







本章节精心构构造SQL语法学习之旅的基石,旨在从基础出发,逐步深入,全面解析SQL语法规则并辅以丰富实例。通过这一篇章,您将循序渐进地掌握MySQL的核心语法,开启数据库操作的新境界。
1:SQL 语言概述
SQL(Structured Query Language),简称 SQL。结构化查询语言包含 6 个部分:
| 类型 | 释义 | 范例 |
|---|---|---|
| 数据查询语言 | DQL:Data Query Language | 如 SELECT |
| 数据操作语言 | DML:Data Manipulation Language | INSERT,DELETE,UPDATE |
| 事务控制语言 | TCP:Transaction Control Language | COMMIT(提交)命令,SAVEPOINT(保存点)命令,ROLLBACK(回滚)命令) |
| 数据控制语言 | DCL:Data Control Language | GRANT,REVOKE |
| 数据定义语言 | DDL:Data Definition Language | CREATE,ALTER,DROP |
| 指针控制语言 | CCL:Pointer Control Language | DECLARE CURSOR,FETCH INTO,UPDATE CURRENT |
2:数据库,表,列和行的概念
MySQL 中是 database(schema),table,column # 那么我们如何连接 MySQL? root@ubuntu:~# mysql -uxxxx -p -h xxx Enter password: # 这里输入密码 # 连接工具就非常的多了,比如 Navicate,workbeach 等等等等,其次我们要知道,MySQL 除了账号密码,还可以 socket 连接操作,这个在 my.cnf 配置的时候我们有配置过 # 查看数据库 mysql> show databases; # 查看当前库 mysql> select database(); # 进入/连接到数据库 mysql> use mysql; # 查看表 mysql> show tables; # 查询账户 mysql> select user,host from mysql.user; # 创建用户 mysql> create user 'g8s_manager'@'%' identified by 'MTIzNDU2Cg=='; # 为用户授权某数据库的权限,这里选择的是 g8s_manager 数据库下s的所有表的所有权限授权给 'g8s_manager'@'%' mysql> grant all on g8s_manager.* to 'g8s_manager'@'%'; 1:grant:用于授予权限 2:all:授予所有权限 2.1:SELECT:允许查询表 2.2:INSERT:允许插入新数据到表 2.3:UPDATE:允许更新表中的数据 2.4:DELETE:允许删除表中的数据 2.5:CREATE:允许创建表 2.6:ALTER:允许修改表 2.7:DROP:允许删除表 3:on:指定数据库和表 4:g8s_manager:指定数据库名称 5:.*:指定所有表 6:to:指定用户 7:'g8s_manager'@'%':指定用户名称和主机名,这里的主机名为 %,表示允许所有主机上的用户 g8s_manager 访问。 # 刷新权限 mysql> flush privileges; # 测试用户登录数据库 root@ubuntu:~# mysql -ug8s_manager -p$password ...... mysql> show databases; +--------------------+ | Database | +--------------------+ | g8s_manager | | information_schema | | performance_schema | +--------------------+ 3 rows in set (0.00 sec) # 可以看到,权限仅限于查看系统自带的一些库和自己有权限的库,甚至查看表也一样 mysql> show tables from g8s_manager; +-----------------------+ | Tables_in_g8s_manager | +-----------------------+ | clusters | +-----------------------+ 1 row in set (0.00 sec) # 当然我们可以授权就可以撤销授权,我们可以使用 DCL(数据库控制)来撤销我们的授权 mysql> revoke all on g8s_manager.* from 'g8s_manager'@'%'; 1:revoke:用于撤销权限 2:all:撤销所有权限 3:on:指定数据库和表 4:g8s_manager:指定数据库名称 5:.*:指定所有表 6:from:指定用户 7:'g8s_manager'@'%':指定用户名称和主机名,这里的主机名为 %,表示允许所有主机上的用户 g8s_manager 访问。 # 再次登录数据库查看 root@ubuntu:~# mysql -ug8s_manager -p$password ...... mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | performance_schema | +--------------------+ 2 rows in set (0.00 sec) # 可以看到权限没了 # 退出数据库 mysql> QUIT Bye 或者 mysql> EXIT Bye 或者 mysql> \q Bye # 下面我们将开始学习 6 个部分
3:DDL(数据库定义语言)
`# 创建库(还可以有很多的附加操作,比如判断这个数据库是否存在等) mysql> create database g8s_manager; Query OK, 1 row affected (0.01 sec) # 创建表 mysql> CREATE TABLE clusters ( id INT AUTO_INCREMENT NOT NULL, name VARCHAR(20) NOT NULL, version int NOT NULL, created_at DATETIME NOT NULL, updated_at DATETIME NOT NULL, kubeconfig JSON NOT NULL, PRIMARY KEY (id) ) ENGINE = InnoDB; Query OK, 0 rows affected (0.01 sec) # 基于上面的表我们来写入一个模拟数据 mysql> insert into clusters (name, version, created_at, updated_at, kubeconfig) values ('cluster-1', 1, NOW(), NOW(), '{"name": "cluster1"}'); Query OK, 1 row affected (0.00 sec) mysql> insert into clusters (name, version, created_at, updated_at, kubeconfig) values ('cluster-2', 1, NOW(), NOW(), '{"name": "cluster2"}'); Query OK, 1 row affected (0.00 sec) mysql> insert into clusters (name, version, created_at, updated_at, kubeconfig) values ('cluster-3', 1, NOW(), NOW(), '{"name": "cluster3"}'); Query OK, 1 row affected (0.00 sec) mysql> insert into clusters (name, version, created_at, updated_at, kubeconfig) values ('cluster-4', 1, NOW(), NOW(), '{"name": "cluster4"}'); Query OK, 1 row affected (0.00 sec) mysql> insert into clusters (name, version, created_at, updated_at, kubeconfig) values ('cluster-5', 1, NOW(), NOW(), '{"name": "cluster5"}'); Query OK, 1 row affected (0.01 sec) # 查询数据 mysql> select * from clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 1 | cluster-1 | 1 | 2024-01-20 22:04:39 | 2024-01-20 22:04:39 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | 2024-01-20 22:04:59 | 2024-01-20 22:04:59 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | 2024-01-20 22:05:05 | 2024-01-20 22:05:05 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | 2024-01-20 22:05:11 | 2024-01-20 22:05:11 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | 2024-01-20 22:05:16 | 2024-01-20 22:05:16 | {"name": "cluster5"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 5 rows in set (0.00 sec) # 创建同结构的表(只是表结构相同,不涉及数据) mysql> create table new_clusters like clusters; Query OK, 0 rows affected (0.02 sec) # 查看表结构 mysql> desc clusters; +------------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | version | int | NO | | NULL | | | created_at | datetime | NO | | NULL | | | updated_at | datetime | NO | | NULL | | | kubeconfig | json | NO | | NULL | | +------------+-------------+------+-----+---------+----------------+ 6 rows in set (0.01 sec) mysql> desc new_clusters; +------------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | version | int | NO | | NULL | | | created_at | datetime | NO | | NULL | | | updated_at | datetime | NO | | NULL | | | kubeconfig | json | NO | | NULL | | +------------+-------------+------+-----+---------+----------------+ 6 rows in set (0.00 sec) # 获取创建表的 SQL 语句 mysql> show create table clusters\G; *************************** 