




诸神缄默不语-个人优快云博文目录
诸神缄默不语的论文阅读笔记和分类
论文全名:Text Summarization with Pretrained Encoders
ArXiv网址:https://arxiv.org/abs/1908.08345
官方代码:nlpyang/PreSumm: code for EMNLP 2019 paper Text Summarization with Pretrained Encoders
本文是2019年EMNLP论文。
这篇我其实老早之前就读过了。整体逻辑非常简单,抽取式摘要就拿token classification的思路做BERT句子分类任务(预测每一个句子(text span)是否会出现在摘要中);生成式摘要就是Transformer,但是encoder是BERT,然后encoder和decoder分别用不同的优化器(因为encoder是预训练模型,所以要解决不匹配问题……非常早期的妥协方案了属于是,我的意见是可能没有BART好使)。二阶段微调(先抽取后生成)可以继续提升效果。简单易用。
纯抽取式摘要BertSum论文:Fine-tune BERT for Extractive Summarization
ArXiv网址:https://arxiv.org/abs/1903.10318
这篇是PreSumm的一作的工作。这篇论文跟BertSumExt差不多,我晚点应该会读读这篇文章然后写笔记添加到本博文中。
代码复现的概率目前看来增加了一点hh,感觉有一定概率需要做回抽取式摘要了……等我开工了复现一下,复现完了把代码在本文放一下。
1. 抽取式摘要BertSumExt
BERT + 句间Transformer
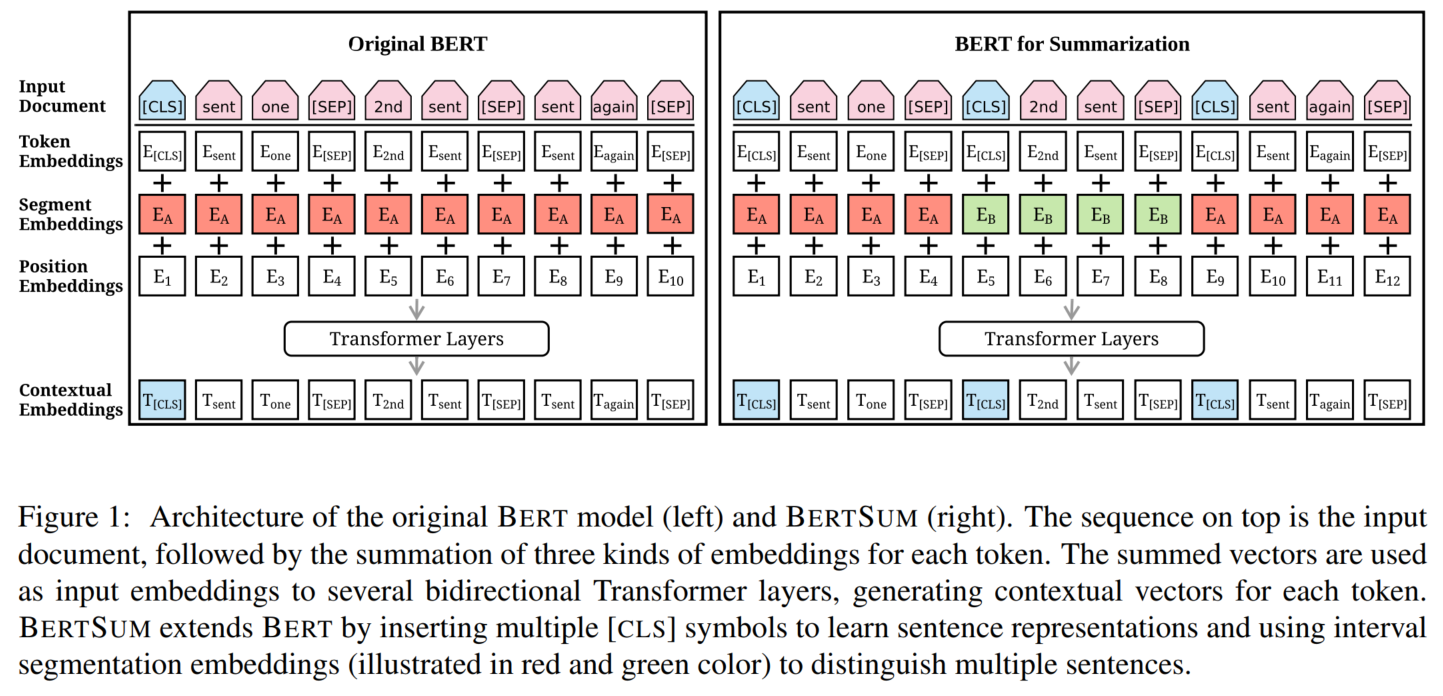
Transformer架构:
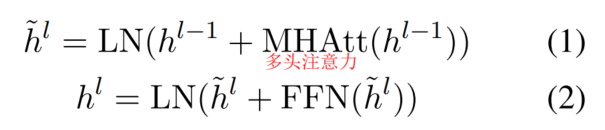
用[CLS]表示句子向量
interval segment embeddings: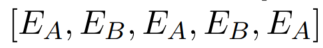
克服原始位置编码长度限制为512的问题:增加更多随机初始化、参与微调的位置编码
抽取式摘要在[CLS]后面加sigmoid分类器: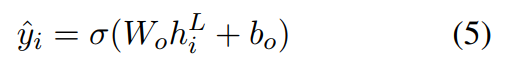
在实验中最后选择得分top-3的句子作为摘要。
