




 本文介绍了动态图GNN的关键技术,包括M2^22DNE、HPGE和DyMGNN等方法。M2^22DNE利用时间点过程来建模动态图中的边的形成;HPGE关注于动态异质图的学习;而DyMGNN则通过动态元路径引导的时间异质图模型来捕获动态语义。
本文介绍了动态图GNN的关键技术,包括M2^22DNE、HPGE和DyMGNN等方法。M2^22DNE利用时间点过程来建模动态图中的边的形成;HPGE关注于动态异质图的学习;而DyMGNN则通过动态元路径引导的时间异质图模型来捕获动态语义。
本书网址:https://link.springer.com/book/10.1007/978-3-031-16174-2
本文是本书第五章的笔记。
懒得看了!反正我也不是做这个的。以后要是真的去做动态图了也不是没资源找,这个我懒得看了,就写一半算了,目测不会更新,如果我改做动态图而且拿到全书资源了可能会更新。
1. 动态图GNN概念介绍
捕获动态图时间演变的常用方法:将整图分割为多个snapshots,分别嵌入得到snapshot-based embeddings,用LSTM / GRU等序列模型生成表征。
动态图时间演变常包含两个动态过程:
- the microscopic dynamics of edge establishments
- macroscopic dynamics of network scales
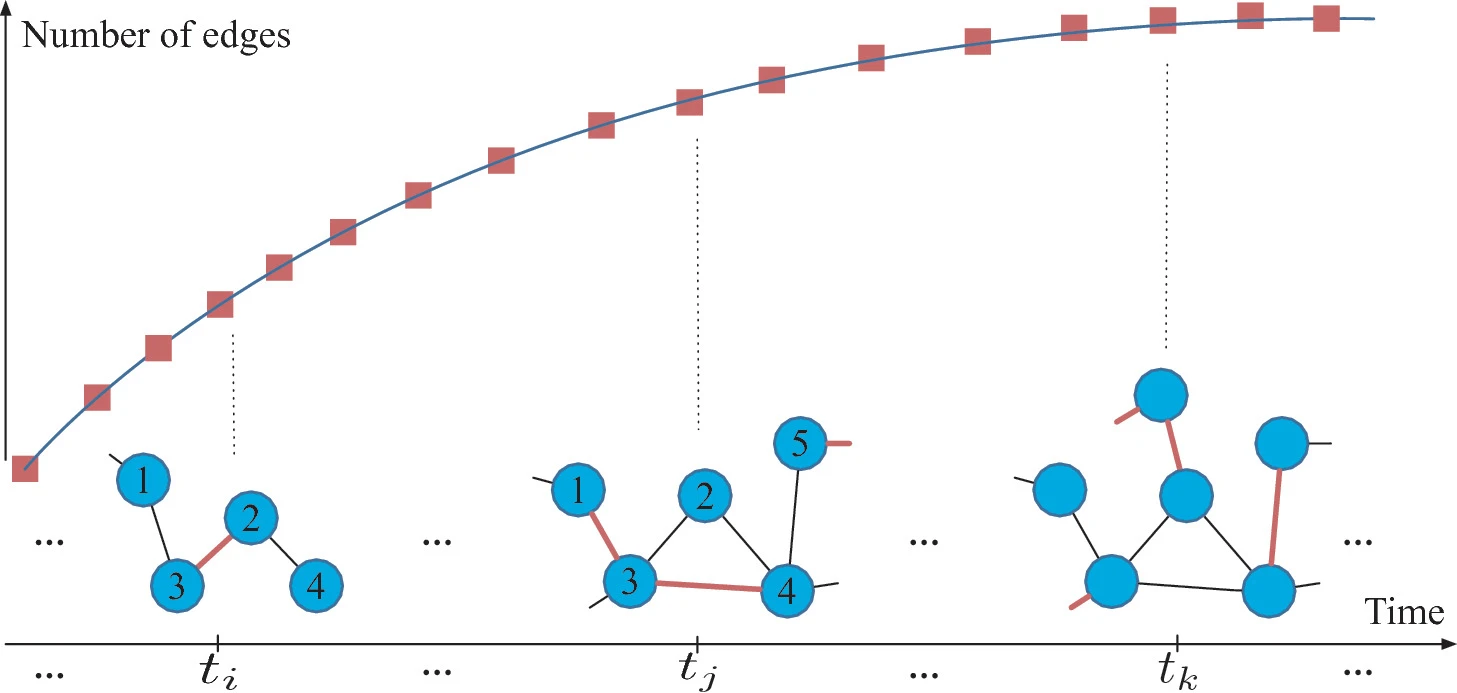
2. M 2 ^2 2DNE
基于temporal point process建模边的宏微观动态。
微观:边渐渐形成。更近的边影响更大
宏观:网络尺寸的演进遵循显著分布,如S-shaped sigmoid curve或power-law-like pattern
M
2
^2
2DNE
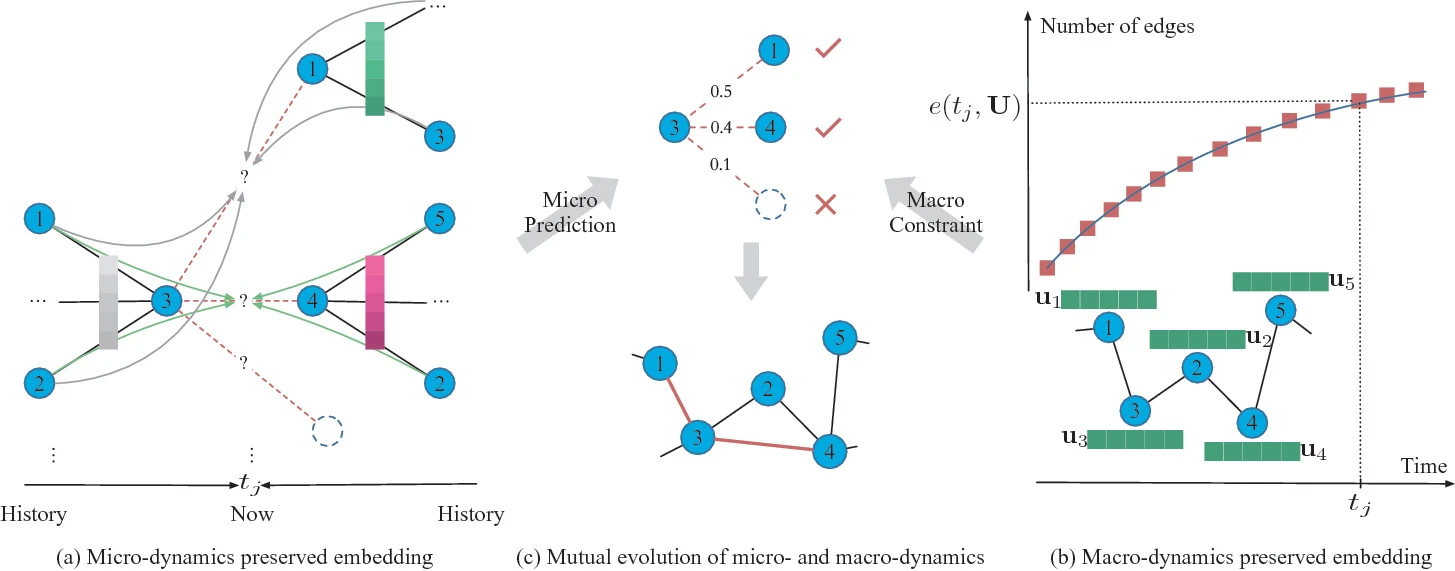
3. HPGE:动态异质图
学习所有异质动态事件的形成过程,保留语义和动态
(事件就是指某个时间点,两个节点之间多长一条边)
Heterogeneous Hawkes Process
4. DyMGNN
dynamic meta-path guided temporal heterogeneous graph modeling approach
设计dynamic meta-path and heterogeneous mutual evolution attention mechanisms,有效捕获dynamic semantics,建模mutual evolution of different semantics


















 8133
8133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











