



D013
全国贫困县DID数据(2008-2022年)
数据简介
今天我们分析的是新更新的全国贫困县的DID数据。该数据是中国县域级2008-2022年的贫困县数据,并对其进行可视化处理,供大家研究使用。
DID数据指的是双重差分法(Difference-in-Differences,简称DID),这是一种统计方法,用于处理观察性数据中的因果推断问题。DID通过比较处理组和对照组在处理前后的变化,来估计处理效果,这种方法在政策研究等领域较为常见。对贫困县进行DID数据分析,不仅能具体评估扶贫政策的有效性,还能为未来政策制定提供科学依据,为实现精准扶贫、乡村振兴和经济高质量发展提供有力支持。
注:分析仅供参考。
数据详情
数据来源:国务院扶贫开发领导小组办公室
时间跨度:2008-2022年
数据频度:年度
数据范围:中国(县域级)
数据格式:Excel/Shp
数据概览
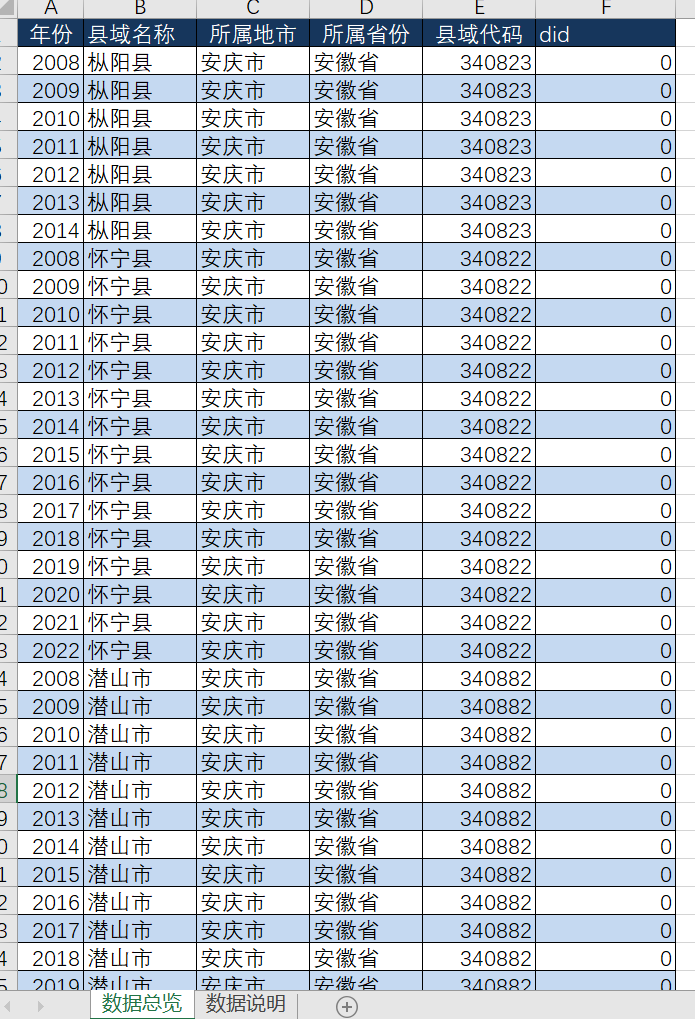
部分数据展示如下:

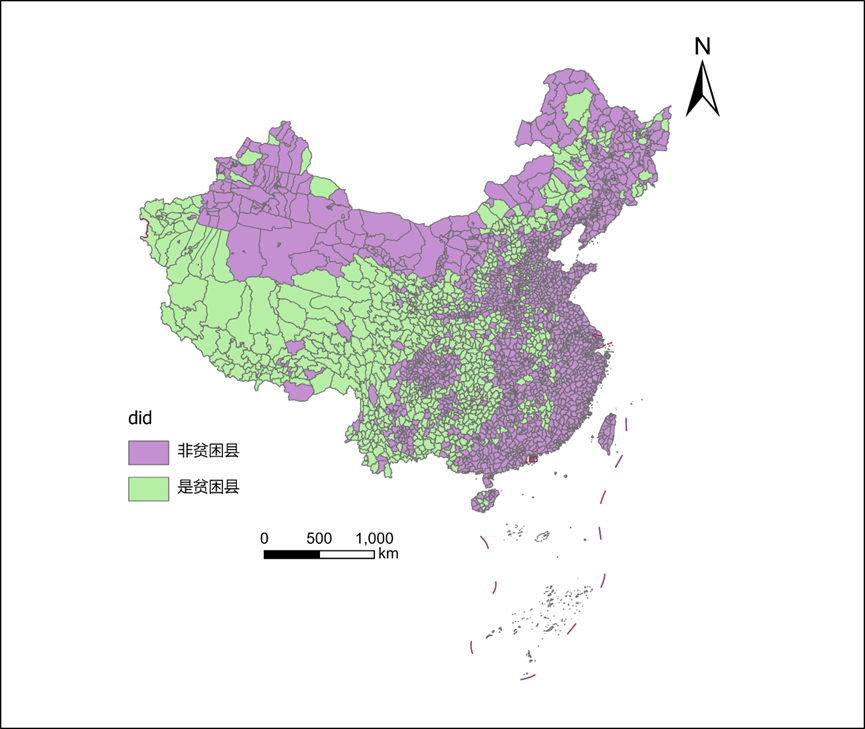
本文将贫困县DID数据进行了地图可视化处理,方便大家对其时空分布进行分析。以年为单位将原始数据分成中国省一级的数据,并对其地理坐标系设定为WGS 1984,投影坐标系设定为Albers,下图是2008年我国各省新质生产力的可视化示例。对其进行简单的分析可知,我国2008年贫困县大多集中在西部地区及中部地区,中部地区中除成都市及附近地区外大多为贫困县地区,沿海地区经济较为发达,几乎都是非贫困县地区。
参考文献
[1]马雯嘉,吴茂祯.从全面脱贫到乡村振兴:国家级贫困县政策对当地经济发展的影响[J].中国软科学,2024(S1):1-15.
[2]杨人懿,钟昌标,杨子生,等.精准扶贫政策与农村居民增收——基于云南省129个县的实证检验[J].南开经济研究,2023(03):131-150.
[3]杨智.金融发展如何影响非农就业——来自脱贫攻坚期间国家级贫困县的证据[J].投资研究,2021,40(06):129-146.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









