




 本文通过具体案例详细解析了SQL语句中的group by、order by、where及having的使用方法,展示了如何利用这些语句进行数据筛选和排序。
本文通过具体案例详细解析了SQL语句中的group by、order by、where及having的使用方法,展示了如何利用这些语句进行数据筛选和排序。
最近一直在忙着和数据库有关的一些工作,这几天在写存储过程的时候,一些mysql的语句突然感觉有些不太明白,就是group by , order by ,where , having这些语句,这次通过一个实例来总结和归纳一下,这几个语句的用法,仅供以后参考学习。
一. 首先以字面形式阐述一下这几个语句的功能:
group by:从英文上理解 就是分组的意思。需要和 聚合函数(例如:max(),count(),avg()等)配合使用,使用时至少有一个分组标识字段(例如某一列的列名)。
oder by :从英文上理解就是排序。一般后面跟上某一列的列名,然后查询到的数据会以该列的大小顺序进行排序显示,默认的是ASC(从小到大排列),desc(大到小排列)
where: 对查询到的内容进行筛选,where后面跟上限定条件,where使用在分组和排序之后。
having:作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件显示特定的组,也可以使用多个分组标准进行分组。
二. 下面来看一个例子:
首先建立一张,表名为STAFF.
1.假如我们要列出每个部门最高薪水的结果(group by的使用)。
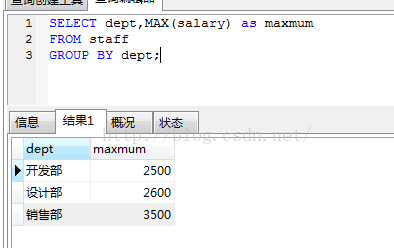
结果显示两列,分别是查询语句中需要的两个列,group by后面指定按照dept分组,正好为三组。注意select语句后面的两个查询对象需要用逗号隔开。
2. 假如我们要按照日期从小到大列出表的信息(order by 的使用)。
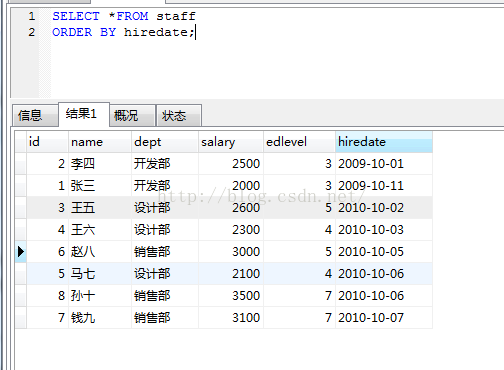
如显示结果数据按照日期的大小从小到大依次列出。
3.假如我们只想显示开发部们的信息(where的使用).
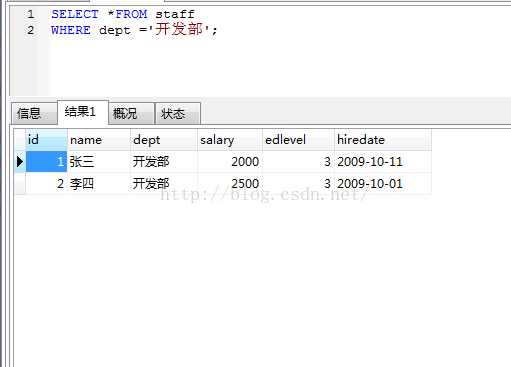
如上显示结果,where后边的限定条件为开发部(字符使用单引号)。
4.假如我们使用group by 分组过后,如1中,如果想筛选出分组后max(salary)大于3000的一组。
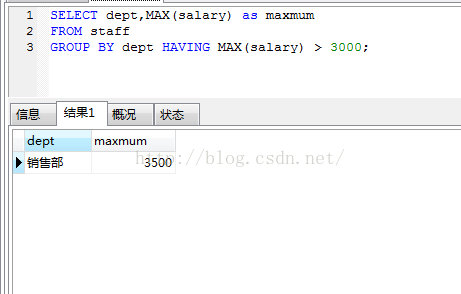
如上结果所示,筛选出分组后需要列出的组。
5. 下面来在一个例子中综合使用这几个语句。
假如我们要倒序显示日期大于 2010-10-03中 ,每个部门中工资最高且大于2000的数据。
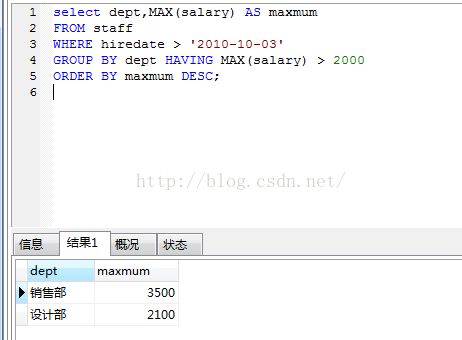
以上就是关于这几个语句的具体使用,仅供学习交流,有错忘指出。

















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









