




 该博客是Python3常用API速查手册,涵盖基础语法、对象处理、条件循环等内容。介绍了对Python 3对象排序、过滤等操作,还提及众多常用功能库,如yaml、进度条库、random库等,以及上下文管理器、装饰器等特性,同时给出常见bug的解决方法。
该博客是Python3常用API速查手册,涵盖基础语法、对象处理、条件循环等内容。介绍了对Python 3对象排序、过滤等操作,还提及众多常用功能库,如yaml、进度条库、random库等,以及上下文管理器、装饰器等特性,同时给出常见bug的解决方法。
文章目录
- 1. 运算符
- 2. Python 3 基础语法
- 3. Python 3 对象:字符串、列表、元组、集合、字典
- 3.5 特殊变量
- 4. 条件和循环
- 5. 对Python 3 对象的处理:排序、过滤、迭代、删除,查看属性
- 5.5. 函数
- 6. Python 3 内置函数
- 7. 异常处理机制
- 8. 与终端的输入输出互动
- 9. 上下文管理器
- 10. 装饰器
- 11. 常见简单bug(比较复杂的有些我会专门写一篇博文)
- 12. jupyter notebook
- 13. colab教程
- 14. 其他常用功能库
- 1. yaml
- 2. 进度条
- 3. random库:生成伪随机数
- 4. copy库:复制对象
- 5. math库
- 6. statistics库:数学统计函数
- 7. SymPy库:科学计算
- 8. warnings库:生成和处理警告
- 9. 发邮件
- 10. 压缩与解压缩文件:zipfile库
- 12. shutil库:高阶文件操作
- 12. cn2an库:在汉字与阿拉伯数字之间进行转换
- 13. webssh
- 14. pipx:包管理工具(可以在隔离环境下安装包)
- 15. chardet:检测bytes或bytearray的编码方式
- 16. 检测字符串的语种
- 17. 从文本中抽取URL(超文本链接/网址)
- 18. urllib
- 19. [secrets --- 生成管理密码的安全随机数 — Python 3.11.3 文档](https://docs.python.org/zh-cn/3/library/secrets.html)
- 20. 背景任务调度
- 21. base64
- 22. html库
- 23. ftfy库:修复字符编码bug
- 24. JioNLP包
- 25. difflib:比较序列
- 26. signal包
- 27. sys包:系统相关的变量和函数
- 28. importlib包:动态导入模块、函数
- 29. appdirs:应用路径管理
- 15. 实现其他小功能
- 16. 本文撰写过程中参考的其他资料
1. 运算符
+-*//就表示 浮点数除法,返回浮点结果;//表示整数除法。- 取余
%指数** - 等式:
===><>=<= is判断两个对象是否是同一个对象。==判断两个对象的值是否相等。
关于is和==的区别,可以参考我撰写的另一篇博文:Python 3中想确定一个变量是不是空值,应该用is None而非==None- 不等于:
!=或<>或not - 交并:
and&VS.or| - 所有的二元数学操作符(+、-、*、/、//、%、**)都有与之对应的增强赋值操作符(+=、-=、*=、/=、//=、%=、**=)
- Python 3.8+的海象运算符(“Walrus” operator
:=)1
功能差不多可以理解成一句话赋值并返回值,可以减少重复的函数调用场景,减少代码用时。示例:
其他细节:In [9]: numbers = [2, 8, 0, 1, 1, 9, 7, 7] In [10]: description = { ...: "length": (num_length := len(numbers)), ...: "sum": (num_sum := sum(numbers)), ...: "mean": num_sum / num_length, ...: } In [11]: description Out[11]: {'length': 8, 'sum': 35, 'mean': 4.375}>>> a = "wtf_walrus" >>> a 'wtf_walrus' >>> a := "wtf_walrus" File "<stdin>", line 1 a := "wtf_walrus" ^ SyntaxError: invalid syntax >>> (a := "wtf_walrus") # This works though 'wtf_walrus' >>> a 'wtf_walrus' >>> a = 6, 9 >>> a (6, 9) >>> (a := 6, 9) # ((a := 6), 9) (6, 9) >>> a 6 >>> a, b = 6, 9 # Typical unpacking >>> a, b (6, 9) >>> (a, b = 16, 19) # Oops File "<stdin>", line 1 (a, b = 16, 19) ^ SyntaxError: invalid syntax >>> (a, b := 16, 19) # (a, (b := 16), 19) (6, 16, 19) >>> a # 6 >>> b 16 >>> (a := 6, 9) == ((a := 6), 9) True >>> x = (a := 696, 9) >>> x (696, 9) >>> x[0] is a # Both reference same memory location True
2. Python 3 基础语法
- 在Python中,可以同时给多个变量赋值:<变量1>, …, <变量N> = <表达式1>, …, <表达式N>
- 长语句跨行可在第一行末尾加入
\\ - 判断是否是None:
is not None!=None - 匿名函数:
<函数名> = lambda <参数列表>: <表达式> pass:在需要缩进的部分不写代码(一般都是测试时候不需要跑了),就写个pass顶一下位置。啥也不干- 注释以
#开头 assert:断言
用于判断一个表达式,在表达式条件为 false 的时候触发异常。global- 3.10的新功能:
match ... case
看起来就跟Java里面的switch ... case差不多。我说真的这些编程语言是越来越像了啊