1. row *************************** Table: clusters Create Table: CREATE TABLE `clusters` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL, `version` int NOT NULL, `created_at` datetime NOT NULL, `updated_at` datetime NOT NULL, `kubeconfig` json NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci 1 row in set (0.00 sec) # 创建索引 mysql> create index i_name on clusters (name); Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0 # 查询索引 mysql> show index from clusters\G; *************************** 1. row *************************** Table: clusters Non_unique: 0 Key_name: PRIMARY Seq_in_index: 1 Column_name: id Collation: A Cardinality: 4 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: Visible: YES Expression: NULL *************************** 2. row *************************** Table: clusters Non_unique: 1 Key_name: i_name Seq_in_index: 1 Column_name: name Collation: A Cardinality: 5 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: Visible: YES Expression: NULL 2 rows in set (0.00 sec) #所以在这儿我们看到了两个索引,当然,还可以在建表的时候加上 key index_name (column_name),可以创建索引,这里的 id 是因为它是主键,主键必须有索引,所以才会看到 id 这个索引,我们可以自己加其他值得索引,或者我们像上面一样直接 create 创建索引也可以 # SQL 验证工具:https://tool.lu/sql/ # 不过总而言之,我们创建索引是使用 create,但是,在 8.0.13 之后的写法,推荐使用 alter 来操作 mysql> alter table clusters add index i_name(name); Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show index from clusters\G; *************************** 1. row *************************** Table: clusters Non_unique: 0 Key_name: PRIMARY Seq_in_index: 1 Column_name: id Collation: A Cardinality: 4 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: Visible: YES Expression: NULL *************************** 2. row *************************** Table: clusters Non_unique: 1 Key_name: i_name Seq_in_index: 1 Column_name: name Collation: A Cardinality: 5 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: Visible: YES Expression: NULL 2 rows in set (0.01 sec) # 写法与 create 不同,但是实现的效果却相同,我们从创建好索引之后去查看创建表的 SQL,也可以看到,它给我们增加了 key 创建索引的语句 mysql> show create table clusters\G; *************************** 1. row *************************** Table: clusters Create Table: CREATE TABLE `clusters` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL, `version` int NOT NULL, `created_at` datetime NOT NULL, `updated_at` datetime NOT NULL, `kubeconfig` json NOT NULL, PRIMARY KEY (`id`), KEY `i_name` (`name`) ) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci 1 row in set (0.00 sec) # 删除索引的方法 mysql> drop index i_name on clusters; mysql> show index from clusters\G; *************************** 1. row *************************** Table: clusters Non_unique: 0 Key_name: PRIMARY Seq_in_index: 1 Column_name: id Collation: A Cardinality: 4 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: Visible: YES Expression: NULL 1 row in set (0.00 sec) # 然后我们来讲讲 alter 语句,我们可以修改表名 mysql> create table usar (name INTEGER, role CHAR(10)); Query OK, 0 rows affected (0.01 sec) # 我们发现,貌似表名字写错了,那么我们将更新这个表名 mysql> alter table usar rename user; Query OK, 0 rows affected (0.01 sec) mysql> show tables; +-----------------------+ | Tables_in_g8s_manager | +-----------------------+ | clusters | | user | +-----------------------+ 2 rows in set (0.00 sec) # 其次是我们可以修改表字段的属性 mysql> create table user (a INTEGER, b CHAR(10)); Query OK, 0 rows affected (0.01 sec) mysql> desc user; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | a | int | YES | | NULL | | | b | char(10) | YES | | NULL | | +-------+----------+------+-----+---------+-------+ 2 rows in set (0.00 sec) # 修改属性 mysql> alter table user modify a tinyint not null, change b c char(20); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc user; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | a | tinyint | NO | | NULL | | | c | char(20) | YES | | NULL | | +-------+----------+------+-----+---------+-------+ 2 rows in set (0.00 sec) # 可以看出,原来 a 的类型为 int,且可以为空,现在类型被改变了,且不能为,其次就是 b 的名字改成了 c,然后 char 的数量从 10 改为了 20 # 其次我们还可以加列,基于这个表再加一个列,列名为 b mysql> desc user; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | a | tinyint | NO | | NULL | | | c | char(20) | YES | | NULL | | | b | datetime | YES | | NULL | | +-------+----------+------+-----+---------+-------+ 3 rows in set (0.00 sec) # 然后我们还能加索引和主键 mysql> alter table user add index (b), add unique (a); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc user; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | a | tinyint | NO | PRI | NULL | | | c | char(20) | YES | | NULL | | | b | datetime | YES | MUL | NULL | | +-------+----------+------+-----+---------+-------+ 3 rows in set (0.00 sec) mysql> show index from user\G; *************************** 1. row *************************** Table: user Non_unique: 0 Key_name: a Seq_in_index: 1 Column_name: a Collation: A Cardinality: 0 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: Visible: YES Expression: NULL *************************** 2. row *************************** Table: user Non_unique: 1 Key_name: b Seq_in_index: 1 Column_name: b Collation: A Cardinality: 0 Sub_part: NULL Packed: NULL Null: YES Index_type: BTREE Comment: Index_comment: Visible: YES Expression: NULL 2 rows in set (0.00 sec) # 然后我们还可以删除列 mysql> alter table user drop column b; Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc user; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | a | tinyint | NO | PRI | NULL | | | c | char(20) | YES | | NULL | | +-------+----------+------+-----+---------+-------+ 2 rows in set (0.00 sec) # 然后我们还能加列加主键 mysql> alter table user add d int unsigned not null auto_increment, add primary key (d); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc user; +-------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+--------------+------+-----+---------+----------------+ | a | tinyint | NO | UNI | NULL | | | c | char(20) | YES | | NULL | | | d | int unsigned | NO | PRI | NULL | auto_increment | +-------+--------------+------+-----+---------+----------------+ 3 rows in set (0.00 sec) # 但是这里我们有一个问题:如何修改主键?