






 本文详细介绍了Hbase的相关概念,包括其无模式、面向列等特性,以及Hbase的集群结构,如client、Zookeeper、HMaster和HRegionServer的角色。此外,还涵盖了Hbase的安装部署、集群启动停止、Shell命令使用,以及内部原理和寻址机制。通过实例解析了rowkey的设计原则,包括长度、唯一性和散列原则。
本文详细介绍了Hbase的相关概念,包括其无模式、面向列等特性,以及Hbase的集群结构,如client、Zookeeper、HMaster和HRegionServer的角色。此外,还涵盖了Hbase的安装部署、集群启动停止、Shell命令使用,以及内部原理和寻址机制。通过实例解析了rowkey的设计原则,包括长度、唯一性和散列原则。
1、主要内容
-
1、掌握Hbase相关概念
-
2、掌握Hbase集群搭建
-
3、掌握Hbase shell 命令的使用
-
4、掌握Hbase内部原理
-
5、掌握Hbase的寻址机制
-
6、掌握Hbase的rowkey设计
2、Hbase概述
2.1 hbase是什么
hbase是基于hdfs进行数据的存储,具有高可靠、高性能、列存储、可伸缩、实时读写的nosql数据库系统。
可以按照主键(rowkey)和主键的范围去查询数据,后期查询数据的性能也是非常高。2.2 hbase表的特性
-
1、大
-
hbase表中可以存储海量的数据
-
-
2、无模式
-
hbase表中不同的行可以有截然不同的列,这一点跟mysql不一样。
-
-
3、面向列
-
hbase表中的数据是面向列进行存储,这一点跟mysql不一样。
-
-
4、稀疏
-
hbase表中为null的列,可以不占用实际的存储空间
-
-
5、数据的多版本
-
hbase表中的字段的结果可以存储多个不同的值,每一个值都给一个版本号,这个版本号就是按照数据的插入时间它的时间戳去确定。时间戳就是数据的版本号
-
-
6、数据类型单一
-
hbase表中的数据都是按照字节数组进行存储
-
2.3 hbase表的逻辑视图

3、hbase集群结构

-
1、client
-
hbase客户端的api的接口
-
-
2、zookeeper
-
搭建hbase集群的时候需要依赖于zk集群
-
作用
-
1、实现了hbase集群的高可用
-
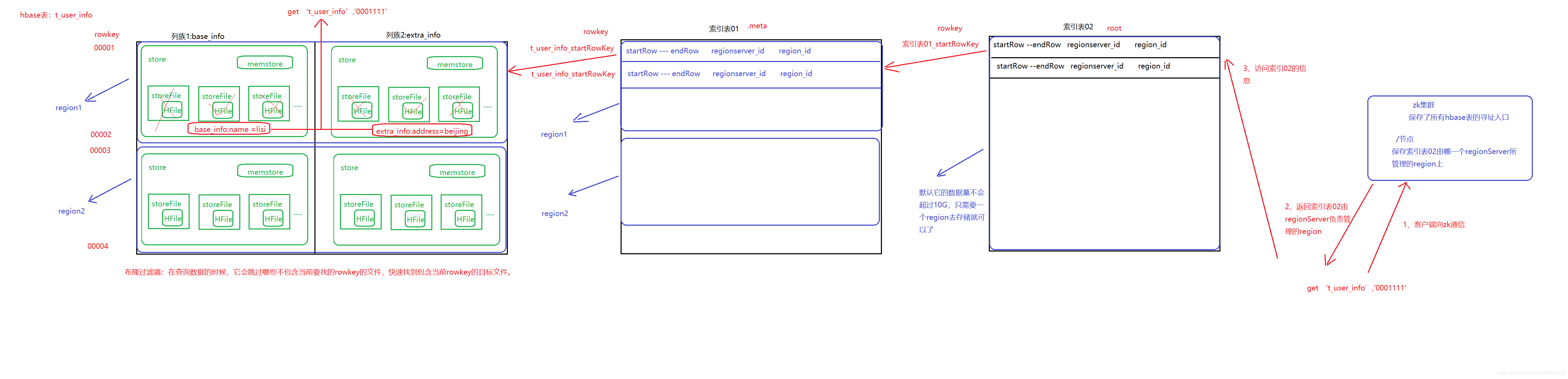
2、保存了所有hbase表的寻址入口,客户端需要操作hbase表的时候,需要连接上zk集群
-
3、接受HMaster和HRegionServer注册和心跳信息,后期某一个HRegionServer挂掉了, zk会感知到,把这个信息通知给HMaster
-
-
-
3、HMaster
-
它是hbase集群的老大
-
作用
-
1、它会负责hbase表的创建和删除
-
2、它会把region分配给对应的HRegionServer
-
3、HMaster发现挂掉的HRegionServer,把它所管理的region重新分配给其他活着的HRegionServer
-
4、它会实现HRegionServer负载均衡
-
-
-
-
4、HRegionServrer
-
它是hbase集群的小弟
-
作用
-
1、它会接受客户端的读写请求
-
2、它会负责管理对应的region
-
3、它会切分在运行过程中变得过大的region
-
-
-
-
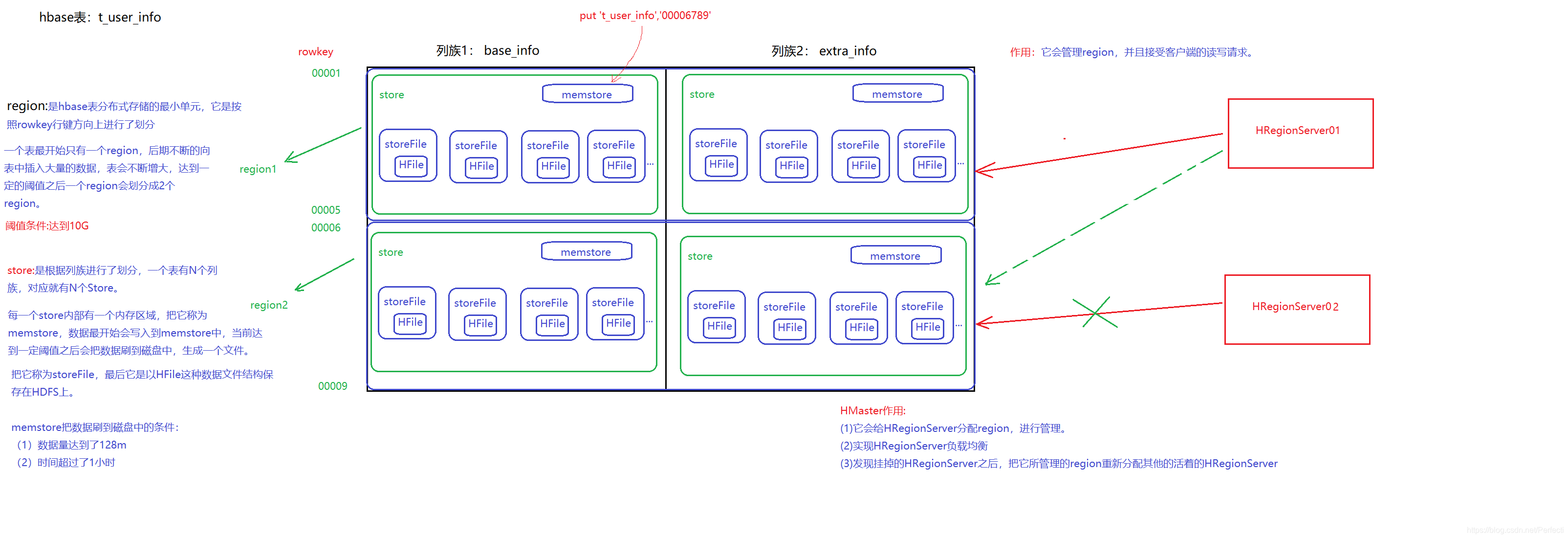
5、region
-
它是hbase集群中表进行分布式存储的最小单元,是依赖于HDFS。
-
4、hbase集群安装部署
-
1、准备
-