3. Python 3 对象:字符串、列表、元组、集合、字典
- 字符串、列表、元组相关内容请参考我写的这篇博文:Python3序列类型(字符串、列表、元组)
- 集合
set():初始化集合对象add(obj):增加单个元素update(series):将整个序列的所有元素一一增加进集合set.intersection(set1, set2 ... etc):返回入参集合的交集- {}会创造一个空字典
universitySet = set(['西南财大', '电子科技大学', '四川大学', '西南交通大学'])
universitySet = {'西南财大', '电子科技大学', '四川大学', '西南交通大学'} - 集合是无序组合,它没有索引和位置的概念,不能分片。
| 操作符 | 描述 |
|---|---|
| S – T 或 S.difference(T) | 返回一个新集合,包括在集合S中但不在集合T中的元素 |
| S-=T或S.difference_update(T) | 更新集合S,包括在集合S中但不在集合T中的元素 |
| S & T或S.intersection(T) | 返回一个新集合,包括同时在集合S和T中的元素 |
| S&=T或S.intersection_update(T) | 更新集合S,包括同时在集合S和T中的元素。 |
| S^T或s.symmetric_difference(T) | 对称差集:返回一个新集合,包括集合S和T中元素,但不包括同时在其中的元素 |
| S=^T或s.symmetric_difference_update(T) | 更新集合S,包括集合S和T中元素,但不包括同时在其中的元素 |
| S|T或S.union(T) | 返回一个新集合,包括集合S和T中所有元素 |
| S=|T或S.update(T) | 更新集合S,包括集合S和T中所有元素 |
| S<=T或S.issubset(T) | 如果S与T相同或S是T的子集,返回True,否则返回False,可以用S<T判断S是否是T的真子集 |
| S>=T或S.issuperset(T) | 如果S与T相同或S是T的超集,返回True,否则返回False,可以用S>T判断S是否是T的真超集 |
| 函数或方法 | 描述 |
|---|---|
| S.add(x) | 如果数据项x不在集合S中,将x增加到s |
| S.clear() | 移除S中所有数据项 |
| S.copy() | 返回集合S的一个拷贝 |
| S.pop() | 随机返回集合S中的一个元素,如果S为空,产生KeyError异常 |
| S.discard(x) | 如果x在集合S中,移除该元素;如果x不在,不报错 |
| S.remove(x) | 如果x在集合S中,移除该元素;不在产生KeyError异常 |
| S.isdisjoint(T) | 如果集合S与T没有相同元素,返回True |
| len(S) | 返回集合S元素个数 |
| x in S | 如果x是S的元素,返回True,否则返回False |
| x not in S | 如果x不是S的元素,返回True,否则返回False |
-
字典
- 字典的键需要是不变的变量(可以是字符串,数字,元组)
键是唯一的,但需要注意的是,键的唯一性是通过值来确定而不是通过对象来确定(集合也是这样的)(因为Python 3中equal的对象具有相同的哈希值,但是反过来不一定,因为可能出现哈希碰撞现象),示例:
如果直接用some_dict = {} some_dict[5.5] = "JavaScript" some_dict[5.0] = "Ruby" some_dict[5] = "Python" >>> some_dict[5.5] "JavaScript" >>> some_dict[5.0] "Python" >>> some_dict[5] "Python" >>> complex_five = 5 + 0j >>> type(complex_five) complex >>> some_dict[complex_five] "Python"dict[key]命令时不存在key这个键,会报KeyError错误。为了防止这个问题可以使用dict.get(key,default_value)这种写法 - 键:
keys()
值:values()
键值对(tuple格式):items()
返回的是一个可迭代的对象,是一个视图对象,是只读的 - 增加一个键值对:直接使
dict_object[k]=v update(dict_object):将入参字典的键值对更新到原对象中
(如果键再原对象中就存在,将更新值;如果不存在,将键值对加入原对象)- 字典生成式,示例:
{i:str(i) for i in range(10)} {<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}- 键可以是Python中任意的不可变类型:布尔型、整型、浮点型、元组、字符串,以及其他一些不可变的类型。字典本身是可变的,因此可以增加、删除或修改其中的键值对。字典的键必须保证互不相同。
- 字典是集合类型的延续,各个元素并没有顺序之分。
<值> = <字典变量>[<键>]- 添加键值对:直接添加
del employee['性别']
函数和方法 描述 <d>.keys()返回所有的键信息 <d>.values()返回所有的值信息 <d>.items()返回所有的键值对 <d>.get(<key>,<default>)键存在则返回相应值,否则返回默认值 <d>.pop(<key>,<default>)键存在则返回相应值,同时删除键值对,否则返回默认值 <d>.popitem()随机从字典中取出一个键值对,以元组(key, value)形式返回 <d>.clear()删除所有的键值对 del <d>[<key>]删除字典中某一个键值对 键/值/元组 in <d>setdault(key[, default=None])字典中查找指定键,存在则返回值,不存在则插入键值对并返回默认值 <d1>.update(<d2>)pprint()或pformat()<d>.setdefault(key,get_value(key))获取值,如果不存在,计算并存储 - 字典的键需要是不变的变量(可以是字符串,数字,元组)
参考资料:字典及其内置函数
3.5 特殊变量
