



一、前言
文件位置:./models/yolo.py
本周任务:将yolov5s网络模型中的C3模块按照下图方式修改形成C2模块,并将C2模块插入第2层与第3层之间,且跑通yolov5。
💫任务提示:
提示1:需要修改./models/common.py、./models/yolo.py、./models/yolov5s.yaml文件
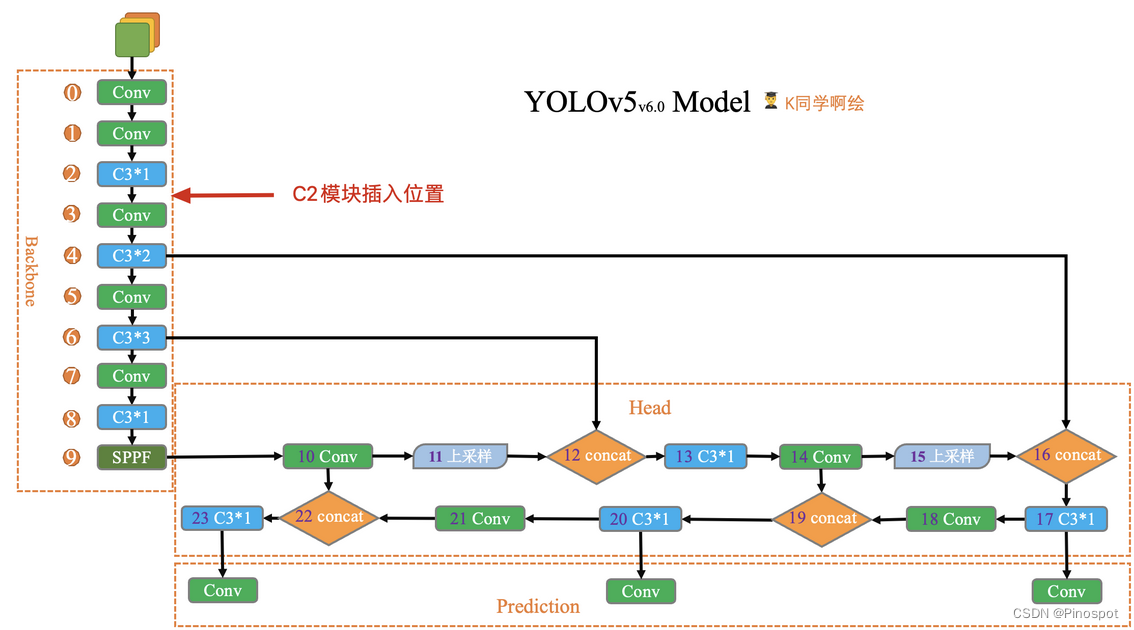
提示2:C2模块与C3模块是非常相似的两个模块,我们要插入C2到模型当中,只需要找到哪里有C3模块,然后在其附近加上C2即可(插入到Backbone中)。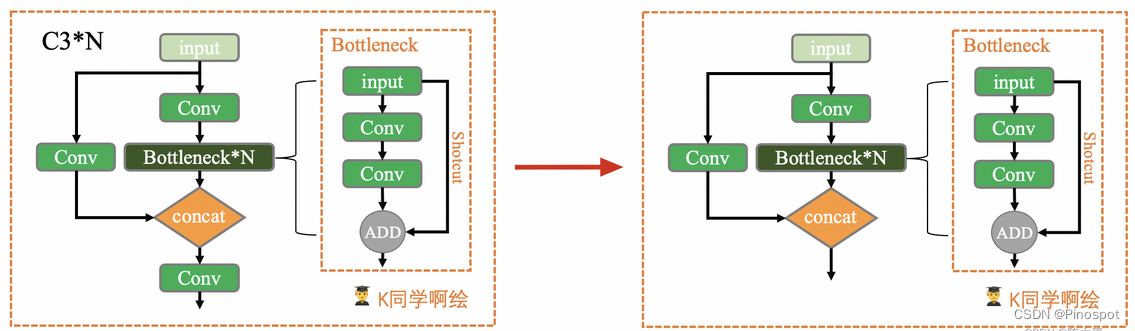
二、导入需要的包
import argparse # 解析命令行参数模块
import contextlib
import os
import platform
import sys # sys系统模块,包含了与Python解释器和它的环境有关的函数
from copy import deepcopy # 数据拷贝模块,深拷贝
from pathlib import Path # Path将str转换为Path对象,使字符串路径易于操作
FILE = Path(__file__).resolve()
ROOT = FILE.parents[1] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
if platform.system() != 'Windows':
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import *
from models.experimental import *
from utils.autoanchor import check_anchor_order
from utils.general import LOGGER, check_version, check_yaml, make_divisible, print_args
from utils.plots import feature_visualization
from utils.torch_utils import (fuse_conv_and_bn, initialize_weights, model_info, profile, scale_img, select_device,
time_sync)
# 导入thop包,用于计算FLOPs
try:
import thop # for FLOPs computation
except ImportError:
thop = None
三、改动parse_model函数
def parse_model(d, ch): # model_dict, input_channels(3)
# Parse a YOLOv5 model.yaml dictionary
''' 用在上面DetectionModel模块中
解析模型文件(字典形式),并搭建网络结构
这个函数其实主要做的就是:
更新当前层的args(参数),计算c2(当前层的输出channel)
->使用当前层的参数搭建当前层
->生成 layers + save
:params d: model_dict模型文件,字典形式{dice: 7}(yolov5s.yaml中的6个元素 + ch)
:params ch: 记录模型每一层的输出channel,初始ch=[3],后面会删除
:return nn.Sequential(*layers): 网络的每一层的层结构
:return sorted(save): 把所有层结构中的from不是-1的值记下,并排序[4,6,10,14,17,20,23]
'''
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
# 读取字典d中的anchors和parameters(nc,depth_multiple,width_multiple)
anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
LOGGER.info(f"{colorstr('activation:')} {act}") # print
# na: number of anchors 每一个predict head上的anchor数=3
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
# no: number of outputs 每一个predict head层的输出channel=anchors*(classes+5)=75(VOC)
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
''' 开始搭建网络
layers: 保存每一层的层结构
save: 记录下所有层结构中from不是-1的层结构序号
c2: 保存当前层的输出channel
'''
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
# from: 当前层输入来自哪些层
# number: 当前层数,初定
# module: 当前层类别
# args: 当前层类参数,初定
# 遍历backbone和head的每一层
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
# 得到当前层的真实类名,例如:m = Focus -> <class 'models.common.Focus'>
m = eval(m) if isinstance(m, str) else m # eval strings
# 没什么用
for j, a in enumerate(args):
with contextlib.suppress(NameError):
args[j] = eval(a) if isinstance(a, str) else a # eval strings
# --------------------更新当前层的args(参数),计算c2(当前层的输出channel)--------------------
# depth gain 控制深度,如yolov5s: n*0.33,n: 当前模块的次数(间接控制深度)
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:
# c1: 当前层的输入channel数; c2: 当前层的输出channel数(初定); ch: 记录着所有层的输出channel数
c1, c2 = ch[f], args[0]
# no=75,只有最后一层c2=no,最后一层不用控制宽度,输出channel必须是no
if c2 != no: # if not output
# width gain 控制宽度,如yolov5s: c2*0.5; c2: 当前层的最终输出channel数(间接控制宽度)
c2 = make_divisible(c2 * gw, 8)
