



 本文介绍了DBSCAN聚类算法的工作原理,包括中心点、边缘点和孤立点的概念,并提供了伪代码及Python示例。同时推荐了一个网站供读者观察不同聚类方法的动态演示。
本文介绍了DBSCAN聚类算法的工作原理,包括中心点、边缘点和孤立点的概念,并提供了伪代码及Python示例。同时推荐了一个网站供读者观察不同聚类方法的动态演示。
首先推荐一个国外的网站
Visualizing DBSCAN Clustering (naftaliharris.com)这个网站不仅可以看DBSCAN还可以看K-means和系统聚类的动态演示
一、DBSCAN原理
DBSCAN主要将需要遍历的点分为3类:中心点,边缘点,孤立点
中心点:任意选取一个样本点,并在半径Eps中搜索是否存在minpoints个点,如果存在,则为中心点
边缘点:对于一个样本点,如果其在其本身的Eps半径内没有minpoints个点,但其在其余中心点的范围内,则称其为边缘点
孤立点:既不是中心点也不是边缘点
配上下面这个图可能会更好理解一下
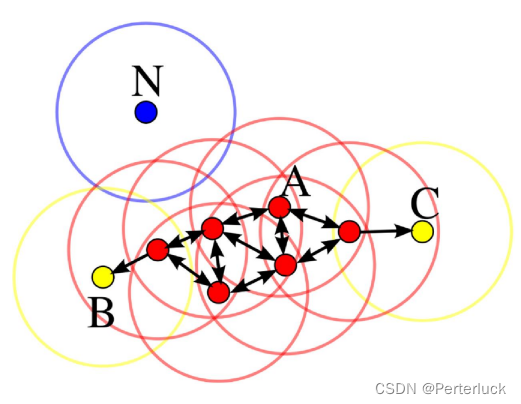
那么算法本身其实也就逐渐明晰了:其实就是不断遍历寻找是否其满足在指定半径内有指定点,并将中心点及其包含的点作为一个簇(类),最后将同属一簇的绘上同一颜色展示,下面是wiki百科上有关DBSCAN伪代码的展示:
DBSCAN(D, eps, MinPts) {
C = 0
for each point P in dataset D {
if P is visited
continue next point
mark P as visited
NeighborPts = regionQuery(P, eps)
if sizeof(NeighborPts) < MinPts
mark P as NOISE
else {
C = next cluster
expandCluster(P, NeighborPts, C, eps, MinPts)
}
}
}
expandCluster(P, NeighborPts, C, eps, MinPts) {
add P to cluster C
for each point P' in NeighborPts {
if P' is not visited {
mark P' as visited
NeighborPts' = regionQuery(P', eps)
if sizeof(NeighborPts') >= MinPts
NeighborPts = NeighborPts joined with NeighborPts'
}
if P' is not yet member of any cluster
add P' to cluster C
}
}
regionQuery(P, eps)
return all points within P's eps-neighborhood (including P)那么跟着伪代码其实就很好写出具体代码了:
#encoding=gbk
import numpy as np
import matplotlib.pyplot as plt
def dbscan(data, eps, min_pts):
labels = [0] * len(data)
cluster_id = 0
for i in range(len(data)):
if labels[i] != 0:
continue
neighbors = get_neighbors(data, i, eps)
if len(neighbors) < min_pts:
labels[i] = -1 # noise point
else:
cluster_id += 1
labels[i] = cluster_id
expand_cluster(data, labels, i, neighbors, cluster_id, eps, min_pts)
return labels
def expand_cluster(data, labels, point_idx, neighbors, cluster_id, eps, min_pts):
for neighbor in neighbors:
if labels[neighbor] == -1:
labels[neighbor] = cluster_id
elif labels[neighbor] == 0:
labels[neighbor] = cluster_id
new_neighbors = get_neighbors(data, neighbor, eps)
if len(new_neighbors) >= min_pts:
neighbors += new_neighbors
def get_neighbors(data, point_idx, eps):
neighbors = []
for i in range(len(data)):
if np.linalg.norm(data[i] - data[point_idx]) < eps:
neighbors.append(i)
return neighbors
# 生成示例数据
np.random.seed(0)
#产生1000个2维数据
data = np.random.randn(1000, 2)
# 使用DBSCAN进行聚类
#选择圆半径和最低包含点个数
eps = 0.5
min_pts = 3
labels = dbscan(data, eps, min_pts)
##黑色作为孤立点
# 绘制聚类结果
plt.scatter(data[:, 0], data[:, 1], c=labels)
plt.show()
附上一张结果图:
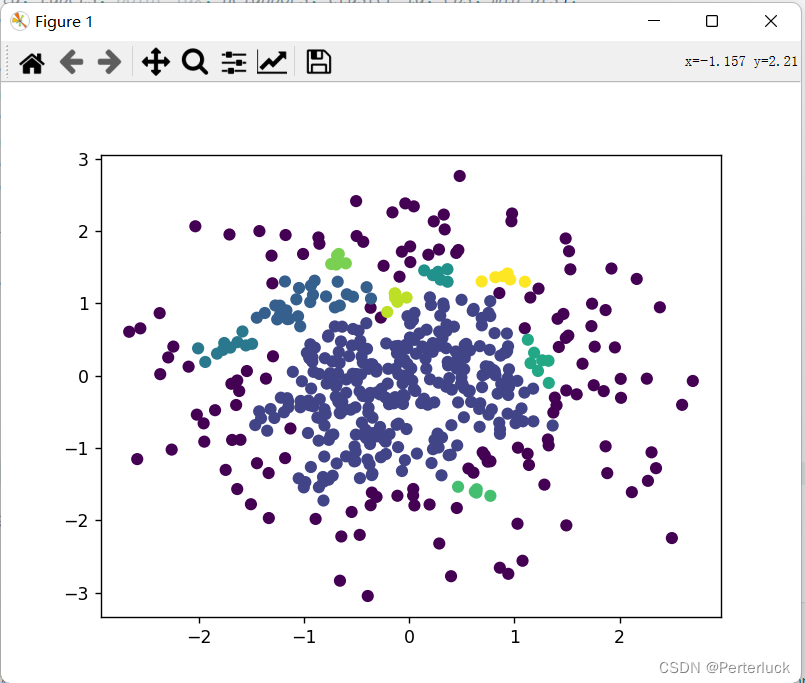


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