__file__:该脚本的绝对路径
这个变量比较复杂,总之建议仅用于脚本2。我常用于调包的时候把路径引为母文件夹的母文件夹,就这么写:sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
4. 条件和循环
- if判断语句
if condition_1: statement_block_1 elif condition_2: statement_block_2 else: statement_block_3 - while
break:结束循环continue:跳过本轮循环,直接进入下一轮循环
while 判断条件(condition): 执行语句(statements)……while <expr>: <statement(s)> else: <additional_statement(s)> - for循环语句:匿名变量可以用
_指代for <variable> in <sequence>: <statements> else: <statements>
5. 对Python 3 对象的处理:排序、过滤、迭代、删除,查看属性
属性直接用obj.name这种形式就能获取。
- 排序
sorted():返回对象元素排序后的结果sort():对对象进行排序,返回None- 参数
- key:如果是字典的话就直接是字典的键名,表示用指定键的值来排序;如果是一个函数的话就表示用元素输入函数后的返回值来处理,可以用匿名函数(lambda函数),如用元素长度来排序就可以写成
key=lambda x: len(x) - reverse:一个布尔值,表示是否要逆序排序元素,默认为False
- key:如果是字典的话就直接是字典的键名,表示用指定键的值来排序;如果是一个函数的话就表示用元素输入函数后的返回值来处理,可以用匿名函数(lambda函数),如用元素长度来排序就可以写成
filter(function,iterable)3:过滤- 示例:
list(filter(None,[None,'1111111','2222222'])):将列表中的空对象删掉,返回['1111111', '2222222']
- 示例:
- 同时迭代多个迭代器,按顺序同时输出多个迭代器里的元素:用
zip()4
举例:L1=['a','b','c','d','e','f','g','h'] L2=['A','B','C','D','E','F','G','H'] for (l1,l2) in zip(L1,L2): print(l1+' '+l2) len(object):返回对象的长度- 对象的所有属性:
object.__dict__(返回一个字典) - 检查对象是否具有某一属性:
object.hasattr(attr_name)
或者直接用内置函数:hasattr(obj: object, name: str) - 将对象的某一属性设置为某值:
setattr(obj, name, value) id():返回对象的储存空间
可能需要注意的是id()指向类时用完就会回收类:class WTF(object): def __init__(self): print("I") def __del__(self): print("D") >>> WTF() is WTF() I I D D False >>> id(WTF()) == id(WTF()) I D I D Trueall(iterable_object):判断所有元素是否都为 TRUE,如果是返回 True,否则返回 False。5any()del
5.5. 函数
1. 函数入参
位置参数,关键字参数,指定默认参数值
使用*收集位置参数,使用**收集关键字参数(星号本身不是参数)6
列表、元组前面加星号(*)作用是将列表解开成两个独立的参数,传入函数,字典前面加两个星号(**),是将字典解开成独立的元素作为形参
举例:
def add(a, b):
return a+b
data = [4,3]
print (add(*data)) #输出7
data = {'a' : 4, 'b' : 3}
print (add(**data)) #输出7
print (add(*data)) #输出'ab'
习惯上,如果你希望函数接受可变的关键字参数,使用**kwargs。如果你希望接受可变的位置参数,使用*args。
2. 魔术方法magic method
指用__包裹起来的方法
1. if __name__=='__main__:
这个判断条件大致可以理解为,如果这个代码文件是直接被运行的,就是True;如果是被调用的,就是False
这个判断条件我一般用在单元测试某个功能的时候,就在这个判断条件里面写单元测试代码,但在整个代码文件被调用的时候,这段测试代码不会被执行。
2. __init__
这是类的函数。在类被实例化的时候会调用__init__()函数。可以从这里传入参数。
3. object的函数
super()
示例:self.super().__init__(参数)这样调用就可以在实例化子类的时候默认调用父类的__init__()函数中的功能了。
6. Python 3 内置函数
round(浮点数,保留小数点后的位数):返回数字舍入后的结果eval(str):执行字符串格式的表达式,并返回表达式结果exec(str):执行代码,返回Nonerange(obj:int):返回以0为第一个元素、以obj-1为最后一个元素的迭代器
range(start,end,step)
参数:开始值,末值,步长
需要注意的是,range()是用来生成整数迭代器的,所以不支持小数数组。如果需要用小数的生成式的话建议用np.arange()或者手写迭代器。enumerate(sequence,[start=0]):返回enumerate(枚举)对象,每个元素是一个元组(第一个元素是索引,第二个元素是sequence中对应的元素)7iter(object):返回迭代器next(iterator):返回迭代器的下一个对象map(function,iterable,...):对指定序列做映射,将结果返回
代码:list(map(lambda x: x ** 2, [1, 2, 3, 4, 5]))
输出:[1, 4, 9, 16, 25]
ord():以一个字符串(Unicode 字符)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值。8chr():用一个整数作参数,返回一个对应的字符。9- 直接转换对象类型:如