# 在初始args的基础上更新,加入当前层的输入channel并更新当前层
# [in_channels, out_channels, *args[1:]]
args = [c1, c2, *args[1:]]
# 如果当前层是BottleneckCSP/C3/C3TR/C3Ghost/C3x,则需要在args中加入Bottleneck的个数
# [in_channels, out_channels, Bottleneck个数, Bool(shortcut有无标记)]
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:
args.insert(2, n) # number of repeats 在第二个位置插入Bottleneck的个数n
n = 1 # 恢复默认值1
elif m is nn.BatchNorm2d:
# BN层只需要返回上一层的输出channel
args = [ch[f]]
elif m is Concat:
# Concat层则将f中所有的输出累加得到这层的输出channel
c2 = sum(ch[x] for x in f)
# TODO: channel, gw, gd
elif m in {Detect, Segment}: # Detect/Segment(YOLO Layer)层
# 在args中加入三个Detect层的输出channel
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors 几乎不执行
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)
elif m is Contract: # 不怎么用
c2 = ch[f] * args[0] ** 2
elif m is Expand: # 不怎么用
c2 = ch[f] // args[0] ** 2
else: # Upsample
c2 = ch[f] # args不变
# -------------------------------------------------------------------------------------------
# m_: 得到当前层的module,如果n>1就创建多个m(当前层结构),如果n=1就创建一个m
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
# 打印当前层结构的一些基本信息
t = str(m)[8:-2].replace('__main__.', '') # module type <'modules.common.Focus'>
np = sum(x.numel() for x in m_.parameters()) # number params 计算这一层的参数量
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
# 把所有层结构中的from不是-1的值记下 [6,4,14,10,17,20,23]
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
# 将当前层结构module加入layers中
layers.append(m_)
if i == 0:
ch = [] # 去除输入channel[3]
# 把当前层的输出channel数加入ch
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
四、调整模型
C2模块
class C2(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * 0.5) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
# 移除cv3卷积层后,若要保持最终输出的channel仍为c2,则中间层的channel需为c2/2
# 设置e=0.5即可,取默认值不变
return torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1)
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
''' 在C3RT模块和yolo.py的parse_model函数中被调用
:params c1: 整个C3的输入channel
:params c2: 整个C3的输出channel
:params n: 有n个子模块[Bottleneck/CrossConv]
:params shortcut: bool值,子模块[Bottlenec/CrossConv]中是否有shortcut,默认True
:params g: 子模块[Bottlenec/CrossConv]中的3x3卷积类型,=1普通卷积,>1深度可分离卷积
:params e: expansion ratio,e*c2=中间其它所有层的卷积核个数=中间所有层的的输入输出channel
'''
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
# 实验性 CrossConv
#self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
./models/yolo.py 在parse_model中增加对C2的解析
def parse_model(d, ch): # model_dict, input_channels(3)
# Parse a YOLOv5 model.yaml dictionary
''' 用在上面DetectionModel模块中
解析模型文件(字典形式),并搭建网络结构
这个函数其实主要做的就是:
更新当前层的args(参数),计算c2(当前层的输出channel)
->使用当前层的参数搭建当前层
->生成 layers + save
:params d: model_dict模型文件,字典形式{dice: 7}(yolov5s.yaml中的6个元素 + ch)
:params ch: 记录模型每一层的输出channel,初始ch=[3],后面会删除
:return nn.Sequential(*layers): 网络的每一层的层结构
:return sorted(save): 把所有层结构中的from不是-1的值记下,并排序[4,6,10,14,17,20,23]
'''
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
# 读取字典d中的anchors和parameters(nc,depth_multiple,width_multiple)
anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
LOGGER.info(f"{colorstr('activation:')} {act}") # print
