SIDNAME schemas=SCHEMASNAME DIRECTORY=dir_dump dumpfile=XXX.dmp logfile=expdpXXX.log query=TABLENAME1:'" where 1=2"',TABLENAME2:'" where 1=2"',........
6)扩展6
导出备份时保留表,清除表数据,同时过滤某两张表
#格式
[oracledb@ ~]$ expdp USERNAME/USERPASSWORD@SIDNAME schemas=SCHEMASNAME DIRECTORY=dir_dump dumpfile=XXX.dmp logfile=expdpXXX.log query=TABLENAME1:'" where 1=2"',TABLENAME2:'" where 1=2"' exclude=TABLE:\"IN \'TABLENAME1\'\'TABLENAME2\'\"
7)扩展7
仅统计数据库各表数据,但不导出,参数estimate_only=y
#格式
[oracledb@ ~]$ expdp USERNAME/USERPASSWORD@SIDNAME schemas=SCHEMASNAME DIRECTORY=dir_dump estimate_only=y
8)扩展8
导入单表到某临时表:
#格式(涉及统计与索引时添加参数EXCLUDE=STATISTICS EXCLUDE=INDEX)
—sql实现从这张表复制到另一张临时表
SQL> CREATE TABLE 目标TABLENAME AS (SELECT * FROM 源TABLENAME);
—清空表中的数据
SQL> delete from 目标TABLENAME;
[oracledb@ ~]$ impdp USERNAME/USERPASSWORD@SIDNAME DIRECTORY=dir_dump DUMPFILE=tablenameXXX.dmp remap_table=源TABLENAME:目标TABLENAME TABLE_EXISTS_ACTION=REPLACE EXCLUDE=STATISTICS EXCLUDE=INDEX
[oracledb@ ~]$ expdp USERNAME/USERPASSWORD@SIDNAME schemas=SCHEMASNAME ESTIMATE_ONLY=y NOLOGFILE=y FULL=y
9)扩展9
个别sql脚本内容很长,使用PLSQL Developer工具执行时会一直卡住无响应时除使用PLSQL Developer工具的在命令窗口中执行外,也可以使用shell终端执行
#格式
[oracle@localhost ~]$ export ORACLE_SID=SIDNAME
[oracle@localhost ~]$ sqlplus / as sysdba
sql> conn USERNAME/USERPASSWORD@SIDNAME
sql> @/u01/oracle/backup/XXX.sql
10)扩展10
如何正确终止expdp与impdp任务,操作步骤如下:
步骤1、查看视图dba_datapump_jobs
select job_name,state from dba_datapump_jobs;
步骤2、正确停止expdp导出任务使用stop_job
expdp USERNAME/USERPASSWORD@SIDNAME attach=SYS_EXPORT_SCHEMA_02
步骤3、停止任务
Export> stop_job=immediate
Are you sure you wish to stop this job ([yes]/no): yes
步骤4、查看系统中的备份job状态
select owner_name,job_name ,state from dba_datapump_jobs;
扩展:下列命令在交互模式下有效:
HELP: 总结交互命令。
KILL_JOB: 分离和删除作业。
PARALLEL: 更改当前作业的活动 worker 的数目。
PARALLEL=.2
START_JOB: 启动/恢复当前作业。
START_JOB=SKIP_CURRENT 在开始作业之前将跳过作业停止时执行的任意操作。
STATUS :在默认值(0)将显示可用时的新状态的情况下,要监视的频率(以秒计)作业状态。
STATUS[=interval]
STOP_JOB: 顺序关闭执行的作业并退出客户机。
STOP_JOB=IMMEDIATE 将立即关闭数据泵作业。
11)扩展11
#查看DB中的NLS_CHARACTERSET的值
SQL> select * from v$nls_parameters where parameter='NLS_CHARACTERSET';