2. 生成式摘要
BERT encoder(和第一节的一样) + 随机初始化的Transformer decoder
两部分用不同的优化器(梯度)。
二阶段版本:先用抽取目标后用生成目标微调两遍。
原始生成式模型:BertSumAbs
二阶段生成式模型:BertSumExtAbs
3. 实验
1. 数据集
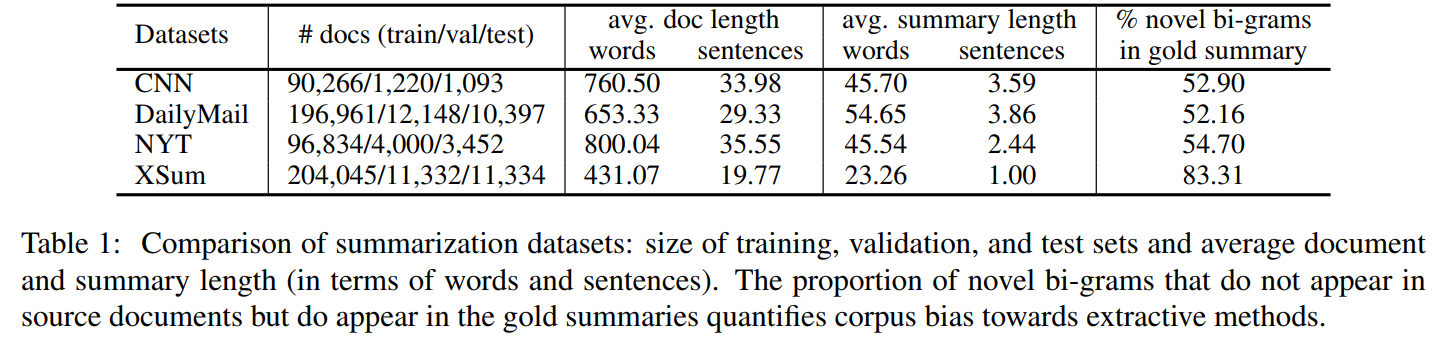
2. 实验设置
比较值得在意的内容:
用生成式摘要转抽取式摘要的代码:用的是SummaRuNNer中的方法,贪心算法,最大化ROUGE-2。这个我可能需要看下。
抽取式摘要中的Trigram Blocking1:对于已生成的部分,在选择新句子时,如果会出现trigram重复,就不用这个新句子。(思路类似于Maximal Marginal Relevance (a.k.a MMR)2)减少选择句子的相似性
生成式摘要中禁止生成重复trigrams1
3. 主实验结果 + 消融实验
自动评估指标:
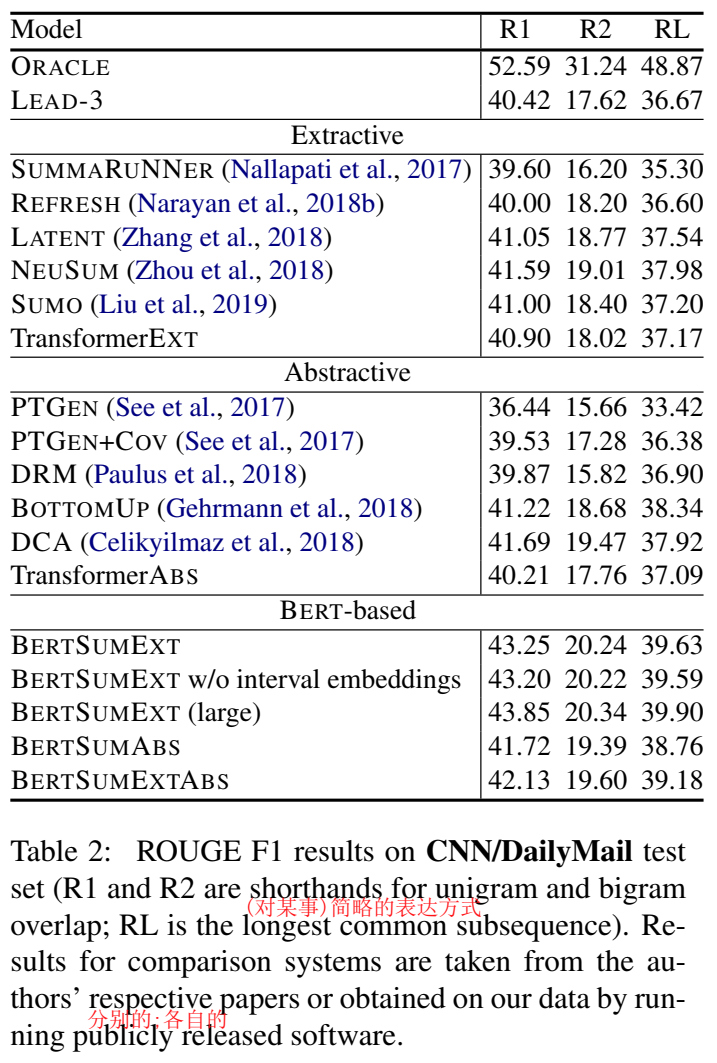
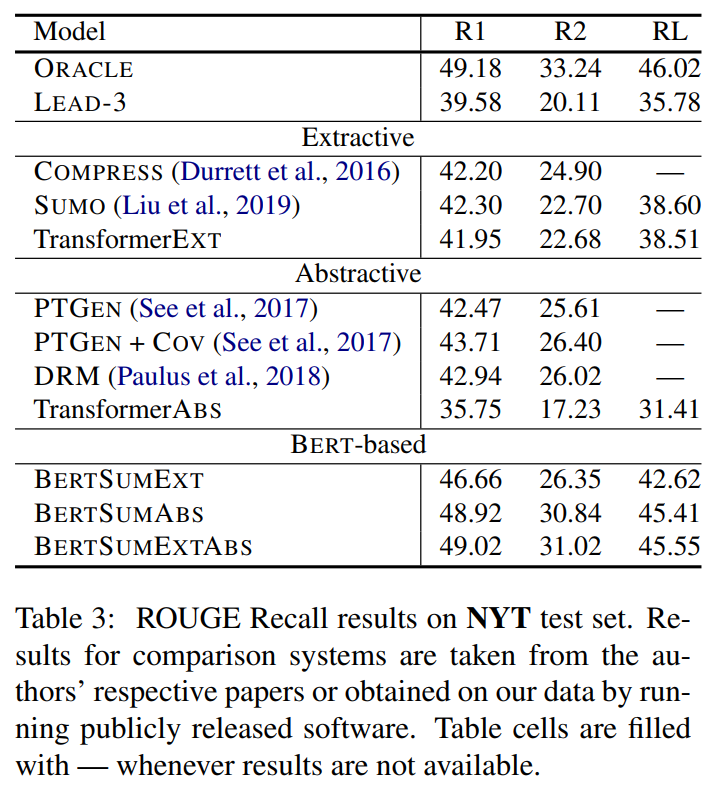
