







ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,具有对话流畅、部署门槛低等众多优秀特性。本文将从零开始,讲解ChatGLM3-6b的部署及使用,全文一共2000多字,篇幅较长,主要包括以下六个部分:
一、下载项目代码和模型文件****
二、安装miniconda
三、创建conda环境
四、根据cuda版本来 选择合适的pytorch版本
五、运行chatglm相关的服务
六、FastGPT知识库问答使用 本地 chatglm服务
本文实验的配置:
GPU:英伟达 3090 24G显存
操作系统:centos 7
一、下载项目代码和模型文件
1、代码地址:
https://github.com/THUDM/ChatGLM3
2、下载对应的模型文件
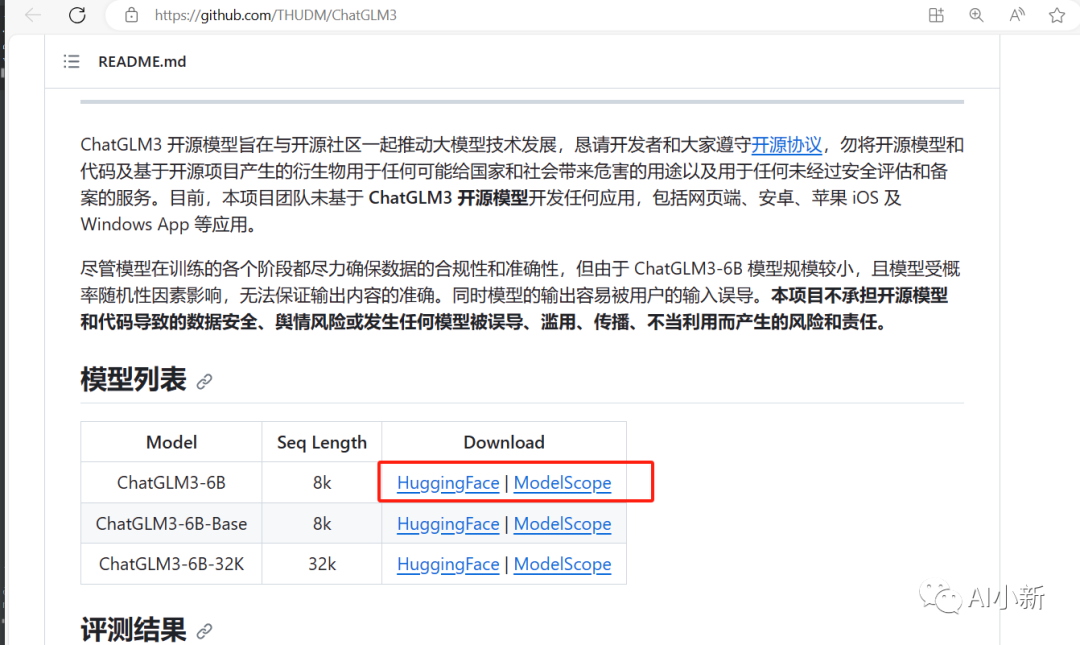
modelscope对应的模型地址:
https://modelscope.cn/models/ZhipuAI/chatglm3-6b/files
可以使用如下的 git命令进行下载:
