



 本文介绍了SAS在数据加工处理中的几个关键功能,包括proc format自定义格式、file和put语句定制报告、proc means描述数据、将统计量写入数据集以及proc freq和proc tabulate进行频率分析和表格报告。通过实例展示了如何使用这些工具来优化数据处理和报告生成。
本文介绍了SAS在数据加工处理中的几个关键功能,包括proc format自定义格式、file和put语句定制报告、proc means描述数据、将统计量写入数据集以及proc freq和proc tabulate进行频率分析和表格报告。通过实例展示了如何使用这些工具来优化数据处理和报告生成。
数据加工的函数真的好多,今天就写最后一篇了,以后大家还是根据自己需求去找呗~

1)proc format创建自己的格式
有时候用数字代表实际的变量值,比如1代表男性,2代表女性,这种代码在打印的时候不好解读,可以用proc format使得打印出想要的值。
基本形式为:

① Value语句中的name是格式的名字,如果格式是位字符串设计,则必须以$开头,长度不能超过32个字节(包括$),不能以数字结尾,除了下划线不能包含其他任何特殊符号;
② 名字不能与已有的格式名冲突;
③ Range是分配给等号右边文本的变量值,文本可以达到32767个字节,有的过程只会打印前面8或16个字节;
④ 变量值是字符串时要加上引号;
⑤ range不止一个值要用逗号隔开,连续的range要用-;
⑥ 关键字low和high可以用来指代变量中最小和最大的非缺失值;
⑦ 可以用<来排除或指代某些范围,但"<"来表示不包括范围的结尾值;
⑧ other可以给任何没有列在value语句中的变量分配格式。
2)利用file语句和put语句定制报告
用file语句和put语句 ,基本形式为:
FILE‘file-specification’PRINT;
如input,put语句也有list,column,formatted方式,但因为SAS已经知道变量类型,因此不用符号$。且如果使用list,SAS会自动在两个变量之间加上空格;使用column或者formatted,SAS将会把变量放在任何你指定的地方。使用指示器@n指定移动到第n列,+n指定移动n列,/跳动到下一行,#n跳动到第n行。用@hold住当前行。
这个比较难理解,还是举个例子~
学生卖糖果,数据集为Candy.dat,记录学生名、所属班级、销售日期、卖的糖果类型、卖出的糖果数。
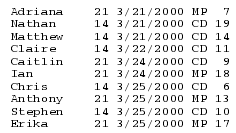
老师想看每位学生的销售情况,故要每页分别打印一位学生的情况,代码如下:
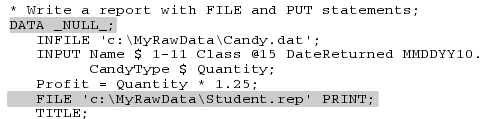

Data _null_是告诉SAS不要写数据集名,以便使得程序更快。File语句创建了一个输出文件,空标题title语句告诉SAS去除所有的自动标题。
第一个put语句以一个指示器开头,@5,告诉SAS移动到第5列,接着打印出“candysales report for”,后面是姓名name。变量name、class和quantity都是以list方式打印,而profit是使用formatted方式打印,并给定格式dollar6.2。一个斜杠是指跳到下一行,两个斜杠是跳到下两行。最后,语句put_page_是在每个学生报告下面插上页码。
前三页报告如下:



3)使用proc means描述数据
基本形式:
PROC MEANS options;
如果不加选项,则默认打印出非缺失值个数、均值、标准差、以及最大最小值,下面是用选项可以查看的统计量:

如果没有其他语句,proc means语句会给你数据集中所有观测值和所有数值变量的统计量,这里是一些可以用到的语句:
① BY variable-list; 分变量单独分析,但数据必须先按照variable-list的变量顺序排序(proc sort)。
② CLASS variable-list; 也是分变量单独分析,看起来会更集中一些,且不需要排序。
③ VAR variable-list; 指定分析中使用哪种数值变量,默认则使用所有的数值变量。
继续举例子~
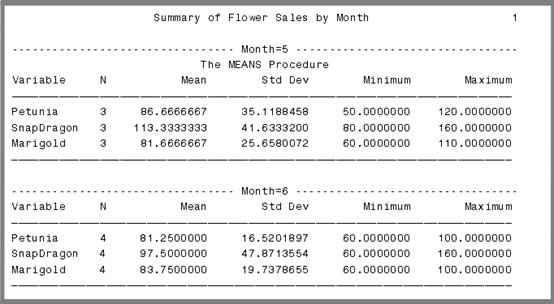
有一个花朵销售的数据,Flowers.dat,包括顾客ID,销售日期,petunias,snapdragons,marigolds三种花的销售量:
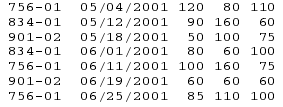
下面的代码读取数据,计算新变量销售月份month,并使用procsort按照月份排序,并使用procmeans的by语句来按照月份描述数据:
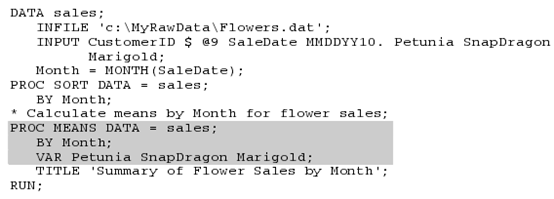
输出结果为:
4)将描述性统计写入SAS数据集中
有两种方法可以在SAS数据集中储存描述性统计量,Output Delivery System(ODS),或者output语句。这里主要讲output,其基本形式为:
OUTPUT OUT=data-set output-statistic-list;
Data-set是要储存结果的数据集名,output-statistic-list则界定需要保存哪些统计量和名称,可能的形式为:
statistic(variable-list)=name-list
statistic可能是proc means语句中的任何一种统计量(sum,n,mean…),variable-list则界定VAR语句中哪些变量需要输出,name-list则定义统计量的新名字。

