







大模型是当代的智力引擎,带来10X Better的解决方案
22年底我第一次接触了ChatGPT被深深震撼之后,意识到新的范式正在到来。经过过去几个月的学习与实践,逐渐度过了不知所措的阶段,开始对以ChatGPT为代表的LLM(Large Language Model 大语言模型)有了一些感觉,这篇文章就把过去这段时间的学习整理成一个学习路线图,希望对有志于入门AI,成为AI-native Builder的同学有帮助。
先说一下对大模型的几个核心判断:
-
大模型是信息时代的智力引擎:学会利用大模型高质量,低成本,全天候在线的智力(语义理解和逻辑推理能力)快速实现对业务的赋能。智力成本的急速降低会改变很多商业模式的成本结构,创造大量新机会。
-
先实践就能带来先发优势。LLM本质是实践科学,ChatGPT的成功是工程实践的突破,和斯坦佛CS的人交流知道好几年前已有课程教授GPT原理,但是真正落地做出效果好的大模型不容易。Pre-training和Finetuning阶段数据集的搭建,RLHF,Prompt Engineering等都需大量工程探索,先发者可以形成数据飞轮,和后发者迅速拉开差距。
-
给一些行业提供10X Better的解决方案,甚至创造一些新的行业:我在湾区Huggingface AI meetup中问了吴恩达有没有生成式AI在视频领域比较好的应用,吴恩达举了一个例子:影视创作AI公司Runway,主要方向做视频特效的生成,也负责《瞬息全宇宙》的特效,把常规的40~人的特效团队做到了 5个人+Runway,效果还比之前好,这种10X Better的新技术着实令人激动。



在湾区参加__Huggingface AI meetup_,看到了吴恩达,以及__Stanford Alpaca__的一作_
多体验产品,了解Use case和能力边界
积极体验大模型产品,一方面可以给自己的工作流提效,另一方面也能深入了解GPT的各种使用场景,以及大模型能力边界,尤其注意观察使用中的痛点和局限性(如Token上限,幻觉Hullucination等)。
推荐体验的一些产品:
-
体验大模型:ChatGPT, Claude, Poe(poe.com)等,搭配Plugin插件体验更佳。
-
体验大模型的应用:New Bing, Github Copilot, Character.ai, Replica, Chirper AI (AI机器人交流的Twitter),ChatPDF,Jasper AI, notion ai
-
积极尝试在自己的工作流中嵌入ChatGPT/MidJourney等产品,写代码,写周报,脑暴想法,总结文档,翻译等。生活中的问题也可以积极问。
-
注册一个ChatGPT账号,并获得OpenAI的API Key;踏上GPT产品开发之旅的第一步,也是通往无限可能的起点。
-
注册Google Colab(不用下载or配置本地环境即可线上实现很多大模型的框架,还有一定的免费GPT), 多去Hugging Face(有大量开源模型,数据集,以及模型的线上体验)
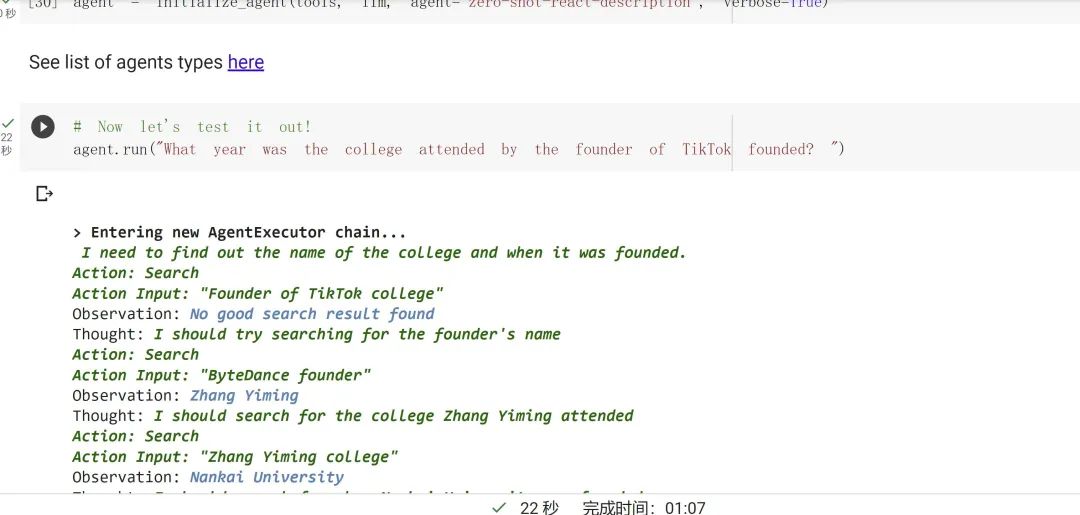

