







========================================================================================================================================================================
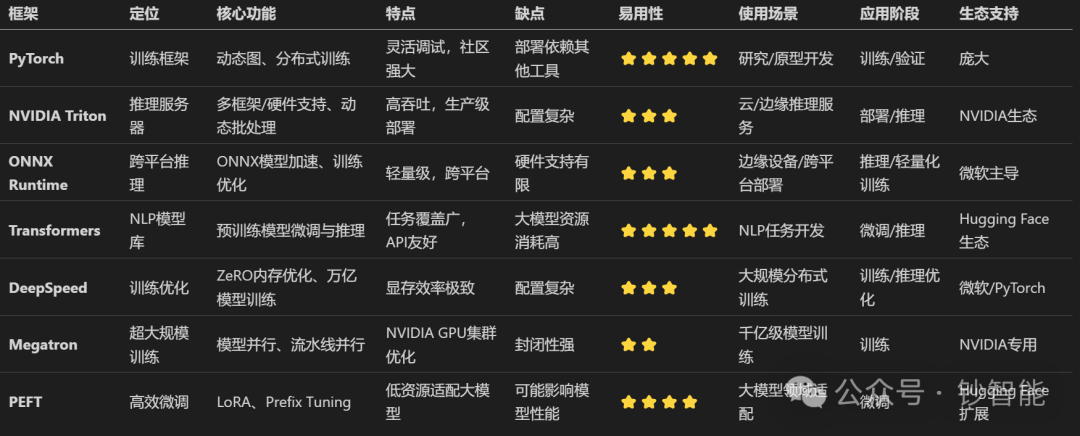
框架对比分析
- PyTorch
-
官网链接:pytorch.org
-
定位:动态图优先的深度学习框架,以灵活性和研究友好性著称。
-
核心功能:
-
动态计算图(即时执行)。
-
张量计算、自动求导、分布式训练。
-
特点:
-
与Python深度集成,调试便捷。
-
支持GPU加速和混合精度训练。
-
缺点:
-
生产部署需依赖TorchScript/ONNX。
-
训练速度较静态图框架(如TensorFlow)略慢。
-
易用程度:⭐️⭐️⭐️⭐️⭐️(适合快速原型开发)。
-
使用场景:学术研究、模型实验、小规模训练。
-
应用阶段:模型训练与验证。
-
生态:与Hugging Face、ONNX、TensorBoard集成,社区庞大。
-
简单用法:
`import torch model = torch.nn.Linear(10, 2) output = model(torch.randn(3, 10))`
- NVIDIA Triton
-
官网链接:github.com/triton-inference-server
-
定位:高性能AI推理服务器,支持多框架、多硬件部署。
-
核心功能:
-
动态批处理、并发模型执行。
-
支持TensorFlow、PyTorch、ONNX等模型。
-
特点:
-
跨框架和硬件(GPU/CPU/TPU)兼容。
-
集成Kubernetes和Prometheus。
-
缺点:配置复杂,需管理模型仓库和YAML文件。
-
易用程度:⭐️⭐️⭐️(适合生产环境专家)。
-
使用场景:云/边缘推理服务、高吞吐在线服务。
-
应用阶段:模型部署与推理。
-
生态:与NVIDIA生态(TensorRT、CUDA)深度绑定。
-
简单用法:
`docker run --gpus=1 -v/path/to/models:/models nvcr.io/nvidia/tritonserver:24.02-py3 tritonserver --model-repository=/models`
- ONNX Runtime
-
官网链接:onnxruntime.ai
-
定位:跨平台推理加速引擎,支持ONNX格式模型。
-
核心功能:
-
高性能推理(CPU/GPU/FPGA)。
-
训练加速(ORTModule)。
-
特点:
-
轻量级,适合嵌入式设备。
-
与PyTorch/TensorFlow无缝转换。
-
缺点:部分硬件加速器支持有限。
-
易用程度:⭐️⭐️⭐️(需熟悉模型转换)。
-
使用场景:跨平台部署、边缘设备推理。
-
应用阶段:模型推理与轻量化训练。
-
生态:微软主导,与Azure云服务集成。
-
简单用法:
`import onnxruntime as ort sess = ort.InferenceSession("model.onnx") outputs = sess.run(None, {"input": input_data})`
- Transformers(Hugging Face)
-
官网链接:huggingface.co/transformers
-
定位:NLP预训练模型库,覆盖文本生成、分类等任务。
-
核心功能:
-
提供BERT、GPT等模型的微调接口。
-
支持PyTorch、TensorFlow、JAX。
-
特点:
-
API设计简洁,模型库丰富。
-
支持快速迁移学习和部署。
-
缺点:大模型显存占用高。
-
易用程度:⭐️⭐️⭐️⭐️⭐️(开箱即用)。
-
使用场景:NLP任务开发、快速原型验证。
-
应用阶段:模型微调与推理。
-
生态:Hugging Face Hub(数千预训练模型)。
-
简单用法:
`from transformers import pipeline classifier = pipeline("text-classification", model="distilbert-base-uncased") result = classifier("I love using Transformers!")`
- Accelerate(Hugging Face)
-