由一个列换成另一个列,我们要知道,一个表只能有一个主键,那么意思就是我们能否将一个列的主键切换为另一个列呢? mysql> desc user; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | uid | int | NO | | NULL | | | name | varchar(20) | NO | | NULL | | +-------+-------------+------+-----+---------+----------------+ # 去除自增属性 ALTER TABLE user MODIFY id INT; mysql> desc user; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | int | NO | PRI | NULL | | | uid | int | NO | | NULL | | | name | varchar(20) | NO | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.00 sec) # 删除主键然后替换新的主键上去 mysql> ALTER TABLE user DROP PRIMARY KEY, ADD PRIMARY KEY (uid); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc user; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | int | NO | | NULL | | | uid | int | NO | PRI | NULL | | | name | varchar(20) | NO | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.00 sec) # 我们可以通过 ? alter 来查看 alter 都有哪儿些操作 mysql> ? alter Many help items for your request exist. To make a more specific request, please type 'help <item>', where <item> is one of the following topics: ALTER DATABASE ALTER EVENT ALTER FUNCTION ALTER INSTANCE ALTER LOGFILE GROUP ALTER PROCEDURE ALTER RESOURCE GROUP ALTER SCHEMA ALTER SERVER ALTER TABLE ALTER TABLESPACE ALTER USER ALTER VIEW GRANT SPATIAL INDEXES # 其次下面就是 DROP 语句,它主要用于删除 mysql> ? drop Many help items for your request exist. To make a more specific request, please type 'help <item>', where <item> is one of the following topics: ALTER TABLE ALTER TABLESPACE ALTER USER DEALLOCATE PREPARE DROP DATABASE DROP EVENT DROP FUNCTION DROP FUNCTION LOADABLE FUNCTION DROP INDEX DROP PREPARE DROP PROCEDURE DROP RESOURCE GROUP DROP ROLE DROP SCHEMA DROP SERVER DROP SPATIAL REFERENCE SYSTEM DROP TABLE DROP TABLESPACE DROP TRIGGER DROP USER DROP VIEW # 我们无非也是 drop 用户,表,索引等操作,但是我们要记住,删除用户尽量用 drop 而不要用 dedlete(此操作非常之危险,请务必减少此操作) # 详解为什么删除用户推荐使用 drop 而不推荐使用 delete 1:因为 drop 可以删除用户和关联权限表中关于此用户的数据 2:以为 delete 仅仅只是删除了 mysql.user 的数据,而并不删除关联权限的表,需要 flush privileges 刷新权限,才会将权限关联表删除已经删除用户的权限关联信息 mysql> drop table user; Query OK, 0 rows affected (0.00 sec) mysql> show tables; +-----------------------+ | Tables_in_g8s_manager | +-----------------------+ | clusters | +-----------------------+ 1 row in set (0.01 sec) # 然后删除数据库(此操作同上风险) mysql> create database old_g8s; Query OK, 1 row affected (0.00 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | g8s_manager | | information_schema | | mysql | | old_g8s | | performance_schema | | sys | +--------------------+ 6 rows in set (0.01 sec) mysql> drop database old_g8s; Query OK, 0 rows affected (0.02 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | g8s_manager | | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.00 sec) `
4:DML(数据库操作语言)
1:select 语句 # 基本的 select 语句 mysql> select id, name, version, kubeconfig from g8s_manager.clusters; +----+-----------+---------+----------------------+ | id | name | version | kubeconfig | +----+-----------+---------+----------------------+ | 1 | cluster-1 | 1 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | {"name": "cluster5"} | +----+-----------+---------+----------------------+ 5 rows in set (0.00 sec) # 格式化 mysql> select id, name, version, kubeconfig from g8s_manager.clusters\G; *************************** 1. row *************************** id: 1 name: cluster-1 version: 1 kubeconfig: {"name": "cluster1"} *************************** 2. row *************************** id: 2 name: cluster-2 version: 1 kubeconfig: {"name": "cluster2"} *************************** 3. row *************************** id: 3 name: cluster-3 version: 1 kubeconfig: {"name": "cluster3"} *************************** 4. row *************************** id: 4 name: cluster-4 version: 1 kubeconfig: {"name": "cluster4"} *************************** row *************************** id: 5 name: cluster-5 version: 1 kubeconfig: {"name": "cluster5"} 5 rows in set (0.00 sec) # 这里的 id, name, version, kubeconfig 都是表中已经存在的列,然后查询出来之后会以我们查询的列来展示数据 # 使用 where 来过滤数据 mysql> select id, name, version, kubeconfig from g8s_manager.clusters where id = 1; +----+-----------+---------+----------------------+ | id | name | version | kubeconfig | +----+-----------+---------+----------------------+ | 1 | cluster-1 | 1 | {"name": "cluster1"} | +----+-----------+---------+----------------------+ 1 row in set (0.01 sec mysql> select id, name, version, kubeconfig from g8s_manager.clusters where id in(1); +----+-----------+---------+----------------------+ | id | name | version | kubeconfig | +----+-----------+---------+----------------------+ | 1 | cluster-1 | 1 | {"name": "cluster1"} | +----+-----------+---------+----------------------+ 1 row in set (0.00 sec) mysql> select id, name, version, kubeconfig from g8s_manager.clusters