AI Agent__调用搜索等工具来回答我的问题_“TikTok__创始人的毕业学校创立于哪一年?__”_
进阶之路 Prompt Engineering
-
一旦开始深度使用ChatGPT类似产品,会发现大概率一开始ChatGPT的产出质量不能满足你的预期,就需要通过调整Prompt来逐渐提升回复的质量。可以在Poe,或者在Colab中实操各种prompt Engineering。关注和学习高阶技巧,真正希望大模型集成到核心业务中创造价值,对Prompt要求更加专业
-
Prompt是科学也是艺术。科学性体现在Prompt的效果很多时候是稳定可复现的(大量的Paper都在研究如何通过Prompt比较solid的提升模型的推理能力)。好的Prompt能够让GPT学会调用工具和API(HuggingGPT),学会操控机器人(Google SayCan),学会和其他AI Agent协同(CAMEL)。
-
掌握Prompt Engineering通用原则:Few-shot prompting, Chain of Thoughts, Self-Ask等等, 微软官方出的Prompt engineering techniques,OpenAI Cookbook ,吴恩达Prompt Engineering For Developers
-
Prompt Enginnering进阶技巧: ToT, Automatic Prompt Engineer (APE), APE ,Prefix-Tuning, P-Tuning, Prompt Tuning。 例如APE通过程序化调试Prompt的方式发现了比人工试出来的“Let’s think step by step”更好的零样本 CoT Prompt.多学多练很快就可以成为Prompt高手
Build with LLM 建造自己的AI助手
实践开干,LLM应用层程序开发:掌握开发框架可以极大的提升实践效率,同时Github上有大量GPT开源项目可以参考实践。动手实践干中学。
-
学习Langchain框架,LangChain是目前LLM应用搭建最主流的框架,能给LLM这个“大脑”组装上“手”和“腿”,一定要了解Agent,Memory,Chain等核心概念
-
OpenAI CookBook:对于开发人员来说,这是使用Open AI的指南和代码示例的权威集合
-
Open AI Techniques to Improve LLM Reliability
-
LLM Bootcamp:构建基于LLM的应用程序的实用课程
-
微软的Prompt模板:https://github.com/microsoft/guidance/blob/main/notebooks/chat.ipynb
-
实现类似于ChatPDF这样的简单应用,学会如何给ChatGPT灌输外部知识
-
DataWhale ChatGPT开发应用指南: https://github.com/datawhalechina/hugging-llm/tree/main/content
-
试着复现一下AutoGPT (Github repo)
-
结合业务,想一想大模型有什么业务落地点,通过大模型快速测试下
-
随着实践的不断增加,会发现有一些情况无论怎么调整Prompt,模型都不能按期望工作,此时就要考虑对模型进行训练了,训练的方式一种是较低成本的模型精调,例如LoRA等微调方法来进行Fine tune,如果微调还不够,则可以更进一步,进行Pre-training。
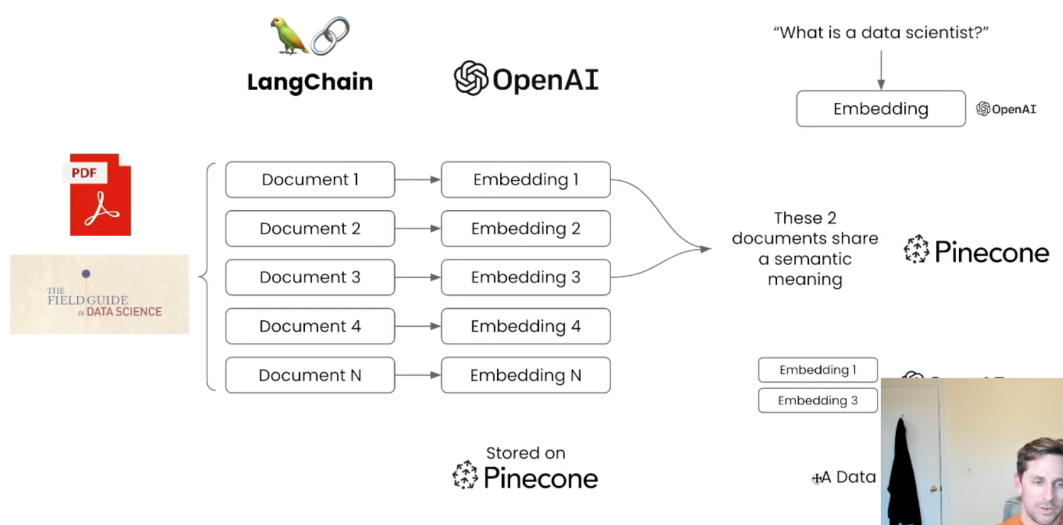
学习GPT理论和前沿
-
State of GPT: 主讲人Andrej Karpathy是Open AI最早几个研究员,后续担任Tesla AI Director,一手主导Tesla Autocopilot自动驾驶系统的研发。视频中Andrej讲解了ChatGPT的原理和训练过程,以及给实践者的建议 视频,文字稿