- 数字类型转换函数:
float(x)int(x)str(x) list(x)str(x)
- 数字类型转换函数:
- 退出程序运行(仅在脚本运行时起效,在Jupyter Notebook中无效):
exit() - 输出对象类型:
type(obj) isinstance(obj,class):如果obj属于class,返回True(示例代码:isinstance(name, str)hasattr(class_obj, method_name):某个对象中是否含有指定方法/属性method = getattr(class_obj, method_name):返回这个方法/属性(如果是方法的话,就返回一个Callable对象)globals():返回当前模块的全局符号表(一个字典)
7. 异常处理机制
- 捕获:try-except语句
现在独立成篇了:Python 3中的异常捕获机制(try-except语句) - 抛出异常:
raise Exception(message:str)Exception可以替换成其他Exception子类 - Exception子类:
- ValueException
- AttributeError
- IndexError
- NameError
- TypeError
8. 与终端的输入输出互动
1. 打印/输出
print(打印内容)
会自动在末尾添加换行符
如果打印后不想换行,可以使用参数end
- 打印颜色:
"\033[31m本段文字将会显示成红色\033[0m\n"
更多使用方法可参考此篇博文:Python基础之控制台输出颜色_zxnode的博客-优快云博客
打印颜色还可以用termcolor(使用termcolor包美化Python命令行输出)
想要更好看的打印格式还可以用pprint(pprint包的使用介绍)
2. 输入
input():函数等待用户在键盘上输入一些文本,并按下回车键。这个函数的值为一个字符串,即用户输入的文本。输入参数为显示标识getpass.getpass(prompt='Password: ', stream=None):输入密码
文档:https://docs.python.org/3/library/getpass.html
9. 上下文管理器
with+上下文管理器:在使用的过程中,可以简单地认为with语句自动设置一种状态的环境,不需要显式控制开始和结束。如with open('file.txt') as f:语句下包裹的代码运行之间自动打开文件流,运行后自动关闭;with torch.no_grad():语句下包裹的代码自动停止梯度计算。更多细节可参考10
contextlib包:提供了一些用于创建和管理上下文的实用工具函数和装饰器。它主要用于简化上下文管理器的创建过程
官方文档:contextlib — Utilities for with-statement contexts — Python 3.11.5 documentation
- 创建上下文管理器:
from contextlib import contextmanager @contextmanager def my_context(): # 进入上下文前的操作 setup() try: yield # 返回上下文对象 finally: # 离开上下文后的操作 teardown() with my_context() as ctx: # 在上下文中执行的代码 do_something() - 将没有实现上下文管理器接口的对象转换为上下文管理器:
from contextlib import closing from urllib.request import urlopen with closing(urlopen('http://www.example.com')) as page: for line in page: print(line)
10. 装饰器
我另外还写了个博文,等有空了再合并到一个更具有系统性的教程中:深入浅出Python 3装饰器:从入门到精通
装饰函数,语法糖。
是一个能应用在各种函数上的统一小功能,比如计算时间、让pytorch张量停止累积梯度(@torch.no_grad())等。
示例,实现一个在函数报错时自动弹出报错信息traceback的窗口的功能:
def error_popup(func):
"""在函数报错时自动弹出错误信息的装饰器"""
@wraps(func)
def wrapper(*args, **kwargs):
try:
return func(*args, **kwargs)
except Exception as e:
error_msg = traceback.format_exc()
show_message_box(
title="程序出错",
message=f"函数 {func.__name__} 发生错误:\n\n{error_msg}",
)
raise e
return wrapper
在需要用到这个功能的函数前面加一行@error_popup就可以。
简单实现可参考python3-装饰器_花_城的博客-优快云博客_python3 装饰器
11. 常见简单bug(比较复杂的有些我会专门写一篇博文)
- Python运行报SyntaxError: Non-UTF-8 code starting with ‘\xe5‘ in file的解决方法_syntaxerror: non-utf-8 code starting with ‘\xe5’ i_秋9的博客-优快云博客:在Python文件开头加
# coding:utf-8 - " " 和 " " 两个看起来都像空格,但实际上它们是不同的字符。
" " 是ASCII字符集中的空格,也被称为普通空格或半角空格。它的Unicode编码是U+0020。
" " 是CJK字符集中的空格,也被称为全角空格。它的Unicode编码是U+3000。全角空格的宽度是普通空格的两倍,通常用在需要对齐的文字中,特别是在中文、日文和韩文中。
在Python中,你可以使用ord函数来获取这两个字符的Unicode编码,以此来区分它们。例如:
在处理文本数据时,通常需要注意这两种空格可能带来的影响。print(ord(" ")) # Output: 32 print(ord(" ")) # Output: 12288 SyntaxError: Non-UTF-8 code starting with '\xe5' in file