where id not in(1); +----+-----------+---------+----------------------+ | id | name | version | kubeconfig | +----+-----------+---------+----------------------+ | 2 | cluster-2 | 1 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | {"name": "cluster5"} | +----+-----------+---------+----------------------+ 4 rows in set (0.00 sec) mysql> select id, name, version, kubeconfig from g8s_manager.clusters where name = 'cluster-1'; +----+-----------+---------+----------------------+ | id | name | version | kubeconfig | +----+-----------+---------+----------------------+ | 1 | cluster-1 | 1 | {"name": "cluster1"} | +----+-----------+---------+----------------------+ 1 row in set (0.00 sec) # 然后我们还可以使用 order by 对结果进行排序 # 正序排序 mysql> select id, name, version, kubeconfig from g8s_manager.clusters order by name asc; +----+-----------+---------+----------------------+ | id | name | version | kubeconfig | +----+-----------+---------+----------------------+ | 1 | cluster-1 | 1 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | {"name": "cluster5"} | +----+-----------+---------+----------------------+ 5 rows in set (0.00 sec) # 倒序排序 mysql> select id, name, version, kubeconfig from g8s_manager.clusters order by name DESC; +----+-----------+---------+----------------------+ | id | name | version | kubeconfig | +----+-----------+---------+----------------------+ | 5 | cluster-5 | 1 | {"name": "cluster5"} | | 4 | cluster-4 | 1 | {"name": "cluster4"} | | 3 | cluster-3 | 1 | {"name": "cluster3"} | | 2 | cluster-2 | 1 | {"name": "cluster2"} | | 1 | cluster-1 | 1 | {"name": "cluster1"} | +----+-----------+---------+----------------------+ 5 rows in set (0.00 sec) # 我们还可以限制每行的回显数量 mysql> select id, name, version, kubeconfig from g8s_manager.clusters limit 2; +----+-----------+---------+----------------------+ | id | name | version | kubeconfig | +----+-----------+---------+----------------------+ | 1 | cluster-1 | 1 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | {"name": "cluster2"} | +----+-----------+---------+----------------------+ 2 rows in set (0.00 sec) # 然后我们可以将查询连接到其他表内 mysql> SELECT * FROM clusters INNER JOIN new_clusters ON clusters.id = new_clusters.id\G; *************************** 1. row *************************** id: 1 name: cluster-1 version: 1 created_at: 2024-01-20 22:04:39 updated_at: 2024-01-20 22:04:39 kubeconfig: {"name": "cluster1"} id: 1 name: cluster-6 version: 1 created_at: 2024-01-22 16:15:36 updated_at: 2024-01-22 16:15:36 kubeconfig: {"name": "cluster6"} *************************** 2. row *************************** id: 2 name: cluster-2 version: 1 created_at: 2024-01-20 22:04:59 updated_at: 2024-01-20 22:04:59 kubeconfig: {"name": "cluster2"} id: 2 name: cluster-7 version: 1 created_at: 2024-01-22 16:15:43 updated_at: 2024-01-22 16:15:43 kubeconfig: {"name": "cluster7"} *************************** 3. row *************************** id: 3 name: cluster-3 version: 1 created_at: 2024-01-20 22:05:05 updated_at: 2024-01-20 22:05:05 kubeconfig: {"name": "cluster3"} id: 3 name: cluster-8 version: 1 created_at: 2024-01-22 16:15:50 updated_at: 2024-01-22 16:15:50 kubeconfig: {"name": "cluster8"} *************************** 4. row *************************** id: 4 name: cluster-4 version: 1 created_at: 2024-01-20 22:05:11 updated_at: 2024-01-20 22:05:11 kubeconfig: {"name": "cluster4"} id: 4 name: cluster-9 version: 1 created_at: 2024-01-22 16:15:56 updated_at: 2024-01-22 16:15:56 kubeconfig: {"name": "cluster9"} *************************** row *************************** id: 5 name: cluster-5 version: 1 created_at: 2024-01-20 22:05:16 updated_at: 2024-01-20 22:05:16 kubeconfig: {"name": "cluster5"} id: 5 name: cluster-10 version: 1 created_at: 2024-01-22 16:16:02 updated_at: 2024-01-22 16:16:02 kubeconfig: {"name": "cluster10"} 5 rows in set (0.00 sec) # 可以看到数据来了 # 去除重复行 mysql> select distinct id, name from clusters; +----+-----------+ | id | name | +----+-----------+ | 1 | cluster-1 | | 2 | cluster-2 | | 3 | cluster-3 | | 4 | cluster-4 | | 5 | cluster-5 | | 6 | cluster-1 | +----+-----------+ 6 rows in set (0.00 sec) # 可以看到 id 6 的 name 和 id 1 的 name 重复了,那么我们来去除这个重复行 mysql> select distinct name from clusters; +-----------+ | name | +-----------+ | cluster-1 | | cluster-2 | | cluster-3 | | cluster-4 | | cluster-5 | +-----------+ # 我们还可以使用聚合函数计算统计信息 # 计算总数据的数量 mysql> select count(name) from clusters; +-------------+ | count(name) | +-------------+ | 6 | +-------------+ 1 row in set (0.00 sec) # 计算所有数据的平均值 mysql> select avg(id) from clusters; +---------+ | avg(id) | +---------+ | 3.5000 | +---------+ 1 row in set (0.00 sec) # 计算所有数据的总和 mysql> select sum(id) from clusters; +---------+ | sum(id) | +---------+ | 21 | +---------+ 1 row in set (0.00 sec) # 计算数据的最大值 mysql> select max(id) from clusters; +---------+ | max(id) | +---------+ | 6 | +---------+ 1 row in set (0.00 sec) # 计算数据的最小值 mysql> select min(id) from clusters; +---------+ | min(id) | +---------+ | 1 | +---------+ 1 row in set (0.00 sec) # 除此之外还有 group by 进行分组 mysql> select count(*) as count, name FROM clusters group by name; +-------+-----------+ | count | name | +-------+-----------+ | 2 | cluster-1 | | 1 | cluster-2 | | 1 | cluster-3 | | 1 | cluster-4 | | 1 | cluster-5 | +-------+-----------+ mysql> select count(*) as count, name FROM clusters group by name having count >= 