git lfs install``git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
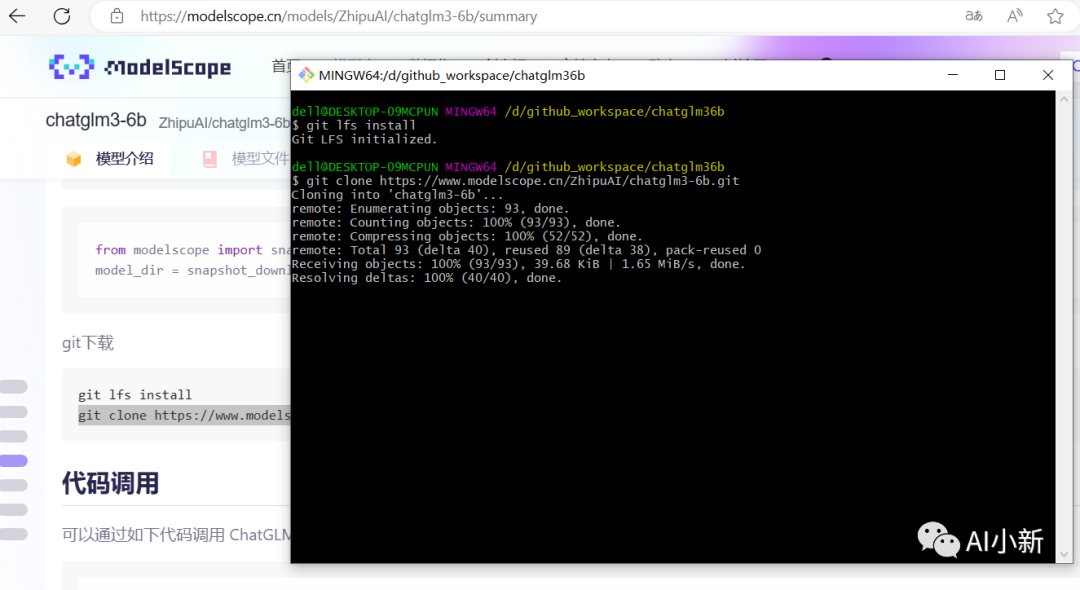
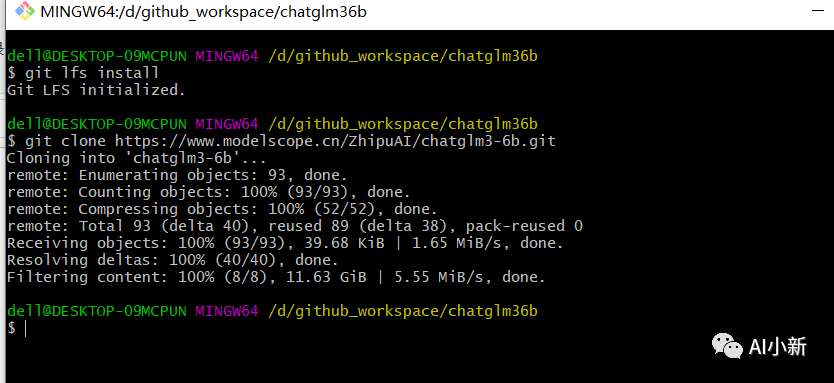
文件大小11.64G,根据个人网速不同,本人 大约等待30分钟后,下载完成;
下载完成后,将代码和对应的模型文件传到服务器上,作者是将模型文件放在项目代码的根目录。
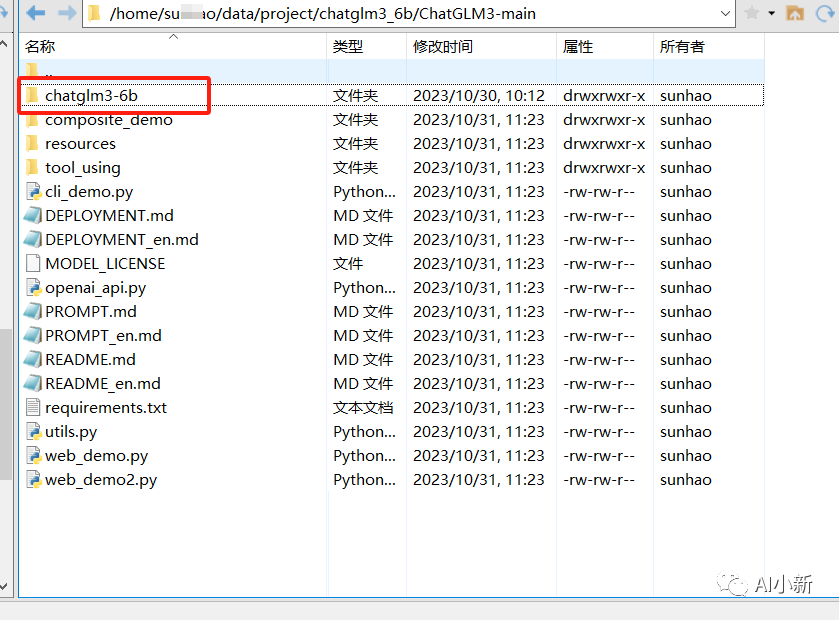
二、安装miniconda
-------若已安装miniconda或者conda可以跳过 这节------------
1、安装最新版本的 miniconda
wget http://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh

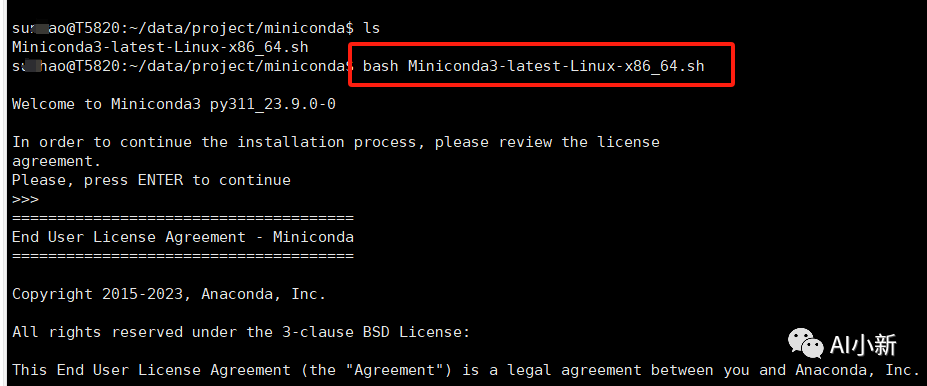
2、执行安装
bash Miniconda3-latest-Linux-x86_64.sh
