



 本文是机器学习系列的中篇,重点讲解如何使用Kernel SVM解决非线性问题。介绍了非线性问题的概念,核方法的原理以及如何通过SVM的高斯核函数在高维空间中找到分隔超平面。文中还展示了Kernel SVM在非线性数据集和iris数据集上的应用效果,并讨论了调整gamma参数对模型过拟合的影响。
本文是机器学习系列的中篇,重点讲解如何使用Kernel SVM解决非线性问题。介绍了非线性问题的概念,核方法的原理以及如何通过SVM的高斯核函数在高维空间中找到分隔超平面。文中还展示了Kernel SVM在非线性数据集和iris数据集上的应用效果,并讨论了调整gamma参数对模型过拟合的影响。
机器学习系列专栏
选自 Python-Machine-Learning-Book On GitHub
作者:Sebastian Raschka
翻译&整理 By Sam
经过上一篇的简单介绍入门,相信大家有一定的认识,本篇内容是续集,上篇的内容可以点击查看哦!
由于文章篇幅较长,还是先把本文的结构贴在前面,如下:
上篇:
Scikit-Learn初认识
使用Scikit-Learn训练感知器
使用逻辑回归构建一个概率类的分类模型
逻辑回归的激活函数
逻辑回归的损失函数
使用sklearn训练一个逻辑回归模型
使用正则化处理过拟合
上篇传说门:
中篇:(有修订)
使用Kernel-SVM来解决非线性问题
什么是非线性问题
核方法函数及原理
利用核技巧Kernel-SVM在高维空间中寻找分隔超平面
下篇:(新增)
机器学习决策树模型
最大化信息增益-获得最大的提升度
建立决策树
通过随机森林将“弱者”与“强者”模型集成
K近邻分类模型(一个懒惰的算法)
参考文献
PS:代码已单独保存:可在公众号后台输入“sklearn”进行获取ipynb文件
使用Kernel-SVM来解决非线性问题
什么是非线性问题
关于线性和非线性问题的区别,大家应该也有一定的概念,如下图:
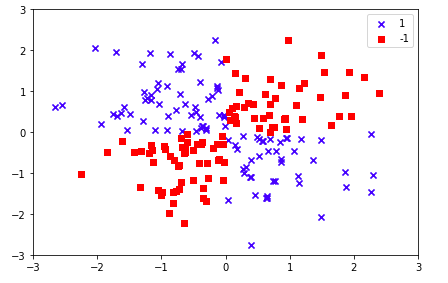
很明显,我们是无法通过线性的方法来达到分类的目的,这样子的问题我们统称为“非线性问题”(个人直观定义,不是很专业严谨)
核方法函数及原理
什么是核方法?核方法就是在原来特征基础上创造出非线性的组合,然后利用映射函数将现有特征维度映射到更高维的特征空间,并且这个高维度特征空间能够使得原来线性不可分数据变成了线性可分的。
同样是上面的数据,其实我们是可以做一定的处理来达到线性分类的目的的,而这个处理就是核方法了。
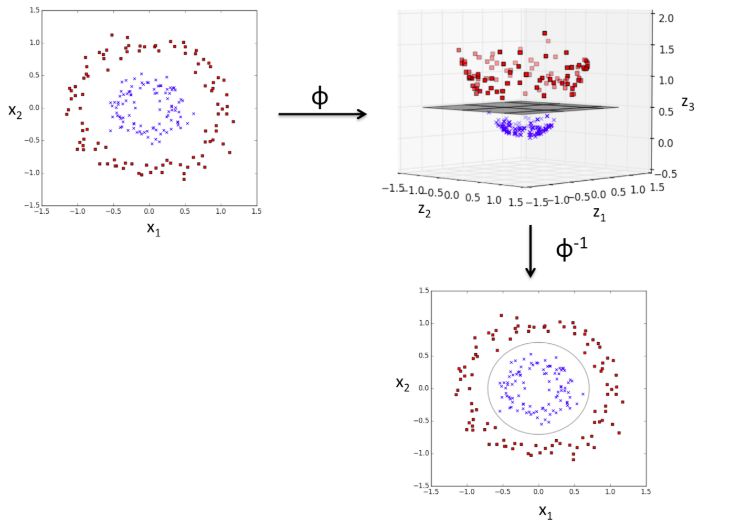
从上图可以看出,高维空间中的线性决策界实际上是低维空间的非线性决策界,这个非线性决策界是线性分类器找不到的,但是通过核方法就找到了。
而我们通过使用SVM(支持向量机)来达到上面的原理,支持向量机是基于线性划分的,它的原理是将低维空间中的点映射到高维空间中,使它们成为线性可分的。再使用线性划分的原理来判断分类边界。在高维空间中,它是一种线性划分,而在原有的数据空间中,它是一种非线性划分。
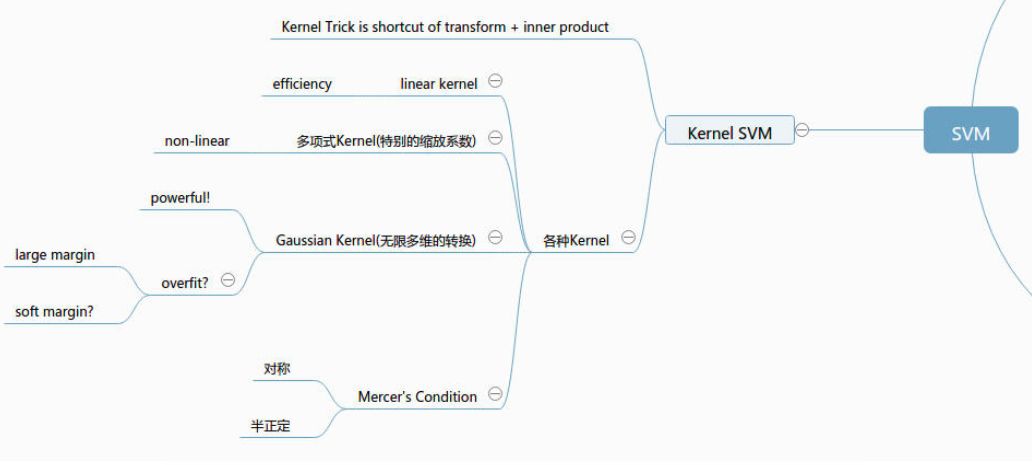
图:核函数的家族【更多内容见文献2】
利用核技巧kernel SVM在高维空间中寻找分隔超平面
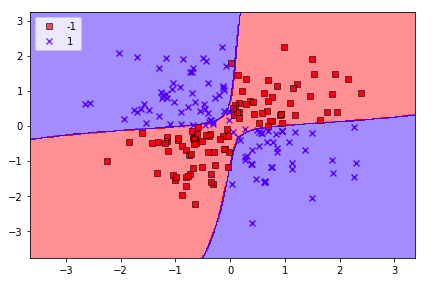
上面讲了那么原理,还是实践出真理,我们自己来通过核SVM来训练一个模型,我们用的数据还是上面的“非线性”数据集。
从下面的分类结果来看,Kernel SVM对于非线性的数据集分类的效果还是非常优秀的,其中我们用到的核函数是高斯核函数。
1from sklearn.svm import SVC