解决方案:在Python文件首行添加#coding=utf-811
12. jupyter notebook
The Jupyter Notebook — Jupyter Notebook 6.5.4 documentation
- jupyter notebook打开出现
Unreadable Notebook: coda_path\btc-master (16.2)\btc_close_2017.ipynb NotJSONError('Notebook does not appear to be JSON: \'\\ufeff{\\n "cells": [\\n {\\n "cell_typ...')问题,解决方法:用json格式化工具将ipynb文件进行格式化(如https://www.sojson.com/格式化后即可) - 如何设置Jupyter Notebook可远程访问:
设置 jupyter notebook 可远程访问 - Liu-Cheng Xu - 优快云博客
远程访问jupyter notebook - Echo/ - 博客园
服务器(CentOS7)配置Jupyter Notebook远程访问 - 水水 - 优快云博客
如何访问服务器的 Jupyter notebook - 知乎
云服务centos搭建jupyter notebook并通过外网访问_开发工具_taw19960426的博客-优快云博客 - IPython.display
- 清除输出12:
输出效果:from IPython.display import clear_output print('before') clear_output() # 清除输出 print('after')after- 输出Markdown或LaTeX格式:
from IPython.display import display, Markdown, Latex display(Markdown('**some markdown** $\phi$')) display(Latex(r'$\phi$'))
需要注意的是,如果在VSCode内置jupyter notebook,需要设置展示格式为text/markdown,否则就会显示纯文本:
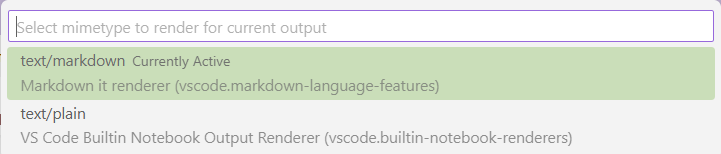 13
13
- magic function
打印行运行时长:%time
打印cell运行时长:%%time
打印函数运行时长:%timeit(用法:%timeit function())14
13. colab教程
教程:Google Colab免费GPU使用教程(一)
colab里面更换GPU/CPU会导致会话重启
https://colab.research.google.com/notebooks/welcome.ipynb
https://colab.research.google.com/notebooks/打开文件
建议观看这篇教程:Google Colab features you may have missed - YouTube
以获得如下知识:① interactive table:colab的插件,可以实现与colab中打开的DataFrame动态交互。感觉比VSCode的好使,可以排序(VSCode也可以)、过滤 ② execution history:版本管理,而且可以在侧边窗中测试修改cell的结果而不用污染notebook ③ command palette:命令菜单
14. 其他常用功能库
1. yaml
现在专门写成一个独立博文了:Python yaml格式配置文件教程
2. 进度条
1. tqdm
(官方GitHub项目:tqdm/tqdm: A Fast, Extensible Progress Bar for Python and CLI)
使用pip安装:pip install tqdm
简单用法:用from tqdm import tqdm引入(Jupyter Notebook中可以用from tqdm.noteboook import tqdm),然后在for语句中加到迭代器上,如for i in tqdm(range(10)),然后在运行循环语句的过程中就会出现进度条:

(总之意思就是tqdm(iterator)是一个迭代过程中会自动出现进度条的新迭代器)
常用入参:
desc:字符串入参+:会出现在进度条前,示例:
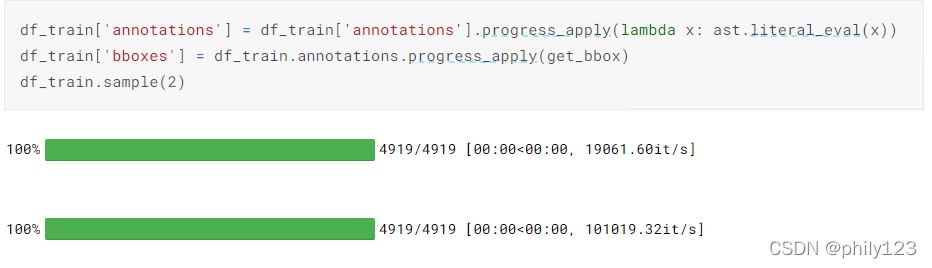
tqdm.pandas()
tqdm与pandas包结合:先执行tqdm.pandas(),然后就可以将pandas的apply()函数直接换成progress_apply()函数并展示进度条了。
trange
相当于对tqdm(range())的简化:
from tqdm import trange
for i in trange(100):
#do something
pass
2. alive-progress
主要是有一台服务器我tqdm不知为啥显示不了进度条,所以我就改用alive-progress了
alive-progress · PyPI
GitHub - rsalmei/alive-progress: A new kind of Progress Bar, with real-time throughput, ETA, and very cool animations!
使用pip安装:pip install alive-progress
- 知道迭代数的情况:
from alive_progress import alive_bar with alive_bar(总迭代数) as bar: for sample in 迭代器: 操作 bar()
3. fastprogress
from fastprogress.fastprogress import master_bar, progress_bar
from time import sleep
mb = master_bar(range(10))
for i in mb:
for j in progress_bar(range(100), parent=mb):
sleep(0.01)
mb.child.comment = f'second bar stat'
mb.first_bar.comment = f'first bar stat'
mb.write(f'Finished loop {i}.')