官网链接:huggingface.co/docs/accelerate
-
定位:简化分布式训练的工具库。
-
核心功能:
-
自动化多GPU/TPU配置。
-
混合精度训练支持。
-
特点:
-
无需修改代码即可扩展训练规模。
-
与DeepSpeed兼容。
-
缺点:功能较基础,复杂场景需结合其他工具。
-
易用程度:⭐️⭐️⭐️⭐️(快速上手)。
-
使用场景:单机多卡/多节点训练。
-
应用阶段:模型训练。
-
生态:Hugging Face生态核心组件。
-
简单用法:
`accelerate config # 配置分布式环境 accelerate launch train.py # 启动训练`
- DeepSpeed(Microsoft)
-
官网链接:deepspeed.ai
-
定位:大规模模型训练与推理优化库。
-
核心功能:
-
ZeRO内存优化、梯度累积。
-
支持万亿参数模型训练。
-
特点:
-
显存优化显著,适合超大模型。
-
提供推理加速工具(如DeepSpeed-Inference)。
-
缺点:配置复杂,学习曲线陡峭。
-
易用程度:⭐️⭐️⭐️(需分布式知识)。
-
使用场景:千亿级模型训练(如GPT-3)。
-
应用阶段:训练与推理优化。
-
生态:与PyTorch、Hugging Face集成。
-
简单用法:
`import deepspeed model_engine, optimizer, _, _ = deepspeed.initialize( model=model, optimizer=optimizer, config="ds_config.json" )`
- Megatron(NVIDIA)
-
官网链接:github.com/NVIDIA/Megatron-LM
-
定位:超大规模语言模型训练框架。
-
核心功能:
-
模型并行、流水线并行。
-
Transformer架构极致优化。
-
特点:
-
专为NVIDIA GPU集群设计。
-
支持混合精度和梯度检查点。
-
缺点:仅支持NVIDIA硬件,封闭性强。
-
易用程度:⭐️⭐️(需定制开发)。
-
使用场景:千亿参数级模型训练。
-
应用阶段:大规模训练。
-
生态:NVIDIA专用工具链(CUDA、A100/H100)。
-
简单用法:
`python -m torch.distributed.launch pretrain_gpt.py --tensor-model-parallel-size 4 --pipeline-model-parallel-size 2`
- PEFT(Parameter-Efficient Fine-Tuning)
-
官网链接:github.com/huggingface/peft
-
定位:大模型高效微调工具库。
-
核心功能:
-
LoRA、Prefix Tuning等微调技术。
-
减少可训练参数至1%-10%。
-
特点:
-
资源需求低,适合单卡微调。
-
与Transformers无缝集成。
-
缺点:部分技术可能影响模型性能。
-
易用程度:⭐️⭐️⭐️⭐️(API简洁)。
-
使用场景:大模型领域适配(如医疗、金融)。
-
应用阶段:模型微调。
-
生态:Hugging Face生态扩展。
-
简单用法:
`from peft import LoraConfig, get_peft_model peft_config = LoraConfig(r=8, lora_alpha=16) model = get_peft_model(model, peft_config)`
- torchrun(PyTorch)
-
官网链接:pytorch.org/docs/stable/elastic/run.html
-
定位:PyTorch分布式训练启动工具。
-
核心功能:
-
自动化多节点训练配置。
-
支持弹性训练(节点动态扩缩容)。
-
特点:
-
替代
torch.distributed.launch,更简洁。 -
缺点:功能较基础,需配合其他工具。
-
易用程度:⭐️⭐️⭐️(需分布式知识)。
-
使用场景:多机多卡训练任务。
-
应用阶段:模型训练。
-
生态:PyTorch原生工具链。
-
简单用法:
`torchrun --nproc_per_node=4 --nnodes=2 train.py`
- Unsloth
-
官网链接:github.com/unslothai/unsloth
-
定位:大模型高效微调框架。
-
核心功能:
-
显存优化,训练速度提升2-5倍。
-
支持LoRA等高效微调技术。
-
特点:
-
兼容Hugging Face模型,无需修改架构。