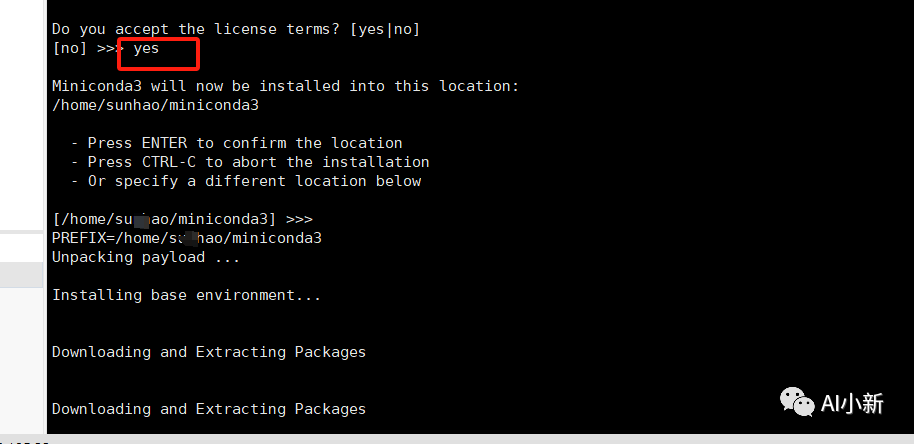
输入enter ,一路yes即可
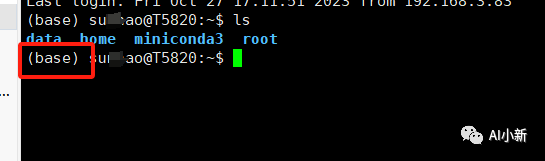
安装完成后,关闭shell窗口,重新打开,就可以看到已经装好了
三、创建conda环境
创建一个conda环境,用于安装大模型运行的依赖包
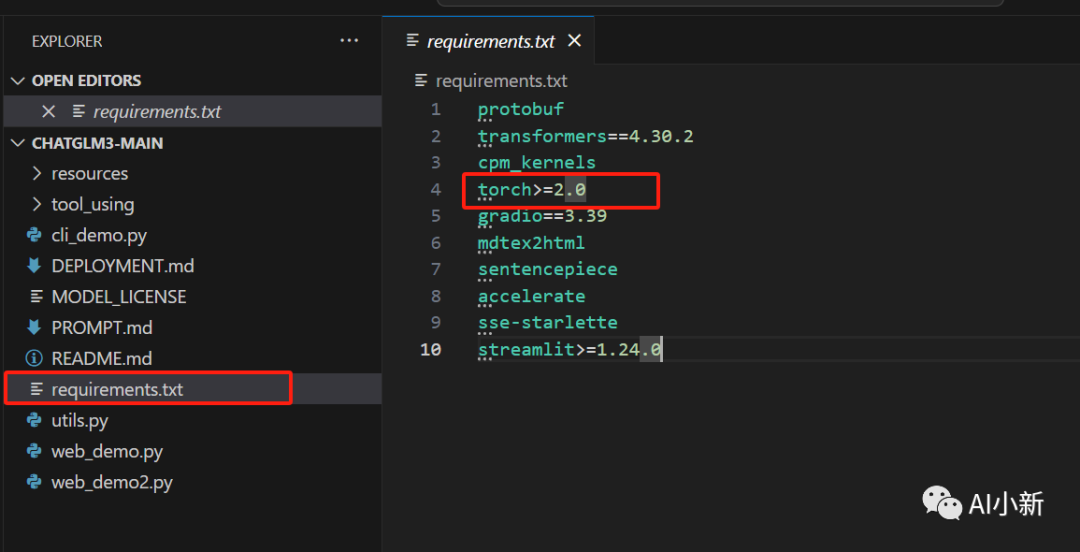
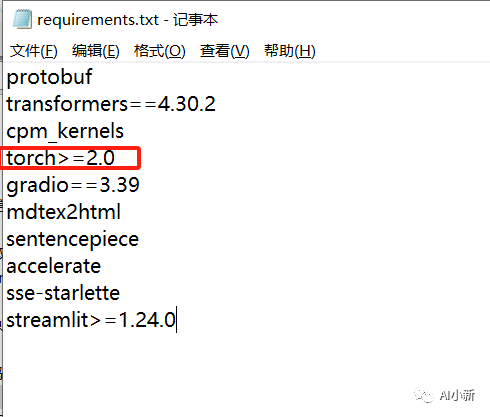
3.1 首先看到requirements.txt,可以看到官网推荐的torch版本>=2.0,但是当torch==1.13.1时也可以运行,看你们自己的选择。
3.2 选择合适的python的版本
python与pytorch版本的对应关系如下:
https://github.com/pytorch/vision#installation

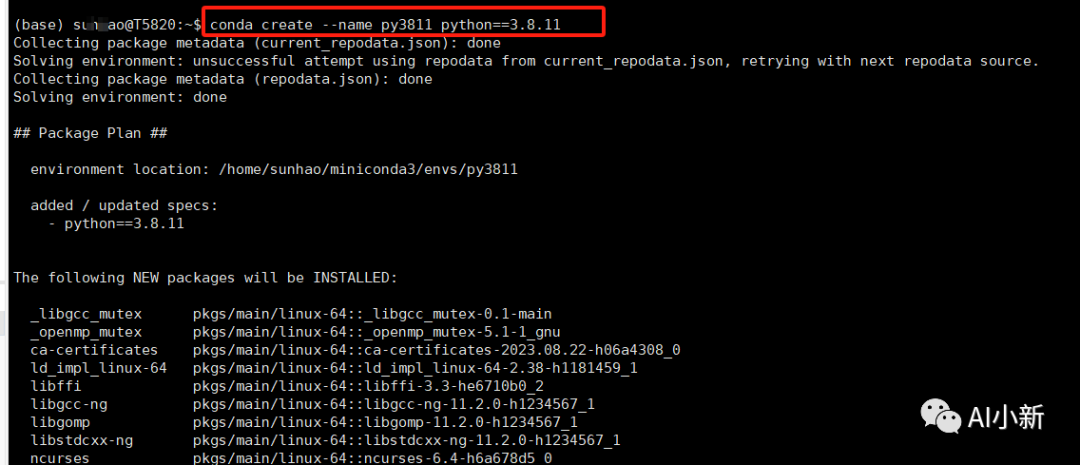
3.3 选择的 python版本大于3.8,使用如下命令进行创建conda环境。