2; +-------+-----------+ | count | name | +-------+-----------+ | 2 | cluster-1 | +-------+-----------+ 1 row in set (0.00 sec) # 其次我们还可以嵌套查询 mysql> select id, name from clusters where name in (select name from clusters); +----+-----------+ | id | name | +----+-----------+ | 1 | cluster-1 | | 2 | cluster-2 | | 3 | cluster-3 | | 4 | cluster-4 | | 5 | cluster-5 | | 6 | cluster-1 | +----+-----------+ 6 rows in set (0.00 sec) 2:insert 语句 # 插入数据 mysql> insert into clusters (name, version, created_at, updated_at, kubeconfig) values ('cluster-2', 1, NOW(), NOW(), '{"name": "cluster2"}'); Query OK, 1 row affected (0.01 sec) mysql> select * from clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 1 | cluster-1 | 1 | 2024-01-20 22:04:39 | 2024-01-20 22:04:39 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | 2024-01-20 22:04:59 | 2024-01-20 22:04:59 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | 2024-01-20 22:05:05 | 2024-01-20 22:05:05 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | 2024-01-20 22:05:11 | 2024-01-20 22:05:11 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | 2024-01-20 22:05:16 | 2024-01-20 22:05:16 | {"name": "cluster5"} | | 6 | cluster-1 | 1 | 2024-01-22 19:27:51 | 2024-01-22 19:27:51 | {"name": "cluster1"} | | 7 | cluster-2 | 1 | 2024-01-22 22:19:13 | 2024-01-22 22:19:13 | {"name": "cluster2"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 7 rows in set (0.00 sec) # 还有基于条件的插入数据,不过这个要谨慎使用了 3:delete 语句 # 我们需要记住,删除操作的时候我们最好是开启事务,确认好了之后再 commit,这样可以保证我们的数据是安全删除,其次就是有确认 sql 的可能性 # 删除满足条件的记录 mysql> select * from clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 1 | cluster-1 | 1 | 2024-01-20 22:04:39 | 2024-01-20 22:04:39 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | 2024-01-20 22:04:59 | 2024-01-20 22:04:59 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | 2024-01-20 22:05:05 | 2024-01-20 22:05:05 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | 2024-01-20 22:05:11 | 2024-01-20 22:05:11 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | 2024-01-20 22:05:16 | 2024-01-20 22:05:16 | {"name": "cluster5"} | | 6 | cluster-1 | 1 | 2024-01-22 19:27:51 | 2024-01-22 19:27:51 | {"name": "cluster1"} | | 7 | cluster-2 | 1 | 2024-01-22 22:19:13 | 2024-01-22 22:19:13 | {"name": "cluster2"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 7 rows in set (0.00 sec) # 删除 ID 大于 5 的数据 mysql> delete from clusters where id > 5; Query OK, 2 rows affected (0.01 sec) mysql> select * from clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 1 | cluster-1 | 1 | 2024-01-20 22:04:39 | 2024-01-20 22:04:39 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | 2024-01-20 22:04:59 | 2024-01-20 22:04:59 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | 2024-01-20 22:05:05 | 2024-01-20 22:05:05 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | 2024-01-20 22:05:11 | 2024-01-20 22:05:11 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | 2024-01-20 22:05:16 | 2024-01-20 22:05:16 | {"name": "cluster5"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 5 rows in set (0.00 sec) # 我们还可以删除部分行数 mysql> delete from clusters limit 5; Query OK, 5 rows affected (0.01 sec) mysql> select * from clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 8 | cluster-1 | 1 | 2024-01-22 22:24:51 | 2024-01-22 22:24:51 | {"name": "cluster1"} | | 9 | cluster-2 | 1 | 2024-01-22 22:24:56 | 2024-01-22 22:24:56 | {"name": "cluster2"} | | 10 | cluster-3 | 1 | 2024-01-22 22:25:01 | 2024-01-22 22:25:01 | {"name": "cluster3"} | | 11 | cluster-4 | 1 | 2024-01-22 22:25:07 | 2024-01-22 22:25:07 | {"name": "cluster4"} | | 12 | cluster-5 | 1 | 2024-01-22 22:25:12 | 2024-01-22 22:25:12 | {"name": "cluster5"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 5 rows in set (0.00 sec) mysql> select * from clusters; Empty set (0.00 sec) # 我们还可以删除数据库中重复的记录 mysql> select * from clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 8 | cluster-1 | 1 | 2024-01-22 22:24:51 | 2024-01-22 22:24:51 | {"name": "cluster1"} | | 9 | cluster-2 | 1 | 2024-01-22 22:24:56 | 2024-01-22 22:24:56 | {"name": "cluster2"} | | 10 | cluster-3 | 1 | 2024-01-22 22:25:01 | 2024-01-22 22:25:01 | {"name": "cluster3"} | | 11 | cluster-4 | 1 | 2024-01-22 22:25:07 | 2024-01-22 22:25:07 | {"name": "cluster4"} | | 12 | cluster-5 | 1 | 2024-01-22 22:25:12 | 2024-01-22 22:25:12 | {"name": "cluster5"} | | 13 | cluster-1 | 1 | 2024-01-22 22:25:53 | 2024-01-22 22:25:53 | {"name": "cluster1"} | | 14 | cluster-2 | 1 | 2024-01-22 22:25:59 | 2024-01-22 22:25:59 | {"name": "cluster2"} | | 15 | cluster-3 | 1 | 2024-01-22 22:26:04 | 2024-01-22 22:26:04 | {"name": "cluster3"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 8 rows in set (0.00 sec) mysql> DELETE t1 FROM clusters t1 -> INNER JOIN clusters t2 -> WHERE t1.id > t2.id AND t1.name = t2.name; Query OK, 3 rows affected (0.00 sec) mysql> select * from clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 8 | cluster-1 | 1 | 2024-01-22 22:24:51 | 2024-01-22 22:24:51 | {"name": "cluster1"} | | 9 | cluster-2 | 1 | 2024-01-22 22:24:56 | 2024-01-22 22:24:56 | {"name": "cluster2"} | | 10 | cluster-3 | 1 | 2024-01-22 22:25:01 | 2024-01-22 22:25:01 | {"name": "cluster3"} | | 11 | cluster-4 | 1 | 2024-01-22 22:25:07 | 2024-01-22 22:25:07 | {"name": "cluster4"} | | 12 | cluster-5 | 1 | 2024-01-22 22:25:12 | 2024-01-22 22:25:12 | {"name": "cluster5"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 5 rows in set (0.00 sec) # 这个 SQL 的意思是 使用 JOIN 子句来连接 clusters 表中的两个副本 t1 和 t2。