Noprint是告诉SAS不需要产生任何打印结果,因为已经将结果存入数据集中。
5)用proc freq为数据计数
对一个变量计算频数叫做one-way,两个叫做two-way,多个叫做交叉表。使用proc freq最明显的目的是现实分类数据的分布情况,基本形式为:
PROC FREQ;
TABLES variable-combinations;
产生一维频率表,只要列出变量名。下面的语句列出了变量yearseducation的每一个值的个数。
TABLES YearsEducation;
建立两个变量的交叉表需要一个*号,下面的语句显示变量Sex by YearsEducation的频数情况:
TABLES Sex*YearsEducation;
这个语句之后可以用/option的形式添加选项,主要下面几个:
LIST:用list形式打印交叉表(而不是网格)
MISSING:频率统计量中包含缺失值
NOCOL:强制在交叉表中不打印列百分比
NOROW:强制在交叉表中不打印行百分比
OUT=data-set:输出数据集
例子:
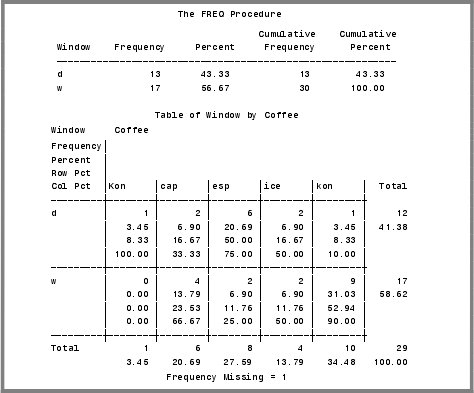
有一家咖啡店的销售数据,记录了销售的咖啡种类(cappuccino,espresso,kona,oriced coffee),以及每次购买的顾客是打包还是原地就饮:

下面的代码就产生了一个one-way和two-way的频率表:

代码告诉SAS打印两个表,一个是one-way的频率表,一个是交叉表。交叉表的每个小方格内,SAS打印了频数、百分比、行百分比和列百分比。左边和右边是累积百分比。注意计算频数时没有考虑缺失值。
6)用proc tabulate产生一个表格报告
比起print means和print freq,Proc tabulate过程产生的报告更耐看。
Proc tabulate的基本形式为:
PROC TABULATE;
CLASS classification-variable-list;
TABLE page-dimension,row-dimension,column-dimension;
Class语句告诉SAS哪些变量将数据分成不同部分。
Table语句可以定义一个表,可以用多个table语句定义多个表,
维度:table语句可以在报告中指定三个维度:页、行、列。如果只指定一个维度,则默认是列维度;如果指定两个,则是行和列。
缺失数据:默认下不考虑缺失数据,在proc语句后面增加missing选项可以改变这种默认:
PROC TABULATE MISSING;
例子:
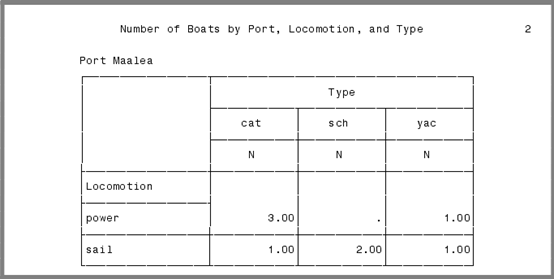
有关于船的一些数据,Boats.dat,记录了每艘船的姓名、港口、移动方式(sailing或者powervesse),类型(schooner,catamaran,oryacht),使用它远行的价格

你想得到一份报告,包含了每一个港口的、sailing或者power vessel的、每一种类型的、船的数量,下面的代码用proc tabulate创建了一个三维报告:港口作为页、移动方式作为行、类型作为列:

报告分两页,港口的每个值情况为一页:

其实,上面讲了的主要内容集中在报告输出(proc tabulate,proc report,ods)以及一些可视化的东西,有利于我们之后去输出数据报表,但是,考虑到其实我们在日后可能会直接用到SAS输出的报表的机会比较少,所以这一块我也不打算花太多的时间去学习,大概了解就好了,因为数据展示还是用回熟悉的Excel来展示会更加高效,不过看吧,以后如果有用到了,再过来学习~

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