conda create --name py3811 python==3.8.11
3.4 激活创建好的conda环境:
conda activate py3811

四、根据显卡cuda的版本来 选择合适的pytorch版本
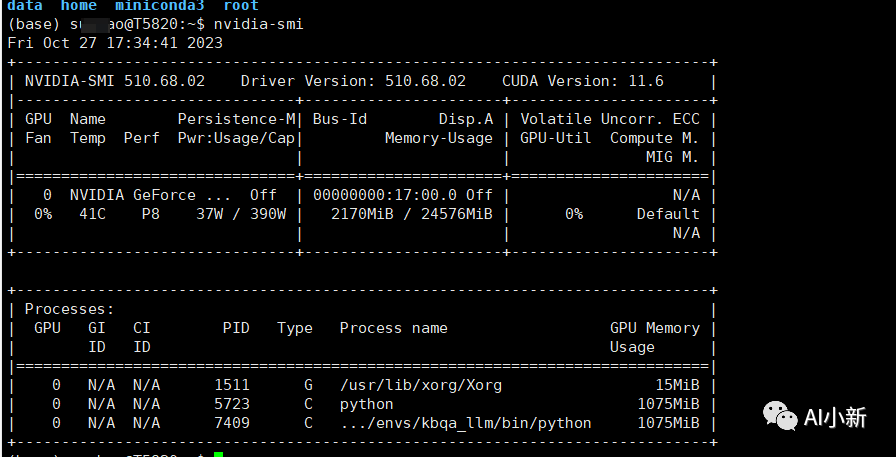
4.1、查看 显卡信息
nvidia-smi
ps:如何安装cuda及cudnn,可自行百度安装,本文不再讲述。
从官网选择合适的pytorch版本:
地址:https://pytorch.org/get-started/previous-versions/
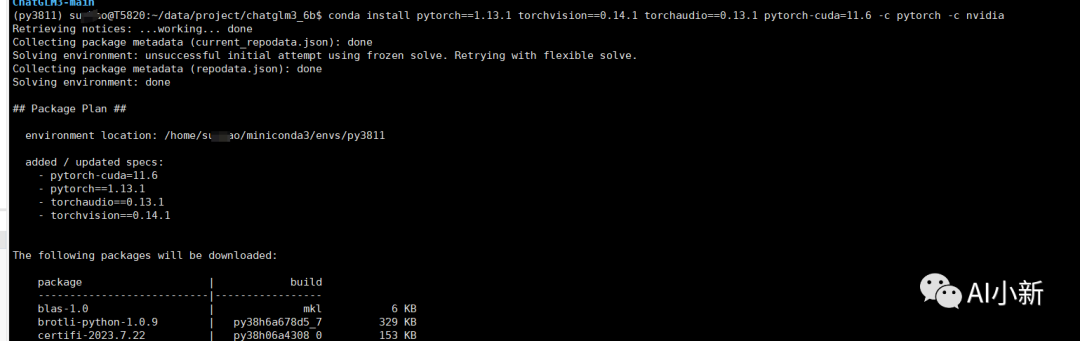
因为作者的显卡cuda版本为11.6,所以选择 torch==1.13.1的版本;
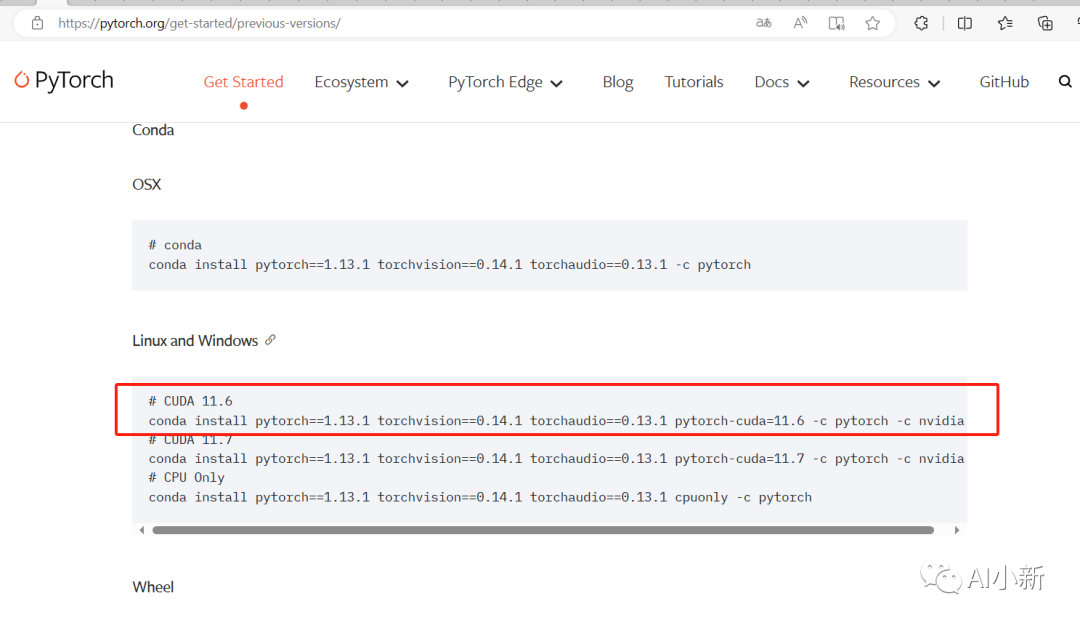
4.2 cuda为11.6 的pytorch安装命令
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia
如果你的显卡cuda版本为11.7或者11.8,你可以选择torch>=2.0的版本
