




空间理解能力 是多模态大语言模型(MLLMs)走向真实物理世界,成为“ 通用型智能助手 ”的关键基础 。但现有的空间智能评测基准往往有两类问题:一类高度依赖模板生成,限制了问题的多样性;另一类仅聚焦于某一种空间任务与受限场景,因此很难全面检验模型在真实世界中对空间的理解与推理能力。
近日,由 上海人工智能实验室 联合多所高校发布的 MMSI-Bench/MMSI-Video-Bench 空间智能系列基准,分别针对 多图像 与 视频级 空间智能进行了全面系统考察。
基准所使用的原始图像与视频数据来自 多样且真实的拍摄场景 ,覆盖丰富的时空信息,所有题目均由 3D视觉领域研究 人员精心 设计并严格验收 。MMSI 系列基准在任务设计上覆盖 全面且成体系的空间智能能力维度 ,具有显著挑战性,呈现出 显著的人类– AI 性能差距 ,揭示空间智能难题的攻克任重而道远。

核心贡献:
-
全人工高质量构建 最具挑战空间智能基准 :由平均研究年限>2.5的多名3D视觉研究人员 亲自把关,精细设计并 严格验收打磨 ,确保基准每一个问题 清晰准确且具备足够挑战性 ,打造高质量的空间智能基准。
-
更“全栈”的任务覆盖 以及能力考察 :源于真实世界的丰富多样的拍摄类型,覆盖了多图+视频的空间智能全面系统题型考察。
-
大规模评测 展现空间智能难点 :各种主流强模型在MMSI系列基准上表现吃力,最强推理模型GPT5/Gemini 3 Pro与人类表现差距显著,揭示模型空间智能能力边界。
-
深入分析揭示性能瓶颈 :基于实验结果的错误归类统计,初步改进尝试等深入分析,进一步揭示模型性能瓶颈,为未来的改进指引方向。
目前,MMSI基准已经被VILASR, EASI, SpaceVista, Vlaser, MSSR, 3DThinker, Actial, VST, SenseNova-SI, GCA , Seed1.8, 4D-RGPT等工作采用。诚挚欢迎更多模型开发者、组织机构申请参与评测