# na: number of anchors 每一个predict head上的anchor数=3
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
# no: number of outputs 每一个predict head层的输出channel=anchors*(classes+5)=75(VOC)
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
''' 开始搭建网络
layers: 保存每一层的层结构
save: 记录下所有层结构中from不是-1的层结构序号
c2: 保存当前层的输出channel
'''
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
# from: 当前层输入来自哪些层
# number: 当前层数,初定
# module: 当前层类别
# args: 当前层类参数,初定
# 遍历backbone和head的每一层
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
# 得到当前层的真实类名,例如:m = Focus -> <class 'models.common.Focus'>
m = eval(m) if isinstance(m, str) else m # eval strings
# 没什么用
for j, a in enumerate(args):
with contextlib.suppress(NameError):
args[j] = eval(a) if isinstance(a, str) else a # eval strings
# --------------------更新当前层的args(参数),计算c2(当前层的输出channel)--------------------
# depth gain 控制深度,如yolov5s: n*0.33,n: 当前模块的次数(间接控制深度)
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C2, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:
# c1: 当前层的输入channel数; c2: 当前层的输出channel数(初定); ch: 记录着所有层的输出channel数
c1, c2 = ch[f], args[0]
# no=75,只有最后一层c2=no,最后一层不用控制宽度,输出channel必须是no
if c2 != no: # if not output
# width gain 控制宽度,如yolov5s: c2*0.5; c2: 当前层的最终输出channel数(间接控制宽度)
c2 = make_divisible(c2 * gw, 8)
# 在初始args的基础上更新,加入当前层的输入channel并更新当前层
# [in_channels, out_channels, *args[1:]]
args = [c1, c2, *args[1:]]
# 如果当前层是BottleneckCSP/C2/C3/C3TR/C3Ghost/C3x,则需要在args中加入Bottleneck的个数
# [in_channels, out_channels, Bottleneck个数, Bool(shortcut有无标记)]
if m in {BottleneckCSP, C2, C3, C3TR, C3Ghost, C3x}:
args.insert(2, n) # number of repeats 在第二个位置插入Bottleneck的个数n
n = 1 # 恢复默认值1
elif m is nn.BatchNorm2d:
# BN层只需要返回上一层的输出channel
args = [ch[f]]
elif m is Concat:
# Concat层则将f中所有的输出累加得到这层的输出channel
c2 = sum(ch[x] for x in f)
# TODO: channel, gw, gd
elif m in {Detect, Segment}: # Detect/Segment(YOLO Layer)层
# 在args中加入三个Detect层的输出channel
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors 几乎不执行
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)
elif m is Contract: # 不怎么用
c2 = ch[f] * args[0] ** 2
elif m is Expand: # 不怎么用
c2 = ch[f] // args[0] ** 2
else: # Upsample
c2 = ch[f] # args不变
# -------------------------------------------------------------------------------------------
# m_: 得到当前层的module,如果n>1就创建多个m(当前层结构),如果n=1就创建一个m
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
# 打印当前层结构的一些基本信息
t = str(m)[8:-2].replace('__main__.', '') # module type <'modules.common.Focus'>
np = sum(x.numel() for x in m_.parameters()) # number params 计算这一层的参数量
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
# 把所有层结构中的from不是-1的值记下 [6,4,14,10,17,20,23]
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
# 将当前层结构module加入layers中
layers.append(m_)
if i == 0:
ch = [] # 去除输入channel[3]
# 把当前层的输出channel数加入ch
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
./models/yolov5s.yaml 插入C2模块
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 3, C2, [128]], # 在原第2层和原第3层之间插入C2模块
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]


















 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