事先搭建hadoop,zk集群
-
-
2、下载对应的安装包
-
http://archive.apache.org/dist/hbase/1.2.1/hbase-1.2.1-bin.tar.gz
-
hbase-1.2.1-bin.tar.gz
-
-
3、规划安装目录
-
/export/servers
-
-
4、上传安装包到服务器中
-
5、解压安装包
-
tar -zxvf hbase-1.2.1-bin.tar.gz -C /export/servers
-
-
6、重命名解压目录
-
mv hbase-1.2.1 hbase
-
-
7、修改配置文件
-
需要把hadoop中的配置文件 core-site.xml hdfs-site.xml拷贝到hbase/conf
-
vim hbase-env.sh
#指定java环境变量 export JAVA_HOME=/export/servers/jdk #指定hbase集群由外部的zk集群管理 export HBASE_MANAGES_ZK=false -
vim hbase-site.xml
<!-- 指定hbase在HDFS上存储的路径 --> <property> <name>hbase.rootdir</name> <value>hdfs://node1:9000/hbase</value> </property> <!-- 指定hbase是分布式的 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 指定zk的地址,多个用“,”分割 --> <property> <name>hbase.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> -
vim regionservers
#指定哪些节点是HRegionServer node2 node3 -
vim backup-masters
#指定备用的Hmaster地址 node2
-
-
8、配置hbase环境变量
-
vim /etc/profile
export HBASE_HOME=/export/servers/hbase export PATH=$PATH:$HBASE_HOME/bin
-
-
9、分发
scp -r hbase node2:/export/servers scp -r hbase node3:/export/servers scp /etc/profile node2:/etc scp /etc/profile node3:/etc -
10、让所有节点的hbase环境变量生效
-
在所有节点执行
-
source /etc/profile
-
-
5、hbase集群启动和停止
-
启动hdfs和zk集群
-
1、启动hbase集群
-
在主节点node1上
-
start-hbase.sh
-
在node1上执行了上面这个脚本,它会在node1上启动Hmaster,它就是活着的HMaster
-
然后根据regionServers来指定的节点来启动HRegionServer
-
然后根据backup-masters来指定的节点来启动备用的HMaster
-
-
-
2、停止hbase集群
-
在主节点node1上
-
stop-hbase.sh
-
-
6、hbase的web管理界面
-
1、首先启动好hbase集群
-
访问 HMaster主机名:16010
-
7、hbase shell命令使用
-
1、创建一个表t_user_info
create 't_user_info','base_info','extra_info' -
2、查看有哪些表
list -
