



 本文详细介绍了在Scrapy框架中如何自定义和扩展各种类,包括去重URL类、自定义pipeline、代理池、HTTPS证书、动态User-Agent、下载中间件、爬虫中间件、扩展类等,并提供了各个案例的实现步骤和启用方法。
本文详细介绍了在Scrapy框架中如何自定义和扩展各种类,包括去重URL类、自定义pipeline、代理池、HTTPS证书、动态User-Agent、下载中间件、爬虫中间件、扩展类等,并提供了各个案例的实现步骤和启用方法。
scrapy框架中每一步都是可以通过自定义类或者扩展来完成你要实现的特定的功能。一般自定义的类和扩展都是有一些特定的方法的。
完成自定义类和扩展有两个步骤:
1)在spiders同级创建任意目录,根据特定的方法,自定义类,后者在middleware.py中直接之定义。
2)在setting中启用自定义的类。
本文介绍的案例:
案例1:去重url类
案例2:自定义pipeline
案例3:自定义代理池ip的应用
案例4:自定义HTTPS证书,这个自定义一般用不到。
案例5:自定义获取动态User-agent的类
案例6:自定义下载中间件,仅下载东西使用。
案例7:自定义爬虫件
案例8:自定义扩展类,根据信号操作一些东西
案例1:去重url的类,可以:在这个类中做很多的事情,比如在爬虫开始时规定一件事情,爬虫结束后规定一些事情。
步骤1:自定义类的程序,也可以放在单独的py文件中:
包含的方法,该方法名称是固定的
init方法:对象初始化,执行顺序是第2个
from_settings方法:初始化时,通过@classmethod来创建对象,执行顺序是第1个
request_seen方法:检查是否访问过,执行顺序是第4个
open方法:爬虫开始执行时,调用,执行顺序是第3个
close方法: 爬虫关闭时,被调用,执行顺序是第5个

步骤2:在settings.py文件中启用,比如这个自定义类RepeatFilter是写在"duplication.py"中的,则语句为:
DUPEFILTER_CLASS="chouti_hh.duplication.RepeatFilter"案例2:自定义piplines
包含方法:
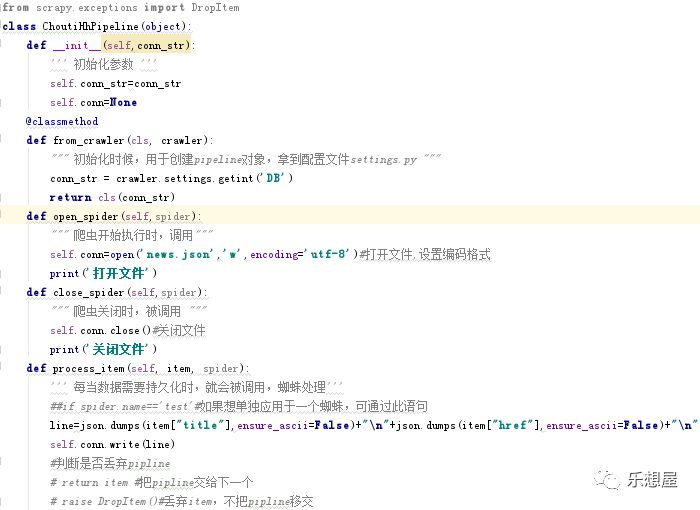
_init_方法:初始化参数
from_crawler:初始化时,用于创建pipeline对象,拿到配置文件settings.py
open_spider:爬虫开始执行时,调用
close_spider: 爬虫关闭时,被调用
process_item: 每当数据需要持久化保存时,就会被调用,蜘蛛处理
步骤1:自定义pipeline,在pipelines.py文件中可以定义多个pipeline
步骤2:在settings.py文件中启用,比如自定义的类为ChoutiHhPipeline,名称如下:
ITEM_PIPELINES = {
'chouti_hh.pipelines.ChoutiHhPipeline': 300,
}
案例3:自定义代理的类
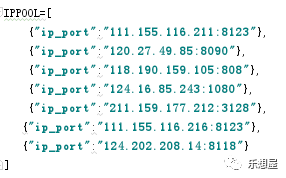
步骤1:在settings.py文件中定义可用的ip池,这个也可以使用文件导入
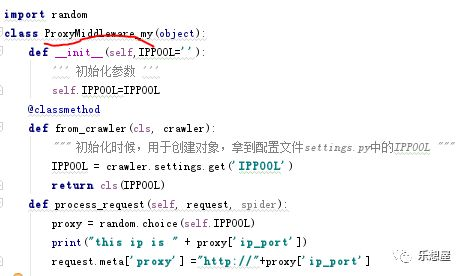
步骤2:在middlewares.py文件,新建类ProxyMiddleware_my写入以下语句:
步骤3:在settings.py文件,名称换成ProxyMiddleware_my,启用自定义的类:

案例4:自定义HTTPS证书,这个自定义一般用不到。
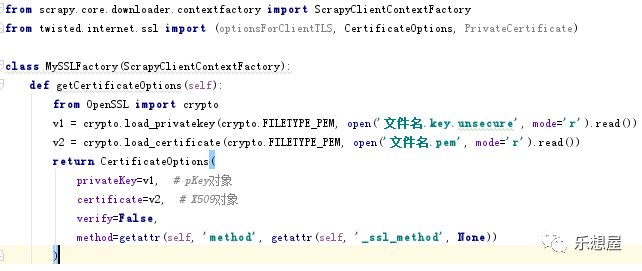
步骤1:自定义类的程序,也可以放在单独的py文件中:v1,v2来源于你存放的证书,
步骤2:在settings.py文件,名称换成ProxyMiddleware_my,启用自定义的类:

案例5:自定义动态获取header头
步骤1:在middlewares.py文件,新建类Middleware_hh写入以下语句:

步骤2:在settings.py文件,把名称换成自定义类Middleware_hh,启用自定义的类。

案例6:下载中间件:仅下载东西使用。相当于爬虫把request交给下载中间件,下载好后,返回一个response给爬虫
每个中间件就相当于一个类,假设我们设置两个中间件,写两个类,只要有一个类实现下载,其他的类不会重复下载。
下载中间件含有3个方法,以及其对应的三个返回参数的后续执行动作
process_request:
None,继续后续中间件去下载
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新调度器
process_response:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
process_exception:为了下载过程中出错的时候执行
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
步骤1:在middlewares.py文件,新建下载类,可以写多个,也可以写一个。为了看下执行顺序,以下语句以写两个类为例:
DownMiddleware1:

DownMiddleware2:

步骤2:在settings.py文件中,写上两个自定义类的名称,启用下载间

执行的顺序如下:

案例7:爬虫中间件
process_spider_input:下载完成,执行,然后交给parse处理
process_spider_output:spider处理完成,返回时调用,return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable)
process_spider_exception:异常调用,return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline
process_start_requests:爬虫启动时调用,return:包含Request对象的可迭代对象
步骤1:在middlewares.py文件中,自定义类SpiderMiddlere爬虫类

步骤2:在settings.py文件中,写上自定义类SpiderMiddlere的名称,启用爬虫类

案例8:自定义扩展类,根据信号操作一些东西
步骤1:在项目的目录下(与settings.py是同级的)新建myextend.py文件,写入以下语句:
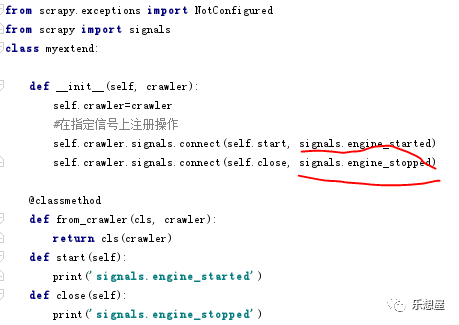
除了signals.engine_started、signals.engine_stopped,还有其他很多的自定义方法,如下:

步骤2:在settings.py文件中,写上自定义类的名称myextend,启用扩展

案例9:自动运行所有的爬虫
步骤1:在settings.py文件中,写上自定义类的名称myextend,启用扩展
scrapy-- help
步骤2:在settings.py文件中,写上项目名称+自定义命令名,启用扩展

crawlall

















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