-
缺点:社区较新,文档较少。
-
易用程度:⭐️⭐️⭐️⭐️(API友好)。
-
使用场景:资源受限环境下的微调。
-
应用阶段:模型微调。
-
生态:与Hugging Face兼容。
-
简单用法:
`from unsloth import FastLanguageModel model, tokenizer = FastLanguageModel.from_pretrained("unsloth/llama-2-7b")`
- vLLM
-
官网链接:github.com/vllm-project/vllm
-
定位:大模型高吞吐推理引擎。
-
核心功能:
-
PagedAttention技术优化KV缓存。
-
连续批处理和量化支持。
-
特点:
-
吞吐量比Hugging Face提升24倍。
-
支持张量并行和流式输出。
-
缺点:仅支持Transformer架构模型。
-
易用程度:⭐️⭐️⭐️(需CUDA环境)。
-
使用场景:高并发在线服务(如ChatGPT类应用)。
-
应用阶段:模型推理。
-
生态:与Hugging Face模型兼容。
-
简单用法:
`from vllm import LLM llm = LLM(model="meta-llama/Llama-2-7b-hf") outputs = llm.generate(["Hello, my name is"])`
- Ollama
-
官网链接:ollama.ai
-
定位:本地大模型部署工具。
-
核心功能:
-
本地运行LLaMA、Mistral等模型。
-
提供CLI和API接口。
-
特点:
-
轻量级,无需云服务。
-
支持多平台(Mac/Linux/Windows)。
-
缺点:模型支持范围有限。
-
易用程度:⭐️⭐️⭐️⭐️⭐️(一键运行)。
-
使用场景:本地开发测试、隐私敏感场景。
-
应用阶段:模型部署与推理。
-
生态:活跃的开源社区。
-
简单用法:
`ollama run llama2 # 下载并运行模型`
- llama.cpp
-
官网链接:github.com/ggerganov/llama.cpp
-
定位:本地CPU/GPU推理引擎。
-
核心功能:
-
模型量化(GGUF格式)。
-
低资源推理。
-
特点:
-
无需GPU,内存效率高。
-
支持Metal(Apple Silicon)和CUDA。
-
缺点:仅限推理,不支持训练。
-
易用程度:⭐️⭐️⭐️(需编译和量化模型)。
-
使用场景:边缘设备部署、移动端推理。
-
应用阶段:模型推理。
-
生态:广泛支持第三方客户端(如LMStudio)。
-
简单用法:
`./main -m models/llama-2-7b.Q4_K_M.gguf -p "Hello"`
- Ray Serve
-
官网链接:docs.ray.io/en/latest/serve/
-
定位:可扩展模型服务化框架。
-
核心功能:
-
多模型组合、自动扩缩容。
-
支持A/B测试和复杂流水线。
-
特点:
-
与Ray生态(数据处理、训练)无缝集成。
-
缺点:学习成本较高。
-
易用程度:⭐️⭐️⭐️(需熟悉Ray API)。
-
使用场景:云原生模型服务、实时推理流水线。
-
应用阶段:模型部署与服务化。
-
生态:Ray生态的一部分,支持多框架。
-
简单用法:
`from ray import serve @serve.deployment class MyModel: def __call__(self, request): return "Hello World!" serve.run(MyModel.bind())`
|
## AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版优快云大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版优快云大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版优快云大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版优快云大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版优快云大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 5561
5561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