↑ limited-length ROUGE Recall:预测摘要截断到与真实摘要等长
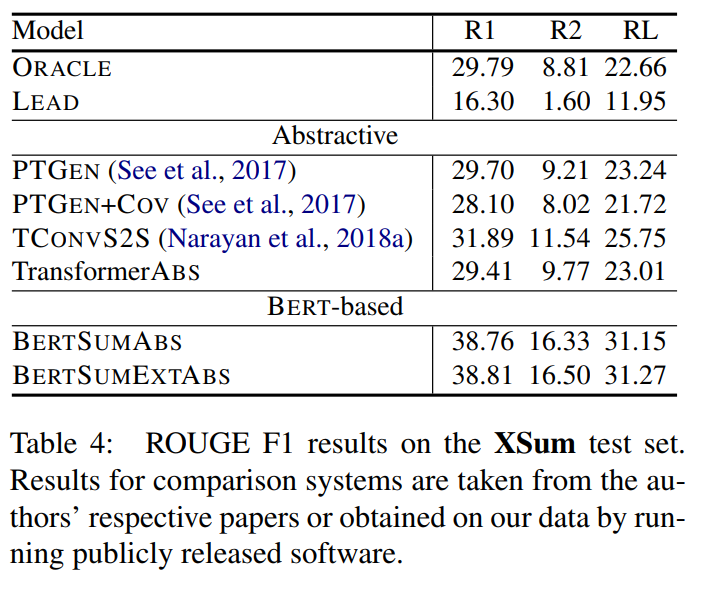
人工评估指标:
QA:不看原文,直接看摘要,回答问题
Best-Worst Scaling评估指标:Informativeness, Fluency, and Succinctness
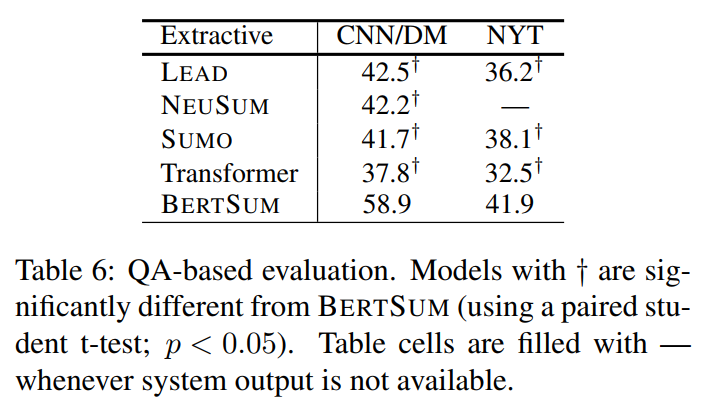
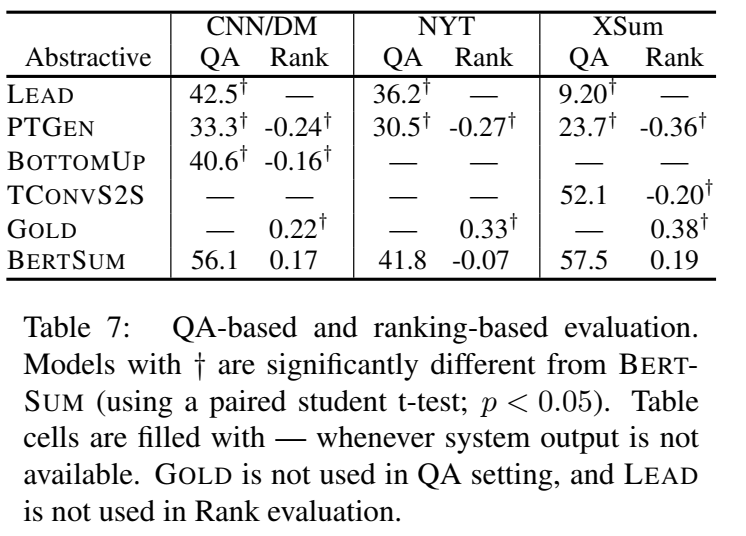
4. 模型分析
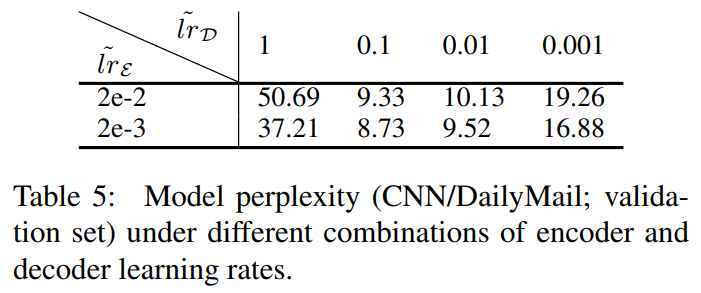
学习率超参数分析:
抽取式摘要中句子的位置分布(CNN/DailyMail数据集上):
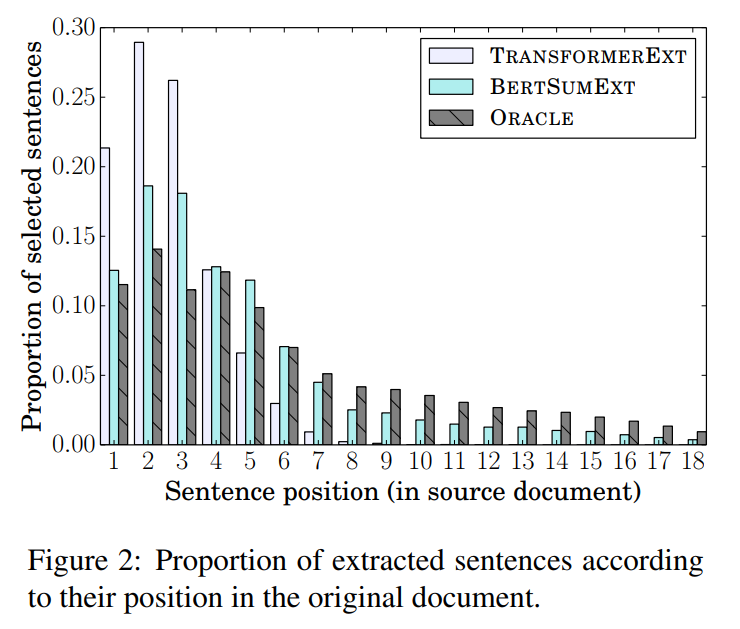
↑ 这说明有预训练encoder,模型就不仅依赖浅层位置信息,还学习深层文档表征
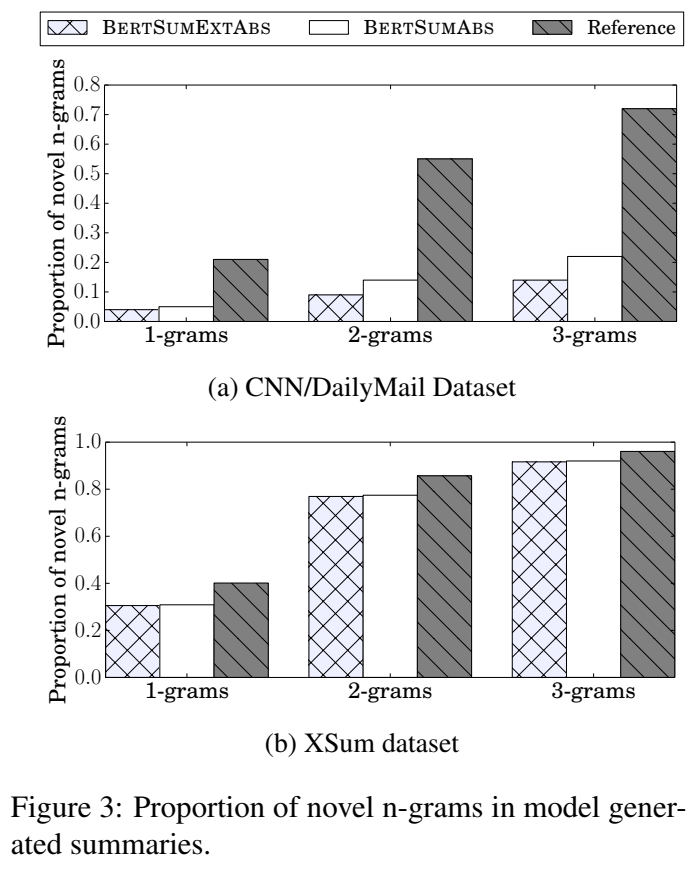
novel n-grams出现率:(模型的生成程度)
4. 其他
Q:BertSum论文里面有一句“BERT-based models outperform the LEAD-3 baseline which is not
a strawman”这个strawman是稻草人的意思?这句话到底是啥意思啊?
A:在学术论文或讨论中,“strawman”通常不是指字面上的“稻草人”,而是指一种辩论策略或论证方法。在这种上下文中,一个“strawman”论点是指故意构造的、容易反驳的对立观点,用来强化自己的立场,因为击败一个弱对手比较简单。所以,当BertSum论文中说“LEAD-3 baseline which is not a strawman”时,意思是LEAD-3基线方法并不是一个故意设置的、容易击败的弱对手。相反,它暗示LEAD-3是一个有竞争力的、值得比较的基线,而BERT基于的模型能够超越这个有力的基线,这表明了BERT模型的显著效能。简单来说,这句话强调了BERT-based模型在性能上的显著提升,并非通过击败一个弱小的对手来实现,而是通过超越了一个被认为是有实力的基线模型。


















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