然后,它会使用 WHERE 子句来删除 t1 表中的记录,其中 t1.id 大于 t2.id 并且 t1.name 等于 t2.name。 # 模拟删除数据误删了 mysql> select * from clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 1 | cluster-1 | 1 | 2024-01-23 05:44:43 | 2024-01-23 05:44:43 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | 2024-01-23 05:44:47 | 2024-01-23 05:44:47 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | 2024-01-23 05:44:53 | 2024-01-23 05:44:53 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | 2024-01-23 05:44:58 | 2024-01-23 05:44:58 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | 2024-01-23 05:45:02 | 2024-01-23 05:45:02 | {"name": "cluster5"} | | 6 | cluster-6 | 1 | 2024-01-23 05:51:18 | 2024-01-23 05:51:18 | {"name": "cluster6"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 6 rows in set (0.00 sec) # 开启事务 mysql> begin; Query OK, 0 rows affected (0.00 sec) # 删除数据 mysql> delete from clusters where id = 6; Query OK, 1 row affected (0.00 sec) # 查看到数据已经被删了,但是开启了事务,那么我们可以回滚 mysql> select * from clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 1 | cluster-1 | 1 | 2024-01-23 05:44:43 | 2024-01-23 05:44:43 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | 2024-01-23 05:44:47 | 2024-01-23 05:44:47 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | 2024-01-23 05:44:53 | 2024-01-23 05:44:53 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | 2024-01-23 05:44:58 | 2024-01-23 05:44:58 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | 2024-01-23 05:45:02 | 2024-01-23 05:45:02 | {"name": "cluster5"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 5 rows in set (0.00 sec) # 执行回滚 mysql> rollback; Query OK, 0 rows affected (0.00 sec) # 再次查看数据 mysql> select * from clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 1 | cluster-1 | 1 | 2024-01-23 05:44:43 | 2024-01-23 05:44:43 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | 2024-01-23 05:44:47 | 2024-01-23 05:44:47 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | 2024-01-23 05:44:53 | 2024-01-23 05:44:53 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | 2024-01-23 05:44:58 | 2024-01-23 05:44:58 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | 2024-01-23 05:45:02 | 2024-01-23 05:45:02 | {"name": "cluster5"} | | 6 | cluster-6 | 1 | 2024-01-23 05:51:18 | 2024-01-23 05:51:18 | {"name": "cluster6"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 6 rows in set (0.00 sec) # 可以看到数据回滚回来了,那么这个就是事务的好处,如果确认了数据没有删错,我们直接执行 commit 就可以确认删除数据了 4:update 语句 # 更新数据 mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> update clusters set version = 2 where id = 1; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 1 | cluster-1 | 2 | 2024-01-23 05:44:43 | 2024-01-23 05:44:43 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | 2024-01-23 05:44:47 | 2024-01-23 05:44:47 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | 2024-01-23 05:44:53 | 2024-01-23 05:44:53 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | 2024-01-23 05:44:58 | 2024-01-23 05:44:58 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | 2024-01-23 05:45:02 | 2024-01-23 05:45:02 | {"name": "cluster5"} | | 6 | cluster-6 | 1 | 2024-01-23 05:51:18 | 2024-01-23 05:51:18 | {"name": "cluster6"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 6 rows in set (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.01 sec) mysql> select * from clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 1 | cluster-1 | 2 | 2024-01-23 05:44:43 | 2024-01-23 05:44:43 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | 2024-01-23 05:44:47 | 2024-01-23 05:44:47 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | 2024-01-23 05:44:53 | 2024-01-23 05:44:53 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | 2024-01-23 05:44:58 | 2024-01-23 05:44:58 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | 2024-01-23 05:45:02 | 2024-01-23 05:45:02 | {"name": "cluster5"} | | 6 | cluster-6 | 1 | 2024-01-23 05:51:18 | 2024-01-23 05:51:18 | {"name": "cluster6"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 6 rows in set (0.00 sec) # 我们还可以改多条数据 Database changed mysql> update clusters set version = 2 where id in (1,2,3); Query OK, 2 rows affected (0.00 sec) Rows matched: 3 Changed: 2 Warnings: 0 mysql> select * from clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 1 | cluster-1 | 2 | 2024-01-23 05:44:43 | 2024-01-23 05:44:43 | {"name": "cluster1"} | | 2 | cluster-2 | 2 | 2024-01-23 05:44:47 | 2024-01-23 05:44:47 | {"name": "cluster2"} | | 3 | cluster-3 | 2 | 2024-01-23 05:44:53 | 2024-01-23 05:44:53 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | 2024-01-23 05:44:58 | 2024-01-23 05:44:58 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | 2024-01-23 05:45:02 | 2024-01-23 05:45:02 | {"name": "cluster5"} | | 6 | cluster-6 | 1 | 2024-01-23 05:51:18 | 2024-01-23 05:51:18 | {"name": "cluster6"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 6 rows in set (0.00 sec)
5:DCL(数据库控制语言)
DCL 理论上包括 GRANT,REVORK 语句,但是这个放在权限讲可能更合适
1:连接方式
TCP/IP 套接字方式是网络中使用的最多的一种方式,CS 通信下最常用,client 和 server 端可以不在一个服务器上 root@ubuntu:~# mysql -u<username> -p<password> -P <port> -h <ipaddress> 1:<username>:数据库的账号 2:<password>:数据库的密码 3:<port>:数据库服务器的端口 4:<ipaddress>:数据库服务器的地址 其次就是我们还可以使用 Unix 域 套接字,但是这个只能在数据库服务器上使用 root@ubuntu:~# mysql -u<username> -p<password> --socket=<sock_path> 1:<username>:数据库的账号 2:<password>:数据库的密码 3:<sock_path>:数据库的 sock 文件