MMSI-Video-Bench项目主页:
https://rbl er1234.github.io/MMS I-VIdeo-Bench.github.io/
MMSI-Video-Bench论文链接:
https:/ /arxiv.org/pdf/2512.10863
MMSI-Bench项目主页:
https://runsenxu.com/projects/MMSI_Bench/
MMSI-Bench论文链接:
https://arxiv.org/pdf/2505.23764
多图空间智能基准MMSI-Bench
基准介绍
MMSI-Bench 面向 多图推理(Multi-Image Reasoning) 场景 ,旨在评估多模态模型在多图级别 对空间位置关系(Position Relationship)、运动变化(Motion)、空间属性(Attribute)的理解, 以及 多步推理(Multi-Step Reasoning) 能力(见图1),系统覆盖了多图空间智能中的核心任务设置。
MMSI-Bench基准的关键特点主要体现在:
(1) 逐步推理 :每个问题都提供 step-by-step reasoning解答 ,帮助分析模型推理过程;
(2) 高质量标注 :数据由 6位3D视觉研究 人员 全人工标注,所有数据均经过严格质检(见图2);
(3) 极具挑战性 : 题目由研究人员精心设计,具有明显挑战性,表现最好模型与人类表现仍有约 55%的 显著 差距 。

图1 MMSI-Bench 任务类型分布与数据示例
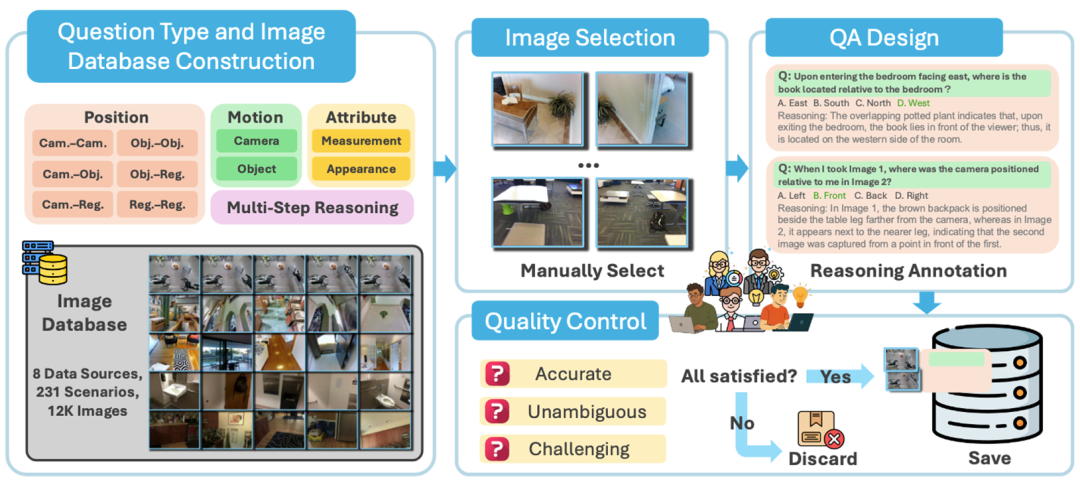
图2 MMSI-Bench 构建流程
实验与分析
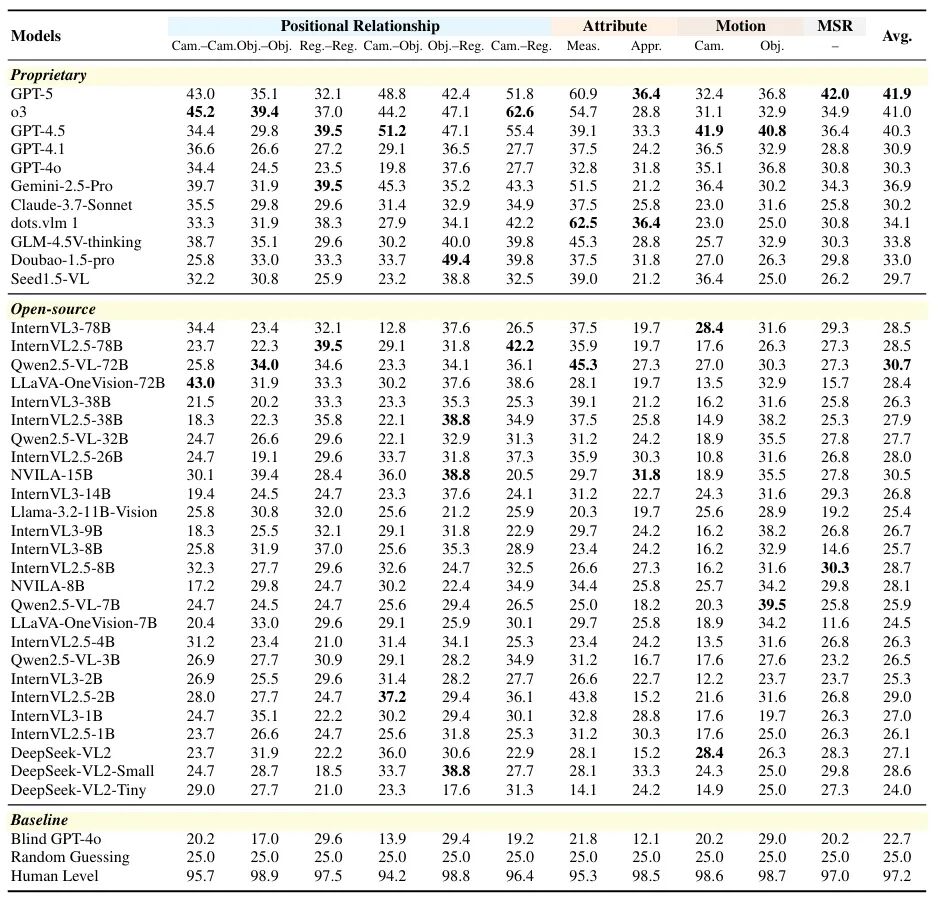
主流模型多图级空间智能表现不佳
