



在C语言编程中,双向链表是一种功能强大的数据结构,它就像一条灵活的双车道公路,允许我们在两个方向上自由穿梭。今天,我将带你深入了解C语言双向链表的奥秘,从它的结构、实现,到与顺序表的对比分析,让你全面掌握这一重要技能。
双向链表的结构
双向链表是一种链表结构,其中每个节点包含两个指针,一个指向前驱节点(previous),一个指向后继节点(next)。这种结构使得我们可以在链表中双向遍历,灵活地访问前后节点。
• 节点结构:每个节点包含三个部分——数据域(data)和两个指针域(previous和next)。数据域存储节点的数据,previous指针指向当前节点的前驱节点,next指针指向当前节点的后继节点。
• 头节点和尾节点:头节点是双向链表的第一个节点,尾节点是双向链表的最后一个节点。尾节点的next指针通常指向NULL,表示链表的结束。头节点的previous指针也指向NULL。
• 双向链表的类型:常见的双向链表有带头双向循环链表、不带头双向循环链表、双向链表等,它们在具体实现和应用场景上有所不同。
实现双向链表
创建双向循环链表
创建双向循环链表时,我们需要初始化头节点,并通过循环将各个数据节点连接起来,形成一个循环结构。以下是创建双向循环链表的代码示例:
#include <stdio.h>
#include <stdlib.h>
// 定义双向循环链表的节点结构
typedef struct DNode {
int data;
struct DNode* prior; // 指向前驱节点
struct DNode* next; // 指向后继节点
} DNode;
// 创建双向循环链表(带头节点)
DNode* createDoublyCircularLinkedList(int arr[], int n) {
if (n <= 0) return NULL;
// 创建头节点
DNode* head = (DNode*)malloc(sizeof(DNode));
head->prior = NULL;
head->next = NULL;
head->data = arr[0]; // 头节点的数据(可选)
DNode* current = head;
for (int i = 1; i < n; i++) {
// 创建新节点
DNode* newNode = (DNode*)malloc(sizeof(DNode));
newNode->data = arr[i];
newNode->prior = current;
newNode->next = head;
// 将新节点连接到链表末尾
current->next = newNode;
current = newNode;
// 更新头节点的前驱指针指向尾节点
head->prior = current;
}
return head;
}
双向链表的插入操作
在双向链表中插入节点时,需要更新相关节点的previous和next指针,以维护链表的完整性。以下是插入节点的代码示例:
// 在双向链表中插入节点
void insertDoublyLinkedList(DNode** head, int position, int value) {
if (position < 0) return;
DNode* newNode = (DNode*)malloc(sizeof(DNode));
newNode->data = value;
if (position == 0) {
// 在链表头部插入
newNode->next = *head;
newNode->prior = (*head)->prior;
(*head)->prior->next = newNode;
(*head)->prior = newNode;
*head = newNode;
} else {
// 查找插入位置的前驱节点
DNode* current = *head;
for (int i = 0; i < position - 1 && current != NULL; i++) {