-
从0到1构建****GPT:Andrej的另一个视频,手把手教你写代码从0到1构建GPT
-
RLHF**:来自人类反馈的强化学习**:RLHF原理解释,使LLM和人类的意图更加对齐,这是ChatGPT成功最重要的方面。
-
A16Z整理的AI学习资料,里面有大量原理和实践A16Z整理的AI典藏
-
了解Transformer架构,了解它和之前的RNN,CNN的区别和联系 MIT Introduction to Deep Learning: Transfomers , 反向传播, Embedding等
同时推荐一些值得重点关注的前沿方向:
-
多模态大模型,尤其是视觉方面的大模型
-
降低模型训练&推理成本方面的进展,实现私有化部署,甚至是边缘计算
-
提升推理能力的技巧,防止幻觉,增加Memory
-
GPT调用工具的能力
-
AI可解释性与AI和人类意图的对齐
商业模式与思考:大模型的增量价值到底在哪?
新的技术变革发生的时候,大家都在思考未来10年最大的机会在哪?我也在思考这个问题,目前我的判断是对大多数公司和个人的最好的机会是在大模型的应用。现在的行业肯定有泡沫存在,但是最后存活下来的是那些从痛点出发,真正能解决问题的公司。
有一些人觉得大部分AI公司都是套壳GPT没有什么价值。我觉得关注点搞错了,核心不是是否套壳,而是能不能用大模型解决实际的业务痛点。纵观科技史,有很多先例说明底层技术的革新不会是先发者一家独大。
内燃机只能提供动力,但是靠着内燃机组装起来的汽车,则是解决了用户的痛点_——出行。你可以说早期的汽车行业也是基于内燃机的“套壳”,可是并不影响万亿汽车产业的到来。套壳没问题,能解决巨大的痛点是关键,一旦痛点被解决且能规模化,就会拥有对上游更强的议价权,你可以选择在不同的大模型间切换,也可以选择自建。福特早期组装汽车取得初步市场成功后开始自研内燃机,苹果组装出__iPhone__手机占领市场后也从前几代的三星芯片切换成自研的__A__系列芯片。_

最近的一张流行梗图,讽刺大量AI创业公司是基于GPT模型的“套壳”

早期汽车也可以看做内燃机的“套壳”,基于内燃机的应用层产品
落到机会点上:
- 成熟企业的机会:成熟企业因为已经有足够的数据积累和流量入口,在业务场景中整合大模型会吃到相当大的红利。可以看到办公系统的微软(Office Copilot),搜索领域的谷歌(Bard),内容行业的Notion AI,代码生成的Github(Github Copilot),创意领域的Adobe(推出Adobe Firefly)。其他互联网的主流领域,例如电商、娱乐资讯、以及SaaS(CRM)等的现有玩家,估计也有类似的大模型动作。比的是应用大模型到业务场景中的理解和速度。只要速度不要太慢,不太会被创业公司颠覆。

- 初创企业机会:
○AI native的赛道:例如AI陪伴,个人助手,企业场景下的数字员工等全新的应用场景。很期待若干年后,每个人都有好几个自己的AI朋友,他们实时在线且懂你,随时交流,也可以代替你去进行部分的社交和工作。职场中,你的10个同事中可能有8个都是AI,你和他们讨论、开会,协作落地项目。
○垂直行业的机会,尤其是缺乏数字化基因的垂直行业:例如和巨头联合共建法律,医疗,房地产的大模型,Harvey AI, Hippocratic AI就是这样的例子。律所/医院不太可能自己招人来研发大模型产品,所以更倾向于和Start up合作一起吃下红利。
大模型应用层公司的壁垒在哪?这里可以参考一下数据/AI类公司的壁垒:
-
理解业务Context,更贴近使用场景:例如Github Copilot在生产代码时context不仅包含当前文件,也包含最近打开过的20个相同编程语言的代码文件,同时在现有开发的IDE中可以直接使用。Jasper.ai提供各种场景下开箱即用的文案模板,Hippocratic AI在医学考试和“患者同情度”上表现均好于GPT-4,在医疗咨询场景下更具有落地性。
-
独特数据集&构建反馈闭环: 能引入行业专家做RLHF,或者能巧妙吸引大量用户使用收集反馈。越多的用户和客户来用产品,就会产生越多的专有数据,从而使产品得到改进,进而吸引更多客户。Github Copilot不仅基于Github仓库内的代码进行训练,同时也建立了高效的用户反馈闭环,通过检查生成的代码一段时间后是否还存在于编码文件中作为反馈来迭代模型。
为了帮助大家更好的学习网络安全,我给大家准备了一份网络安全入门/进阶学习资料,里面的内容都是适合零基础小白的笔记和资料,不懂编程也能听懂、看懂这些资料!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
[2024最新优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享]

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
[2024最新优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享]


因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