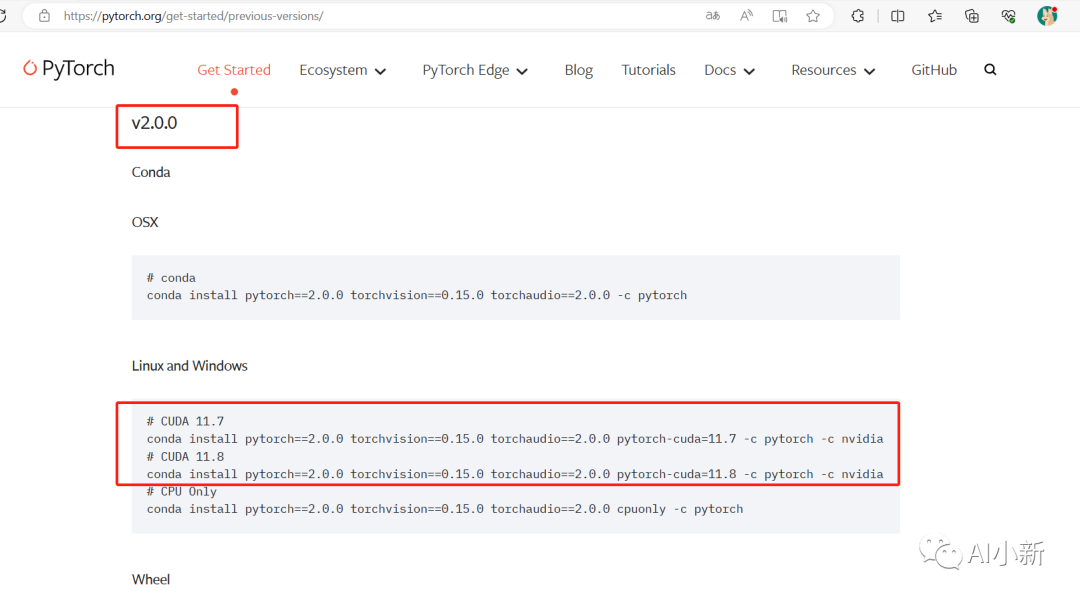
4.3 cuda为11.7或者11.8的pytorch安装命令
# CUDA 11.7``conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia``# CUDA 11.8``conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
4.4 本文采用cuda为11.6 的pytorch安装命令
4.5 进入代码目录,安装依赖包
作者的torch版本为1.13.1,所以删除掉 requirements.txt 中的红框部分,如果你的torch大于2.0 ,则不需要删除这一行。
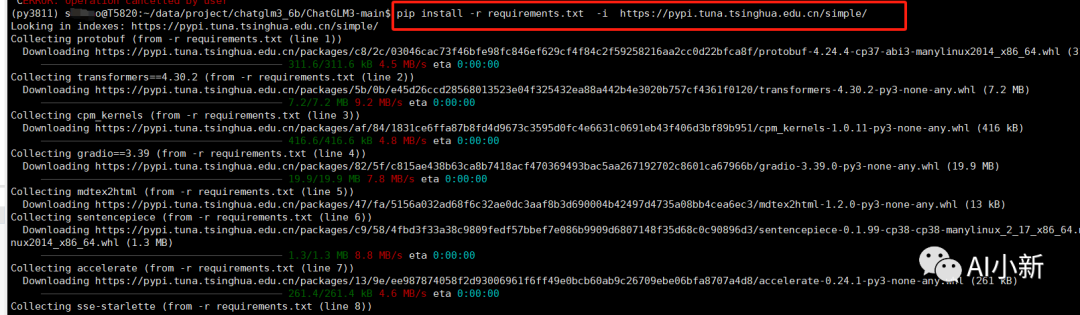
4.6 执行如下命令,批量安装依赖包
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
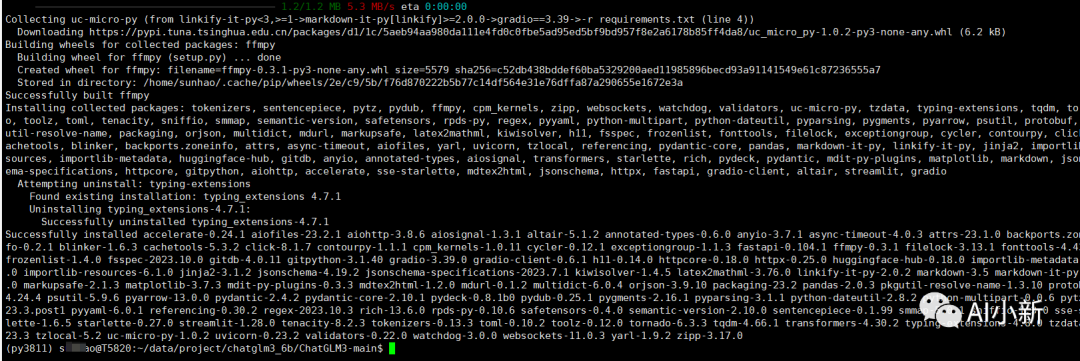
安装完成!