3. random库:生成伪随机数
random — Generate pseudo-random numbers — Python 3.11.3 documentation
- 设置随机数种子:
random.seed(a) - 生成分布的一个样本(数字)
random.random():生成[0.0, 1.0) 范围内的下一个随机浮点数random.uniform(a, b):生成二数之间的一个随机数。终点 b 可以包括或不包括在该范围内。gauss(mu=0.0, sigma=1.0):高斯分布/正态分布(Python 3.11之后两个属性才有默认值,在此之前都要)random.randrange(stop)
random.randrange(start, stop[, step])
从range(start, stop, step)中随机抽取一个元素,与choice(range(start, stop, step))等价,但并不真的创造一个range对象
- 原地打乱序列顺序:
random.shuffle(x)
4. copy库:复制对象
copy库官方文档:copy — 浅层 (shallow) 和深层 (deep) 复制操作 — Python 3.11.0 文档
copy.deepcopy(obj):返回对象深度复制后的对象,二者的操作互不影响
5. math库
- 开方:
math.sqrt(数字) - 检测数字是否是nan:
math.isnan(数字)
6. statistics库:数学统计函数
statistics库官方文档:statistics — Mathematical statistics functions — Python 3.11.1 documentation
- 求平均值:
statistics.mean(obj)
7. SymPy库:科学计算
官方文档:SymPy 1.11 documentation
参考博文:Python科学计算利器——SymPy库 - 简书
8. warnings库:生成和处理警告
warnings库官方文档:warnings — Warning control — Python 3.11.2 documentation
1. warnings.filterwarnings('ignore')15:直接忽略警告
2. warnings.warn(警告信息):生成警告
9. 发邮件
首先搞个SMTP服务的邮箱账号来发邮件。以网易邮箱为例,开启POP3/SMTP/IMAP服务:

示例代码:
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
my_sender='xxxxx@yeah.net' # 发件人邮箱账号
my_pass = 'xxxxx' # 发件人邮箱密码(当时申请smtp给的口令)
my_user='xxxxx@xx.com' # 收件人邮箱账号
def mail():
ret=True
msg=MIMEText('填写邮件内容','plain','utf-8')
msg['From']=formataddr(["发件人昵称",my_sender]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号
msg['To']=formataddr(["收件人昵称",my_user]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号
msg['Subject']="邮件主题-测试" # 邮件的主题,也可以说是标题
server=smtplib.SMTP_SSL("smtp.yeah.net",587)
server.login(my_sender, my_pass) # 括号中对应的是发件人邮箱账号、邮箱密码
server.sendmail(my_sender,[my_user,],msg.as_string()) # 括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件
server.quit()# 关闭连接
return ret
ret=mail()
10. 压缩与解压缩文件:zipfile库
zipfile — 使用ZIP存档 — Python 3.11.3 文档
- 创建ZipFile对象:
zFile=zipfile.ZipFile(zip_file_path,"r") - 提取ZipFile下的所有文件(返回值是文件名),并解压到对应文件夹中:

- 关闭ZipFile对象:
zFile.close()
12. shutil库:高阶文件操作
shutil — 高阶文件操作 — Python 3.11.3 文档
1. shutil.rmtree(path):删除文件夹及其下的所有内容
常用的另一个操作文件的库os可以参考我写的博文:os:与操作系统有关的Python操作
12. cn2an库:在汉字与阿拉伯数字之间进行转换
cn2an官方GitHub项目:Ailln/cn2an: 📦 快速转化「中文数字」和「阿拉伯数字」~ (最新特性:分数,日期、温度等转化)
- 将汉字转换为阿拉伯数字:
cn2an.cn2an('3.2万','smart')输出:32000- 第二个入参
'smart':可以接受中英文与阿拉伯数字混合的形式,但是不接受,和空格等符号
- 第二个入参
13. webssh
14. pipx:包管理工具(可以在隔离环境下安装包)
pypa/pipx: Install and Run Python Applications in Isolated Environments
pipx · PyPI
Linux平台的安装方式:
python3 -m pip install --user pipx
python3 -m pipx ensurepath
15. chardet:检测bytes或bytearray的编码方式
chardet · PyPI
chardet — chardet 5.0.0 documentation
import chardet
print(chardet.detect(rawdata))
如果rawdata是str格式的话,可能需要写成rawdata.encode()16(这个似乎是Python版本的问题,我用Python 3.6.8时就需要使用这个)
16. 检测字符串的语种
pycld2
基于谷歌CLD2工具(https://github.com/CLD2Owners/cld2)实现的pycld2(https://github.com/aboSamoor/pycld2)
pip install pycld2
import pycld2 as cld2
from pprint import pprint
isReliable, textBytesFound, details = cld2.detect(
"а неправильный формат идентификатора дн назад"
)
print(isReliable)
print(textBytesFound)
pprint(details)
输出:
True
87
(('RUSSIAN', 'ru', 98, 404.0),
('Unknown', 'un', 0, 0.0),
('Unknown', 'un', 0, 0.0))
另外有另一个基于CLD2实现的cld2-cffi(https://github.com/GregBowyer/cld2-cffi),但是安装不了啊。
langdetect库:检测字符串的语言
17. 从文本中抽取URL(超文本链接/网址)
- urlextract包
pypi网址:urlextract · PyPI
官方文档:Welcome to urlextract’s documentation! — urlextract 1.8.0 documentation
安装方法:pip install urlextract
用法:
结果是一个这样的列表:from urlextract import URLExtract extractor=URLExtract() urls=extractor.find_urls("Text with URLs. Let's have URL janlipovsky.cz as an example.")['janlipovsky.cz']
这个包的问题在于似乎对中文的处理很糟糕,所以事实上还是建议用下面这个正则表达式: - 使用(ChatGPT帮我写的)正则表达式:
得到一个字符串列表,第一个元素就是网址import re url_pattern=re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+') official_sites=re.findall(url_pattern,'ASPLOS会议的官网是https://www.asplos-conference.org/,2023年论文提交截止时间是2022年10月20日。')https://www.asplos-conference.org/
18. urllib
从网址中提取域名
from urllib.parse import urlparse
urlparse(an_url_string).netloc
将可读字符串转换为URL
from urllib.parse import quote
decoded_url = "https://github.com/dongrixinyu/JioNLP/wiki/NER-说明文档#user-content-货币金额实体抽取"
encoded_url = quote(decoded_url, safe=':/#-')
print(encoded_url)
safe 参数指定了不应该被编码的字符集。在这种情况下,我们选择保留URL中常见的一些安全字符,如冒号、斜杠、井号和连字符。
输出:https://github.com/dongrixinyu/JioNLP/wiki/NER-%E8%AF%B4%E6%98%8E%E6%96%87%E6%A1%A3#user-content-%E8%B4%A7%E5%B8%81%E9%87%91%E9%A2%9D%E5%AE%9E%E4%BD%93%E6%8A%BD%E5%8F%96
将URL转换为可读字符串
from urllib.parse import unquote
url = "https://github.com/dongrixinyu/JioNLP/wiki/NER-%E8%AF%B4%E6%98%8E%E6%96%87%E6%A1%A3#user-content-%E8%B4%A7%E5%B8%81%E9%87%91%E9%A2%9D%E5%AE%9E%E4%BD%93%E6%8A%BD%E5%8F%96"
decoded_url = unquote(url)
print(decoded_url)
输出:https://github.com/dongrixinyu/JioNLP/wiki/NER-说明文档#user-content-货币金额实体抽取
19. secrets — 生成管理密码的安全随机数 — Python 3.11.3 文档
secrets.token_hex([nbytes=None]):返回十六进制随机文本字符串。字符串有 nbytes 个随机字节,每个字节转换为两个十六进制数码。未提供 nbytes 或为 None 时,则使用合理的默认值。
>>> token_hex(16)
'f9bf78b9a18ce6d46a0cd2b0b86df9da'
20. 背景任务调度
- schedule包:轻量级的定时任务库
适用场景:有个代码我想要每天早上9点时候运行一遍
schedule包官方文档:schedule — schedule 1.2.0 documentation
安装方式:pip install schedule
示例代码:import schedule import time def job(): # 这里是你的任务代码 print("Task is running...") schedule.every().day.at("09:00").do(job) while True: schedule.run_pending() time.sleep(1) - APScheduler包
APScheduler包官方文档:Advanced Python Scheduler — APScheduler 3.9.1 documentation
示例代码:from apscheduler.schedulers.background import BackgroundScheduler def task(): # 这里是你要定时执行的任务 print("Task is running...") app = Flask(__name__) if __name__ == "__main__": scheduler = BackgroundScheduler() scheduler.add_job(func=task, trigger="cron", hour=9) scheduler.start()cron触发器,可以让我们按照Cron风格的时间表达式来定时任务
scheduler.start()启动调度器 - Celery - Distributed Task Queue — Celery 5.3.0 documentation
- RQ: Simple job queues for Python
21. base64
将任一文件流编码为base64编码的字符串的示例代码17:
import base64
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
更多用法可参考我写的另一篇博文:深入理解 Python 的 base64 模块
22. html库
- 将HTML实体转换为字符串:
from html import unescape unescaped_text = unescape(text)
23. ftfy库:修复字符编码bug
Home - ftfy: fixes text for you
24. JioNLP包
- 从自然语言中抽取时间:请参考我撰写的另一篇博文Python3中对时间的处理(持续更新ing…)
- 从自然语言中抽取金额18
示例代码:
text="张三赔偿李大花人民币车费601,293.11元,工厂费大约一万二千三百四十五元,利息9佰日元,打印费十块钱。"
res = jio.ner.extract_money(text, with_parsing=False)
#[{'text': '601,293.11元', 'offset': [12, 23], 'type': 'money'}, {'text': '大约一万二千三百四十五元', 'offset': [27, 39], 'type': 'money'}, {'text': '9佰日元', 'offset': [42, 46], 'type': 'money'}, {'text': '十块钱', 'offset': [50, 53], 'type': 'money'}]
number_str_list=[jio.parse_money(x["text"]) for x in res]
#[{'num': '601293.11', 'case': '元', 'definition': 'accurate'}, {'num': '12345.00', 'case': '元', 'definition': 'blur'}, {'num': '900.00', 'case': '日元', 'definition': 'accurate'}, {'num': '10.00', 'case': '元', 'definition': 'accurate'}]
#注意这里num的值可能是一个数组
