




MapReduce:
MapReduce作业(job)是客户端需要执行的一个工作单元,包括:输入数据,MapReduce程序和配置信息
Hadoop将MapReduce的输入数据划分成等长的小数据块,称为 输入分片(input split)或 简称 "分片"
Hadoop为每个分片构建一个map任务,并由该任务来运行用户自定义的map函数,从而处理分片中的每条数据
“数据本地化优化”:hadoop在存储有输入数据(HDFS中的数据)的节点上运行map任务,无需使用宝贵的集群带宽资源
Combiner函数:属于优化方案,尽量避免map和reduce任务之间的数据传输数量
HDFS -> split -> MapTask -> 内存中shuffle(partition,sort,conbiner) -> 写入磁盘 -> copy数据给reduce -> reduce接收数据 -> merge -> reduce
HDFS:
设计:流式数据访问模式
1 超大文件
2 流式数据访问:一次写入,多次读取是最高效的
3 商用硬件:普通廉价的机器
不适用:
1 低时间延迟的数据访问:响应时间
2 大量的小文件
3 多用户写入,任意修改
为什么块有128M那么大?
为了最小化寻址开销。块大,则磁盘传输数据的时间会大于寻址时间。
HDFS集群有两类节点来管理节点:
NameNode(nn):
a 管理文件系统的命名空间,维护所有文件和目录。(永久保存)
b 记录每个文件中块所在数据节点信息(系统启动时更新)
DataNode(dn):文件系统的工作节点。作用:存储并检索数据库,并定期向namenode发送所存储块列表
SecondaryNameNode(2nn):不是NameNode的备份,存储的是部分NameNode数据,用于合并fsimage和edits日志
namenode容错机制有2种:
1 备份那些组成文件系统元数据持久状态的文件:多台机器上的namenode同步写,一般配置:将持久状态写入磁盘的同时,写入一个远程挂载的网络文件系统
2 运行一个辅助namenode,但它不能被用作namenode。
2.0版本HA:
Zookeeper(集群)调度FailoverController,每个FailoverController检查NameNode,NameNode的磁盘文件存到JournalNode(集群)上面,NameNode的主从备份(Active,Stardary),NameNode调用DataNode(集群)
Federation:NameNode过大,会拆分多个独立的NameNode,每个NameNode对应一个HA
1.0X的版本(jobTracker,TaskTracker):
1 不支持多计算框架
2 NameNode容错性差,挂了就全成垃圾数据了
YARN:资源调度
1 ResourceManager
a 处理客户端请求
b 监控NodeManager
c 启动或监控ApplicationMaster
d 资源分配分配调度
2 ApplicationMaster
a 负责数据切分
b 位应用程序申请资源并分配给内部的任务
c 任务监控与查看
3 NodeManager
a 管理单个节点的资源
b 处理ResourceManager的命令
c 处理ApplicationMaster的命令
4 Container 是Yarn中资源抽象,封装了某个节点的多维度资源,如内存,CPU,磁盘,网络等,主要为ApplicationMaster服务
最少搭建hdfs需要多少节点:17个节点
(HA)3个DataNode,2个NameNode(主从备份),3个JournalNode,2个FailoverController,3个ZK
(YARM)3个NodeManager,1个ResourceManager
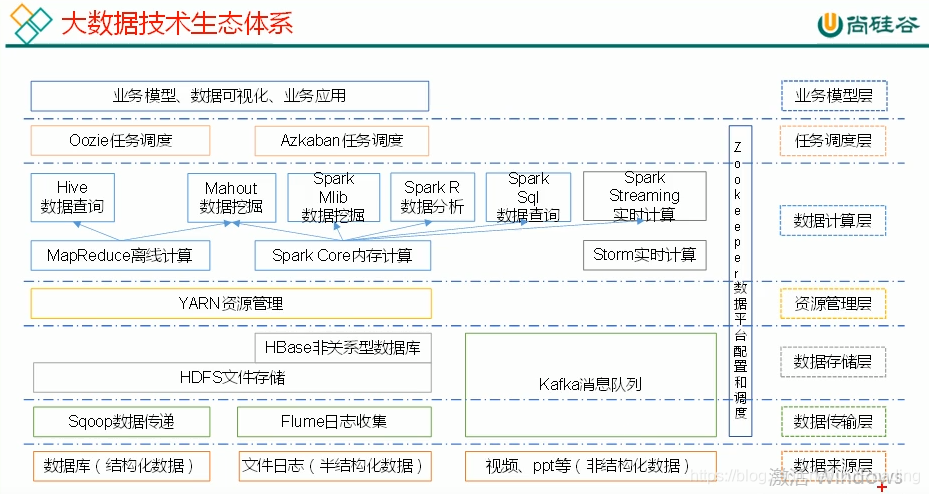
生态体系:
数据来源层:可结构化,半结构化,非结构化数据
数据传输层:sqoop数据传递,Flume日志收集,kafka
数据存储层:HDFS,Hbase,kafka
资源管理层: YARN资源管理
数据计算层:MR,SparkCore,Flink
任务调度层:Oozie任务调度,Azkaban任务调度
业务模型层:业务模型,数据可视化,业务应用


















 1549
1549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