五、运行chatglm相关的服务
5.1、交互式对话程序:cli_demo.py
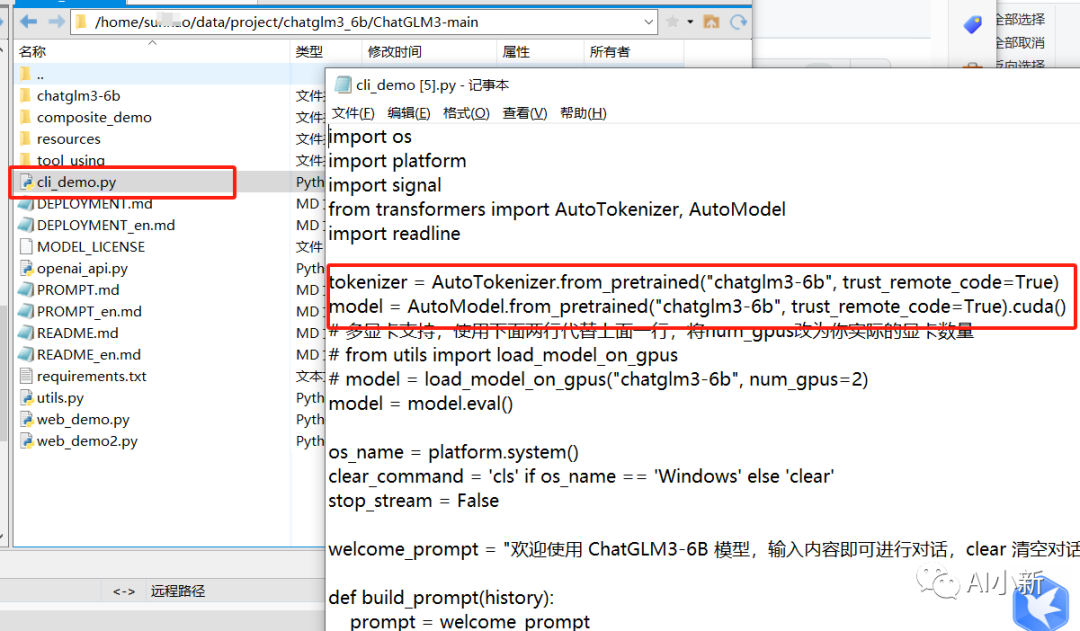
(1)修改模型文件加载的路径
模型文件放在代码的根目录。
本文将模型文件放在代码的同级目录,所以修改下cli_demo.py 中 模型文件存放的位置,填入 模型文件所在的 相对路径或者绝对路径。
#原始路径``tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)``model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).cuda()``#改为下面的路径``tokenizer = AutoTokenizer.from_pretrained("chatglm3-6b", trust_remote_code=True)``model = AutoModel.from_pretrained("chatglm3-6b", trust_remote_code=True).cuda()
(2)运行 简单交互对话的程序:
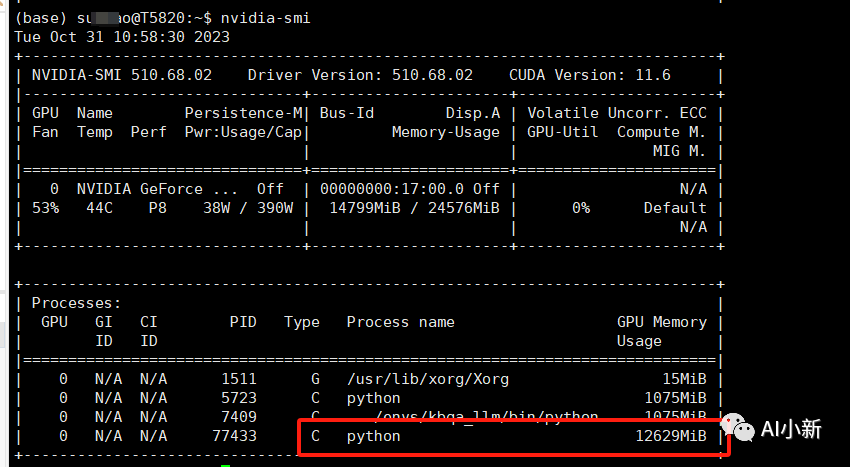
python cli_demo.py

启动服务后, 显存 大概占用了 12G左右。
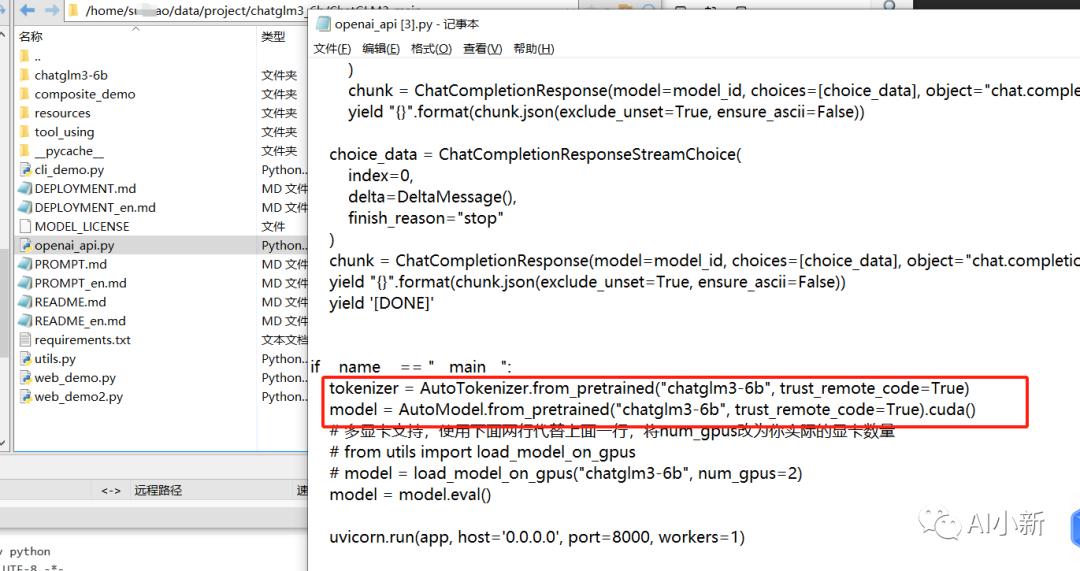
5.1、启动openai的接口服务:openai_api.py
(1)同样需要 修改模型路径
(2)修改代码
将openai_api.py文件中3处
chunk.json(exclude_unset=True, ensure_ascii=False)
替换为
chunk.model_dump_json(exclude_unset=True,exclude_none=True)
改为 如下图红框位置 所示:

(3)启动服务
python openai_api.py
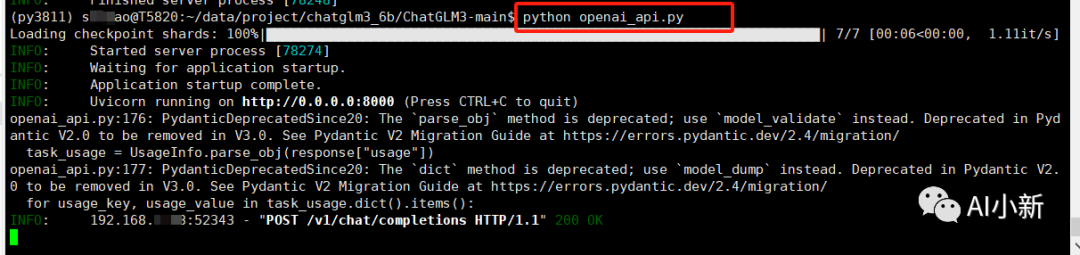
(4) 利用requests请求调用chatglm的接口服务:
openai_url=“http://ip:8000/v1/chat/completions”
ip:chatglm部署的ip
完整代码如下:
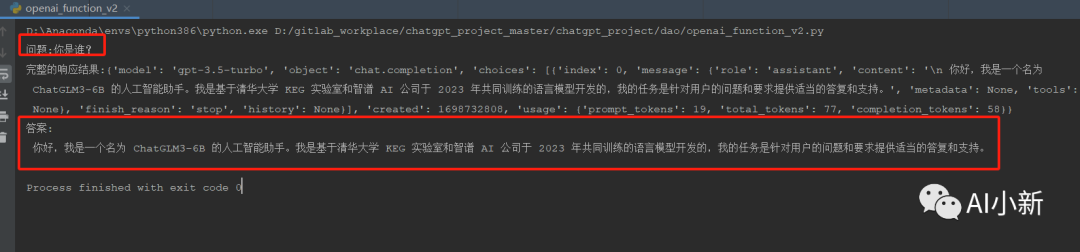