- 清洗文本:步骤包括去除 html 标签、去除异常字符(非 UTF-8 编码造成的异常字符)、去除冗余字符(多个连续的空格,“~~~~”等重复冗余信息,缩减为1个字符)、去除括号补充内容、去除 URL、去除 E-mail、去除电话号码,将全角字母数字空格替换为半角,一般用于将其当做无关噪声,处理分析数据。
>>> text = '''<p><br></p> <p><span>在17日举行的十三届全国人大一次会议记者会上,环境保护部部长李干杰就“打好污染防治攻坚战”相关问题回答记者提问。李干杰表示
,打好污染防治攻坚战,未来将聚焦“围绕三类目标,突出三大领域,强化三个基础”开展具体工作。</span></p><p><span>顶层设计聚焦“三个三”</span></p><p><span>党的十八大以来>,我国生态环境保护工作乃至整个生态文明建设工作,决心之大、力度之大、成效之大前所未有,取得了历史性成就,发生了历史性变革。(责任编辑:唐小林)联系电话:13302130583,邮箱:dongrixinyu.89@163.com~~~~'''
>>> res = jionlp.clean_text(text)
>>> print(res)
>>> print(jionlp.clean_text.__doc__)
# ' 在17日举行的十三届全国人大一次会议记者会上,环境保护部部长李干杰就“打好污染防治攻坚战”相关问题回答记者提问。李干杰表示,打好污染防治攻坚战,未来将
聚焦“围绕三类目标,突出三大领域,强化三个基础”开展具体工作。顶层设计聚焦“三个三”党的十八大以来,我国生态环境保护工作乃至整个生态文明建设工作,决心之大、力度之大、>成效之大前所未有,取得了历史性成就,发生了历史性变革。联系电话:,邮箱:~'
25. difflib:比较序列
difflib — 计算差异的辅助工具 — Python 3.11.5 文档
- SequenceMatcher
可以比较任何可哈希的序列对象
计算字符串a和b的相似度:SequenceMatcher(None, a, b).ratio()(会返回一个介于0和1之间的浮点数,用于描述这两个字符串的相似程度。返回值为 1 表示两个字符串完全相同,而返回值为 0 表示两个字符串没有任何相似之处。)

26. signal包
请参考我单独写的博文:Python signal 模块详解:优雅处理异步事件
27. sys包:系统相关的变量和函数
我现在统一独立出了一篇介绍博文,请参考:Python 3 sys模块:管理Python运行环境
28. importlib包:动态导入模块、函数
这个包的用处主要是有时我需要动态地决定我要导入什么模块或者函数,比如根据模型名称(字符串)来指定模块名。
29. appdirs:应用路径管理
数据路径(字符串格式):appdirs.user_data_dir(appname=app_name)
15. 实现其他小功能
将字符串限制在6000字节以内
这里主要是考虑多种语言的场景,英语反正一个字母就一个字节:
先将字符串编码为字节串,然后再进行长度检查和切片
def limit_byte_length(s, max_bytes):
# 将字符串编码为字节串
byte_str = s.encode('utf-8')
# 如果字节串的长度超过最大字节长度,进行切片
if len(byte_str) > max_bytes:
byte_str = byte_str[:max_bytes]
# 将字节串解码回字符串
s = byte_str.decode('utf-8', 'ignore')
return s
# 测试
s = "这是一个测试字符串"
max_bytes = 6000
s = limit_byte_length(s, max_bytes)
如果一个字符的一部分字节被切片掉,解码时会产生错误。为了避免这个问题,我们在解码时使用了'ignore'错误处理选项,这会忽略所有无法解码的字节。
这个函数假设你的字符串是UTF-8编码的。如果你的字符串使用其他编码,你需要相应地修改编码和解码的部分。
16. 本文撰写过程中参考的其他资料
- Python3 lower()方法 | 菜鸟教程
- Python3 strip()方法 | 菜鸟教程
- Python3 错误和异常 | 菜鸟教程
- Python3 集合 | 菜鸟教程
- Python Set intersection() 方法 | 菜鸟教程
- Python打印对象的全部属性_来玩魔王的咚!的技术博客_51CTO博客
- Python3 List count()方法 | 菜鸟教程
- Python3 find()方法 | 菜鸟教程
- python3利用smtplib通过qq邮箱发送邮件_嗨学编程的博客-优快云博客
- Python系列文章-Python字符串修饰符总结 | RongXiang
- python 删除文件夹、删除非空文件夹_python删除文件夹_suibianshen2012的博客-优快云博客
- Python中list列表、元组、字典前面加星号是什么意思?_元祖前面加*_努力改掉拖延症的小白的博客-优快云博客
- Python list变量加星号,字典变量前面加星号 - 知乎
- 菜鸟教程-Python3函数
- python计算两个日期之间的天数、月数相差_python计算日期之间月份差_Charles.zhang的博客-优快云博客
- python 字符串去除中文_python 去除中文_luoganttcc的博客-优快云博客
- python3中exec_Python中两大神器&exec() &eval()-优快云博客
- python学习笔记——tqdm使用以及与pandas的搭配使用_tqdm.pandas()-优快云博客
- 使用Python部署机器学习模型的10个实践经验
python - what does the __file__ variable mean/do? - Stack Overflow
请不要再使用 __file__ 啦! | 卡瓦邦噶! ↩︎Python3 filter() 函数 | 菜鸟教程
Python中如何从列表中删除None值_python输出none怎么去掉_word_mhg的博客-优快云博客 ↩︎Python函数独立星号()分隔的命名关键字参数_python 函数传入参数以作为分割_LaoYuanPython的博客-优快云博客 ↩︎
reqiests_SyntaxError: Non-UTF-8 code starting with ‘\xe5’ in file-优快云博客
python报错Non-ASCII character ‘\xe5’ in file的解决方法-优快云博客 ↩︎python在jupyter notebook/terminal/console下的输出清空_jupyter lab 清空以下控制台_SL_World的博客-优快云博客:这篇文章中也介绍了终端清空输出的解决方案,但我不知为啥无法实现 ↩︎
python - How to programmatically generate markdown output in Jupyter notebooks? - Stack Overflow ↩︎
warnings.filterwarnings(“ignore”)代码解析_我是管小亮的博客-优快云博客_filterwarnings ↩︎
python - I use chardet to test encode , but i got error - Stack Overflow ↩︎
python - How to encode an Excel File to base64 - Stack Overflow ↩︎
官方教程参考这两篇:https://github.com/dongrixinyu/JioNLP/wiki/NER-说明文档#user-content-货币金额实体抽取
https://github.com/dongrixinyu/JioNLP/wiki/正则抽取与解析-说明文档#user-content-货币金额解析 ↩︎

























 到【灌水乐园】发言
到【灌水乐园】发言