2svm = SVC(kernel='rbf', random_state=0, gamma=0.10, C=10.0)
3# kernel=‘rbf’:径向基函数 (Radial Basis Function 简称 RBF), 就是某种沿径向对称的标量函数,也成为高斯核函数
4# gamma:如果我们增大gamma值,会产生更加柔软的决策界
5svm.fit(X_xor, y_xor)
6plot_decision_regions(X_xor, y_xor,
7 classifier=svm)
8plt.legend(loc='upper left')
9plt.tight_layout()
10plt.show()
output:
我们试着把Kernel SVM应用在iris数据集看看效果。可以看出,分类的效果也是很好的,这里我们的gamma值(0.2)相比之前(0.1)是变大了,所以分类边界会显得更加“柔软”。
1from sklearn.svm import SVC
2# 为了显示中文(这里是Mac的解决方法,其他的大家可以去百度一下)
3from matplotlib.font_manager import FontProperties
4font = FontProperties(fname='/System/Library/Fonts/STHeiti Light.ttc')
5svm = SVC(kernel='rbf', random_state=0, gamma=0.2, C=1.0)
6svm.fit(X_train_std, y_train)
7# 这里的gamma值比上面的大,边界更加“柔软”
8plot_decision_regions(X_combined_std, y_combined,
9 classifier=svm, test_idx=range(105, 150))
10plt.xlabel('花瓣长度 [标准化后]',FontProperties=font,fontsize=14)
11plt.ylabel('花瓣宽度 [标准化后]',FontProperties=font,fontsize=14)
12plt.legend(loc='upper left')
13plt.tight_layout()
14plt.show()
output:
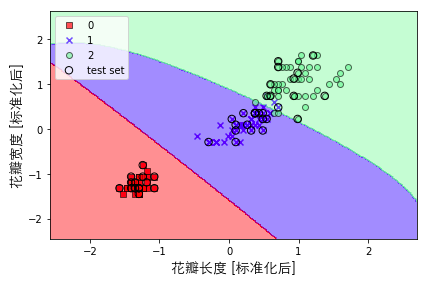
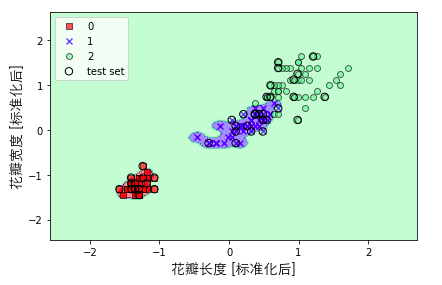
我们可以试着继续加大gamma值,可以看到其实决策边界是过度拟合,模型在训练集上的表现效果很好,但是泛化能力将会是一塌糊涂,所以,我们经常会通过控制gamma值来防止过拟合。
output:
参考文献
1. 核函数(Kernel Function)与SVM
https://blog.youkuaiyun.com/bitcarmanlee/article/details/77604484
2. 机器学习技法--Kernel SVM
https://www.jianshu.com/p/446fae533b17
3. 关于线性SVM以及非线性SVM的问题
https://blog.youkuaiyun.com/armily/article/details/8452879
4. 高斯核函数
https://baike.baidu.com/item/%E9%AB%98%E6%96%AF%E6%A0%B8%E5%87%BD%E6%95%B0/6661425?fr=aladdin

















 1296
1296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