#!/usr/bin/env python``# -*- coding: UTF-8 -*-``"""``@Project :chatgpt``@File :openai_function.py``@Author :aixiaoxin``@Date :2023/10/27 17:28``"""``import requests`` ``def request_chatgpt_function():` `# 通用方法:利用requests 请求调用` `question = "你是谁?"` `openai_url="http://ip:8000/v1/chat/completions" # 可以替换为任何代理的接口,官网地址 https://api.openai.com/v1/chat/completions` `OPENAI_API_KEY="sk-amd6pTaiXrJ6U8VjFb7dB439A97542D5A2E4Ed38C1BaC9D2" # openai的key,此处不需要填写` `header={"Content-Type": "application/json","Authorization": "Bearer " +OPENAI_API_KEY}` `data={` `"model": "gpt-3.5-turbo",` `"messages": [` `{` `"role": "system",` `"content": "You are a helpful assistant."` `},` `{` `"role": "user",` `"content": question` `}` `],` `"stream":False` `}` `print("问题:{}".format(question))` `response=requests.post(url=openai_url,headers=header,json=data).json()` `print("完整的响应结果:{}".format(response))` `answer = response["choices"][0]["message"]["content"]` `print("答案:{}".format(answer))`` `` `` ``if __name__ == "__main__":` `request_chatgpt_function() # 通用方法:利用requests 请求调用