current = current->next;
}
if (current != NULL) {
// 插入新节点
newNode->next = current->next;
newNode->prior = current;
if (current->next != NULL) {
current->next->prior = newNode;
}
current->next = newNode;
}
}
}
双向链表的删除操作
删除双向链表中的节点时,同样需要更新相关节点的previous和next指针,以保持链表的连贯性。以下是删除节点的代码示例:
// 删除双向链表中的节点
void deleteDoublyLinkedList(DNode** head, int position) {
if (position < 0 || *head == NULL) return;
if (position == 0) {
// 删除链表头部节点
DNode* temp = *head;
*head = (*head)->next;
if (*head != NULL) {
(*head)->prior = temp->prior;
}
free(temp);
return;
}
// 查找删除位置的前驱节点
DNode* current = *head;
for (int i = 0; i < position - 1 && current != NULL; i++) {
current = current->next;
}
if (current != NULL && current->next != NULL) {
// 删除节点
DNode* temp = current->next;
current->next = temp->next;
if (temp->next != NULL) {
temp->next->prior = current;
}
free(temp);
}
}
遍历双向链表
遍历双向链表时,可以从头节点开始向后遍历,也可以从尾节点开始向前遍历。以下是遍历双向链表的代码示例:
// 遍历双向链表(从头到尾)
void traverseDoublyLinkedListForward(DNode* head) {
DNode* current = head;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("\n");
}
// 遍历双向链表(从尾到头)
void traverseDoublyLinkedListBackward(DNode* head) {
DNode* current = head->prior; // 从尾节点开始
while (current != NULL) {
printf("%d ", current->data);
current = current->prior;
}
printf("\n");
}
顺序表和双向链表的对比分析
数据结构对比
顺序表和双向链表是两种不同的数据结构,它们在存储方式、操作效率等方面存在显著差异:
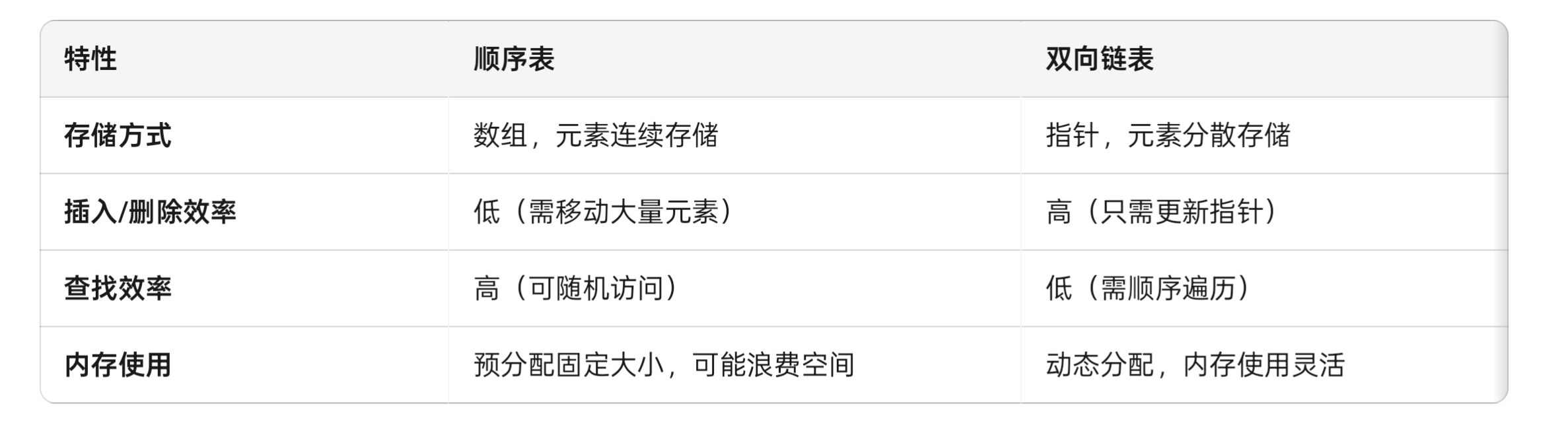
使用场景对比
• 顺序表适用场景:适用于数据量不大且数据频繁访问的场景,如小型数据集合的管理。
• 双向链表适用场景:适用于需要频繁插入和删除元素的场景,如实现需要双向遍历的数据结构(如某些类型的队列或栈)。
总结
通过本文的讲解,我们深入探讨了C语言双向链表的结构、实现方法以及与顺序表的对比分析。双向链表的双向遍历特性使其在需要灵活插入和删除的场景中具有显著优势。希望这篇文章能帮助你更好地理解和应用双向链表,提升你在数据结构领域的编程技能。
在学习双向链表的过程中,你是否遇到过一些有趣的问题或挑战呢?欢迎在评论区留言分享,让我们一起交流学习!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