SQL> select * from nls_database_parameters t where t.parameter='NLS_CHARACTERSET';
12)扩展12
关于exp、imp、expdp、impdp
(1)、exp和imp是客户端工具程序,它们既可以在客户端使用,也可以在服务端使用。
(2)、expdp和impdp是服务端的工具程序,他们只能在oracle服务端使用,不能在客户端使用。
(3)、imp只适用于exp导出的文件,不适用于expdp导出文件;impdp只适用于expdp导出的文件,而不适用于exp导出文件。
(4)、对于10g以上的服务器,使用exp通常不能导出0行数据的空表,而此时必须使用expdp导出。
13)扩展13
oracle用户密码有@符号时,expdp与sqlplus连接方式及使用rar压缩备份的文件
@echo off
rem ---- dmp backup directory, same as dump dir
set backup_dir=e:\app\oracle\backup
rem ---- today, day for dmp file remaining
set day=%date:~0,4%%date:~5,2%%date:~8,2%
set remain_day=7
rem --- delete files before 7 days
forfiles /p "%backup_dir%" /d -%remain_day% /c "cmd /c del /f @path"
rem --- export oracle data to dmp file
expdp 用户名/\"xxx@yyy\"@orcl directory=dir_dump dumpfile=用户名_%day%.dmp logfile=用户名_%day%.log schemas=用户名 parallel=4 compression=ALL
rem --- sqlplus conn
sqlplus 用户名/"""xxx@yyy"""@orcl
rem ---- if compress the dumpfile and delete source dumpfile, unmark rem
set rar="C:\Program Files (x86)\WinRAR\WinRAR.exe"
%rar% a -df %backup_dir%\用户名_%day%.rar %backup_dir%\用户名_%day%.dmp %backup_dir%\用户名_%day%.log
四、清理(还原时出错,清用户表空间)
1、删除数据表空间:
#执行语句:
[oracledb@ ~]$ sqlplus / as sysdba
SQL> drop tablespace mepro_data including contents and datafiles cascade constraint;
2、删除临时表空间:
#执行语句:
SQL> drop tablespace mepro_temp including contents and datafiles cascade constraints;
3、删除用户:
#执行语句:
SQL> drop user srmhdld cascade;
4、报用户正在连接,无法删除的解决方法
---方法1:重启并迅速执行drop user语句(个人推荐)
SQL> shutdown immediate;
SQL> startup
---方法2:删除正在连接的session(连接的session连接着很多时,清理耗时,没有方法1快速)
#查询用户会话
SQL> select username,serial#,sid,program,machine,status from v$session where username='USERNAME' AND STATUS='ACTIVE';;
SQL> select saddr,sid,serial#,paddr,username,status from v$session where username is not null;
---删除相关用户会话
SQL> alter system kill session 'serial#, sid';
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维副业方向
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
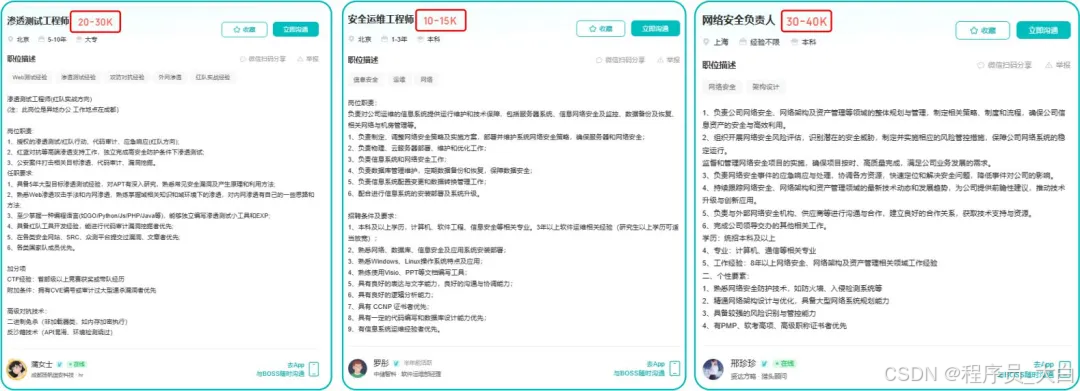
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
运维转行学习路线
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取