运行结果:
(5)利用openai接口流式调用chatglm的服务:
openai.api_base = “http://ip:8000/v1”
ip:填入chatglm部署的服务器的ip
完整代码如下:
#!/usr/bin/env python``# -*- coding: UTF-8 -*-``"""``@Project :chatgpt_project``@File :chatglm_request.py``@Author :aixiaoxin``@Date :2023/10/29 14:32``"""``import openai``if __name__ == "__main__":` `openai.api_base = "http://ip:8000/v1"` `openai.api_key = "none"` `for chunk in openai.ChatCompletion.create(` `model="chatglm3-6b",` `messages=[` `{"role": "user", "content": "你好"}` `],` `stream=True` `):` `if hasattr(chunk.choices[0].delta, "content"):` `print(chunk.choices[0].delta.content, end="", flush=True)
运行截图:

六、FastGPT知识库问答使用 本地 chatglm服务
先运行上一节中的接口服务:python openai_api.py
找到fastgpt项目中的
files\deploy\fastgpt\docker-compose.yml 文件
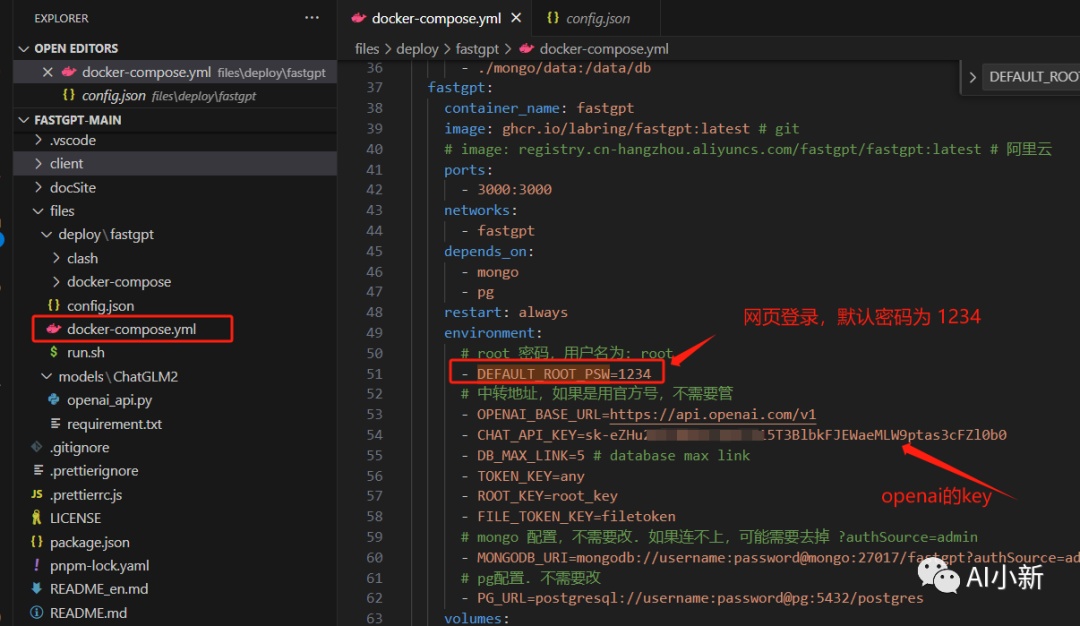
将OPEN_BASE_URL 改为如下地址:
http://ip:8000/v1
ip:表示大模型部署服务器的ip
完整的 fastgpt的详细部署教程可以参考下面文档:
利用Docker Compose快速部署FastGPT知识库问答
以上就是今天的所有内容了!
参考文献:
https://github.com/THUDM/ChatGLM3
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