2:权限管理
`# 在 MySQL 中,一个可用的账号 = 用户 + 主机 + 密码 mysql> select user,host,authentication_string from mysql.user where user = 'root'; +------+-----------+------------------------------------------------------------------------+ | user | host | authentication_string | +------+-----------+------------------------------------------------------------------------+ | root | localhost | $A$005$ uoum[m[O!E9pPDSX1zHBlKwS8GC/Ajo3rPIBMHbfIRYL5ovJL9H6 | +------+-----------+------------------------------------------------------------------------+ 1 row in set (0.01 sec) mysql> select user,host,concat(user,'@',''',host,'''), authentication_string from mysql.user; +------------------+-----------+-------------------------------+------------------------------------------------------------------------+ | user | host | concat(user,'@',''',host,''') | authentication_string | +------------------+-----------+-------------------------------+------------------------------------------------------------------------+ | mysql.infoschema | localhost | mysql.infoschema@',host,' | $A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED | | mysql.session | localhost | mysql.session@',host,' | $A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED | | mysql.sys | localhost | mysql.sys@',host,' | $A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED | | root | localhost | root@',host,' | $A$005$ uoum[m[O!E9pPDSX1zHBlKwS8GC/Ajo3rPIBMHbfIRYL5ovJL9H6 | +------------------+-----------+-------------------------------+------------------------------------------------------------------------+ 4 rows in set (0.00 sec) # 创建用户,授权,回收权限 mysql> create user 'g8s_admin'@'%' identified with caching_sha2_password by 'MTIzNDU2Cg=='; Query OK, 0 rows affected (0.02 sec) mysql> select user,host,concat(user,'@',''',host,'''), authentication_string from mysql.user; +------------------+-----------+-------------------------------+------------------------------------------------------------------------+ | user | host | concat(user,'@',''',host,''') | authentication_string | +------------------+-----------+-------------------------------+------------------------------------------------------------------------+ | g8s_admin | % | g8s_admin@',host,' | $A$005$8>tqM'zIO# +uT:shyPtYmFmKaXKC5utHWIrkS0JNlSZriiG0pUP2qAv20 | | mysql.infoschema | localhost | mysql.infoschema@',host,' | $A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED | | mysql.session | localhost | mysql.session@',host,' | $A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED | | mysql.sys | localhost | mysql.sys@',host,' | $A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED | | root | localhost | root@',host,' | $A$005$ uoum[m[O!E9pPDSX1zHBlKwS8GC/Ajo3rPIBMHbfIRYL5ovJL9H6 | +------------------+-----------+-------------------------------+------------------------------------------------------------------------+ 5 rows in set (0.00 sec) # 授权 mysql> grant select on g8s_manager.* to 'g8s_admin'@'%'; Query OK, 0 rows affected (0.00 sec) # 授权 select 权限给 g8s_manager 数据库中的所有表给用户 'g8s_admin'@'%' root@ubuntu:~# mysql -ug8s_admin -p$password ... mysql> show databases; +--------------------+ | Database | +--------------------+ | g8s_manager | | information_schema | | performance_schema | +--------------------+ 3 rows in set (0.02 sec) # select 权限 mysql> select * from g8s_manager.clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 1 | cluster-1 | 1 | 2024-01-23 05:44:43 | 2024-01-23 05:44:43 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | 2024-01-23 05:44:47 | 2024-01-23 05:44:47 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | 2024-01-23 05:44:53 | 2024-01-23 05:44:53 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | 2024-01-23 05:44:58 | 2024-01-23 05:44:58 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | 2024-01-23 05:45:02 | 2024-01-23 05:45:02 | {"name": "cluster5"} | | 6 | cluster-6 | 1 | 2024-01-23 05:51:18 | 2024-01-23 05:51:18 | {"name": "cluster6"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 6 rows in set (0.00 sec) # drop 表 mysql> drop table g8s_manager.clusters; ERROR 1142 (42000): DROP command denied to user 'g8s_admin'@'localhost' for table 'clusters' # 可以看到权限不足,然后我们回收权限 mysql> revoke select on g8s_manager.* from 'g8s_admin'@'%'; Query OK, 0 rows affected (0.00 sec) # 再次登录 # 查询库 mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | performance_schema | +--------------------+ 2 rows in set (0.00 sec) # 查询数据,权限不足了 mysql> select * from g8s_manager.clusters; ERROR 1142 (42000): SELECT command denied to user 'g8s_admin'@'localhost' for table 'clusters' # 这里我们要扩展一个知识点:比如你授权的时候给一个用户授权了 % 为所有权限,然后又授权了 10.0.0.% 为只读权限,那么当你用 10.0.0.x 网段登录的时候,权限也只有只读而并非所有权限,这个是 MySQL 权限的优先级 # 其次就是我们要给大家扩展一下 MySQL 8.0 中的 Role 的功能,我们都知道 角色其实就是一组权限的集合,所以我们可以根据角色来将一组权限分配给某个用户,我们来熟悉一下 Role # 创建角色 mysql> create role cpc_develop; Query OK, 0 rows affected (0.00 sec) mysql> create role cpc_operation; Query OK, 0 rows affected (0.00 sec) mysql> create role cpc_admin; Query OK, 0 rows affected (0.01 sec) # 可以看到这里创建了三个角色,分别是 cpc 项目的开发角色,运维角色,管理角色 # 创建用户 mysql> create user 'cpc_develop_jiasen'@'%' identified by 'MTIzNDU2Cg=='; Query OK, 0 rows affected (0.00 sec) mysql> create user 'cpc_operation_dangjiaqi'@'%' identified by 'MTIzNDU2Cg=='; Query OK, 0 rows affected (0.01 sec) mysql> create user 'cpc_admin_zhaoziyao'@'%' identified by 'MTIzNDU2Cg=='; Query OK, 0 rows affected (0.01 sec) # 为相应角色授权(将多个权限加入到角色内) mysql> grant create,update,select,insert on cpc.