3、查看表的描述信息
describe 't_user_info' -
4、修改表的属性
alter 't_user_info', NAME => 'base_info', VERSIONS => 3 alter 't_user_info','other_info' -
5、添加数据
put 't_user_info','00001','base_info:name','zhangsan' put 't_user_info','00001','base_info:age','30' put 't_user_info','00001','extra_info:address','beijing' put 't_user_info','00002','base_info:name','lisi' put 't_user_info','00002','base_info:age','40' -
6、查询数据
get 't_user_info','00001' get 't_user_info','00001',{TIMERANGE => [1541823091963, 1541823091966]} get 't_user_info','00001',{COLUMN => 'base_info'} get 't_user_info','00001',{COLUMN => 'base_info:age'} scan 't_user_info' get 't_user_info','00001',{COLUMN => 'base_info:age',VERSIONS => 3} -
7、删除数据
delete 't_user_info','00001','base_info:name' deleteall 't_user_info','00001' -
8、删除表
disable 't_user_info' drop 't_user_info'
8、Hbase内部原理
9、hbase的寻址机制
10、hbase的rowkey设计
-
1、长度原则
-
设计rowkey的时候,长度不要太长,尽量越短越好,一般不要超过16个字节
-
数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;
-
v MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
-
-
-
2、唯一原则
-
每条数据的rowkey保证唯一,不相同
-
-
3、散列原则
-
保证rowkey高位随机,这样一来,数据会均衡流入到不同的region中,实现regionserver负载均衡
-
如果rowkey的高位都相同,这个时候数据都流入到同一个region中去了,导致regionserver热点问题
-
热点问题提供解决方案
-
1、加盐
-
就是在rowkey前面加上一个随机数
-
rowkey=随机数+......
-
-
2、哈希
-
拿到对应的字段通过hash算法,获取得到一个随机数
-
name.hash算法----->随机数
-
-
3、反转
-
可以把进行改变的结果放在rowkey高位,把进行不容易改变的放在低位
136****9301----->1039****631 136****9302 136****9303
-
-
4、时间戳反转
-
1541833970932--------->2390793381451
-
-
-
更多内容请关注我的公众号:


















 1641
1641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