* to cpc_develop; Query OK, 0 rows affected (0.00 sec) mysql> grant create,update,select,insert,alter,delete on cpc.* to cpc_operation; Query OK, 0 rows affected (0.00 sec) mysql> grant all on cpc.* to cpc_admin; Query OK, 0 rows affected (0.00 sec) # 将角色授权给特定用户 mysql> grant cpc_develop to 'cpc_develop_jiasen'@'%'; Query OK, 0 rows affected (0.00 sec) mysql> grant cpc_operation to 'cpc_operation_dangjiaqi'@'%'; Query OK, 0 rows affected (0.00 sec) mysql> grant cpc_admin to 'cpc_admin_zhaoziyao'@'%'; Query OK, 0 rows affected (0.00 sec) # 分别测试三个用户(用户登录后要激活权限哦) mysql> show grants; +-----------------------------------------------------+ | Grants for cpc_develop_jiasen@% | +-----------------------------------------------------+ | GRANT USAGE ON *.* TO `cpc_develop_jiasen`@`%` | | GRANT `cpc_develop`@`%` TO `cpc_develop_jiasen`@`%` | +-----------------------------------------------------+ 2 rows in set (0.00 sec) # 激活角色 mysql> set role cpc_develop; Query OK, 0 rows affected (0.00 sec) # 测试权限 insert 权限 mysql> insert into cpc.clusters (name, version, created_at, updated_at, kubeconfig) values ('cluster-6', 1, NOW(), NOW(), '{"name": "cluster6"}'); Query OK, 1 row affected (0.01 sec) # 查询数据权限 mysql> select * from cpc.clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 1 | cluster-1 | 1 | 2024-01-24 14:12:57 | 2024-01-24 14:12:57 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | 2024-01-24 14:13:05 | 2024-01-24 14:13:05 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | 2024-01-24 14:13:10 | 2024-01-24 14:13:10 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | 2024-01-24 14:13:14 | 2024-01-24 14:13:14 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | 2024-01-24 14:13:20 | 2024-01-24 14:13:20 | {"name": "cluster5"} | | 6 | cluster-6 | 1 | 2024-01-24 15:23:39 | 2024-01-24 15:23:39 | {"name": "cluster6"} | +----+-----------+---------+---------------------+---------------------+----------------------+ 6 rows in set (0.00 sec) # 没有 delete 权限 mysql> drop table cpc_developer.clusters; ERROR 1142 (42000): DROP command denied to user 'cpc_develop_jiasen'@'localhost' for table 'clusters' # 其次我们再来测试一下其他权限 mysql> set role cpc_operation; Query OK, 0 rows affected (0.00 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | cpc | | information_schema | | performance_schema | +--------------------+ 3 rows in set (0.01 sec) mysql> show tables from cpc; +---------------+ | Tables_in_cpc | +---------------+ | clusters | +---------------+ 1 row in set (0.00 sec) # 删除数据 mysql> delete from cpc.clusters where id = 6; Query OK, 1 row affected (0.00 sec) # 查询数据 mysql> select * from cpc.clusters; +----+-----------+---------+---------------------+---------------------+----------------------+ | id | name | version | created_at | updated_at | kubeconfig | +----+-----------+---------+---------------------+---------------------+----------------------+ | 1 | cluster-1 | 1 | 2024-01-24 14:12:57 | 2024-01-24 14:12:57 | {"name": "cluster1"} | | 2 | cluster-2 | 1 | 2024-01-24 14:13:05 | 2024-01-24 14:13:05 | {"name": "cluster2"} | | 3 | cluster-3 | 1 | 2024-01-24 14:13:10 | 2024-01-24 14:13:10 | {"name": "cluster3"} | | 4 | cluster-4 | 1 | 2024-01-24 14:13:14 | 2024-01-24 14:13:14 | {"name": "cluster4"} | | 5 | cluster-5 | 1 | 2024-01-24 14:13:20 | 2024-01-24 14:13:20 | {"name": "cluster5"} | +----+-----------+---------+---------------------+---------------------+----------------------+ # 删除数据表的权限 mysql> drop table cpc.clusters; ERROR 1142 (42000): DROP command denied to user 'cpc_operation_dangjiaqi'@'localhost' for table 'clusters' # 测试 cpc_admin 角色权限的用户 mysql> set role cpc_admin; Query OK, 0 rows affected (0.00 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | cpc | | information_schema | | performance_schema | +--------------------+ 3 rows in set (0.01 sec) mysql> show tables from cpc; +---------------+ | Tables_in_cpc | +---------------+ | clusters | +---------------+ 1 row in set (0.01 sec) mysql> drop table clusters; Query OK, 0 rows affected (0.01 sec) mysql> show tables; Empty set (0.01 sec) # 那么这个就是角色的概念和使用 # 各种版本权限管理命令的变化(6,7,8.0) password函数在不同 MySQL 版本下面加密的结果一致,MySQL 8.0 版本中,password 函数被取消 `
|
| show grants for | show create user | grant select on *.* to *.* identified by ‘xxx’ | mysql.user 表密码串字段 |
| — | — | — | — | — |
| 55 | 权限 + 密码 | 不可用 | 可用 | password |
| 7 | 权限 | 用户密码 | 可用 | authentication_string |
| 8.0 | 权限 | 用户密码 | 不可用 | authentication_string |
3:常规函数
| 说明 | 函数 |
|---|---|
| 字符串函数 | CONCAT,SUBSTRING,LENGTH,UPPER,LOWER,TRIM,REPLACE … |
| 数值函数 | ABS,ROUNO,CEIL,FLOOR,MOD,RAND … |
| 日期和时间函数 | NOW,CURDATE,CURTIME,TIME,YEAR,MONTH,DAY … |
| 条件函数 | IF,CASE(一般存储过程等写,不建议 MySQL 中使用存储过程,业务逻辑尽量再业务代码中实现) … |
| 聚合函数 | COUNT,SUM,AVG,MIN,MAX(一般查询中用) … |
| 分组函数 | GROUP,CONCAT,GROUP BY … |
| 转换函数 | CAST,CONVENRT … |
| 数据类型函数 | CAST,CONVERT,DATE_FORMAT … |
| 数据库函数 | DATABASE,USER,VERSION … |
| 系统函数 | SLEEP … |
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
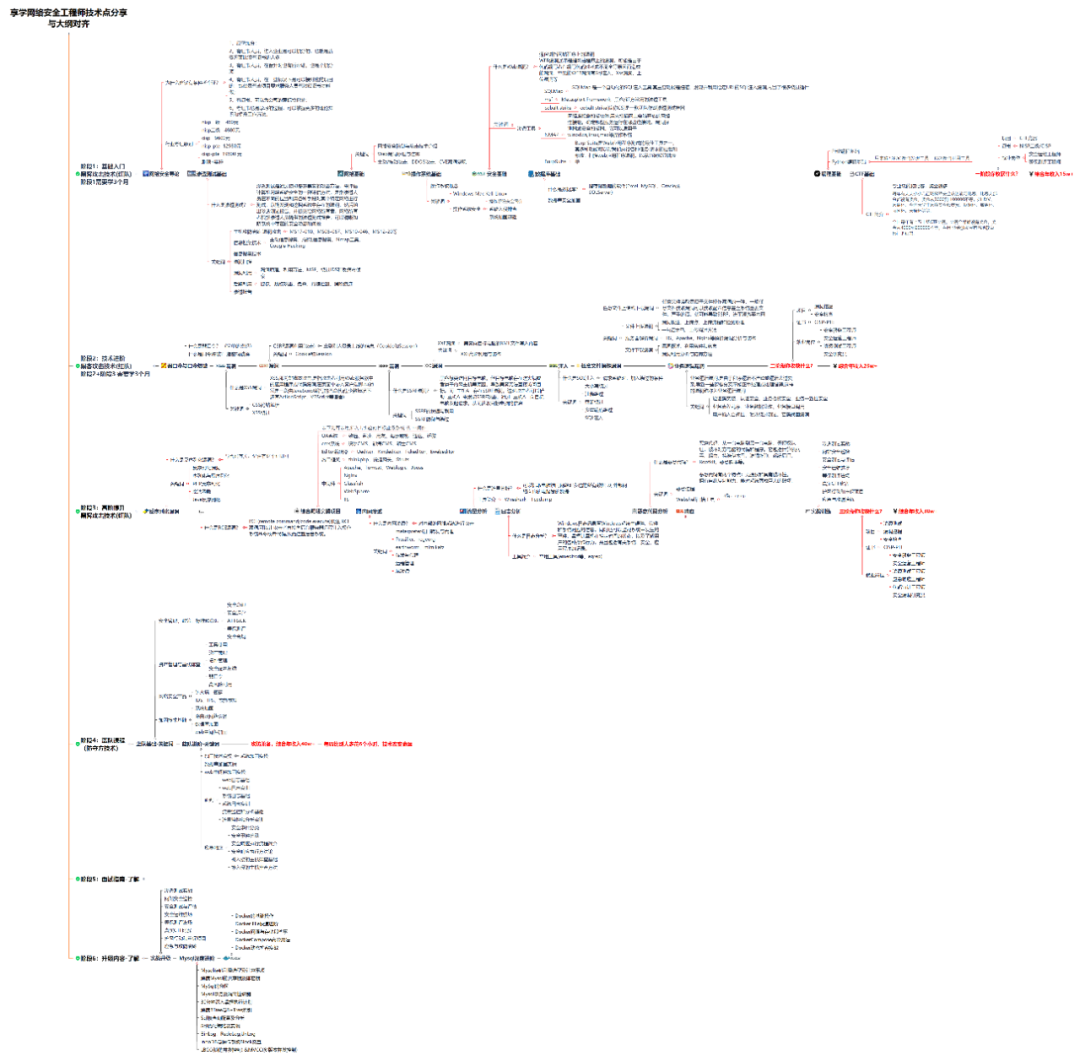
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。

(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