如表1所示,研究团队对30余个主流模型进行了测评。从整体上看,所有的模型 表现均不佳 ,即使是表现最好的GPT-5也仅有41.9分,与人类表现 差距高达55% 。 按任务类型进一步拆解, 多步推理 与 相机运动理解 是当前模型最难突破的两类能力短板 。 横向对比不同模型间的表现差异,我们发现, 闭源 模型显著优于 开源 模型表现,对于同系列的模型 参数量的增加 对于模型表现提升有限。
表1 主流模型在MMSI-Bench上的评测结果对比
自动错误分析定位瓶颈, 几何重建错误 占主导
为了更好地定位模型的性能瓶颈,研究团队将模型的错误分析归纳为四大类型(如图3所示):
(1) 定位错误(Grounding Error) : 模型未能正确识别或定位图像中的关键对象或细节;
(2) 几何重建错误(Overlap-Matching and Scene-Reconstruction Error) : 模型无法在不同图像中识别并匹配指代同一真实位置或对象的对应关系,进而难以基于几何逻辑重建场景结构;
(3) 情境转换推理错误(Situation-Transformation Reasoning Error) : 在文本提示提供预设情境后,模型进行情境转换时出现偏差,例如以不同参考对象进行方向判断,或在相对方向(左/右/前/后)与绝对方向(东/南/西/北)之间进行转换时出现错误;
(4) 空间逻辑推理错误(Spatial-Logic Error) : 模型在基于空间潜在逻辑进行推理时出现失误,包括虚构不存在的空间关系、错误应用空间 关系的传递性 ,或在运动推理中选择不恰当的参考对象。
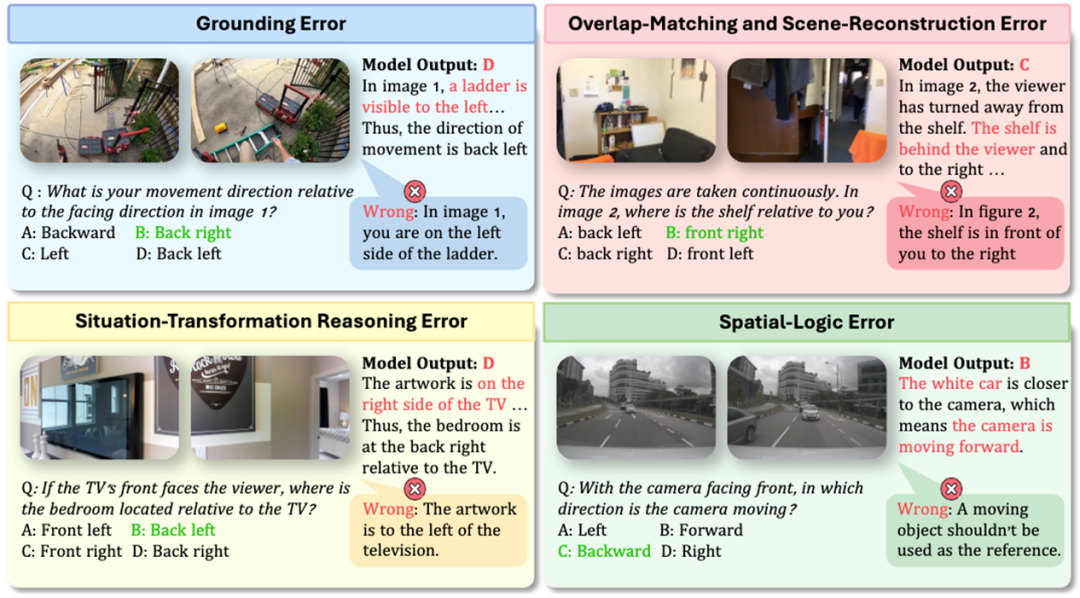
图3 MMSI-Bench上模型的四大错误类型
依托每个问题带有的reasoning解答标注,研究团队设计了一个 自动错误分析 的链路,统计GPT-4.5,GPT-4o和Qwen2.5-VL-72B三个模型的错误类型分布。如下图所示,三种模型的主要错误来源高度一致,均以“ 几何重建错误 ”为主,表明该能力是当前空间理解任务中的 核心短板。
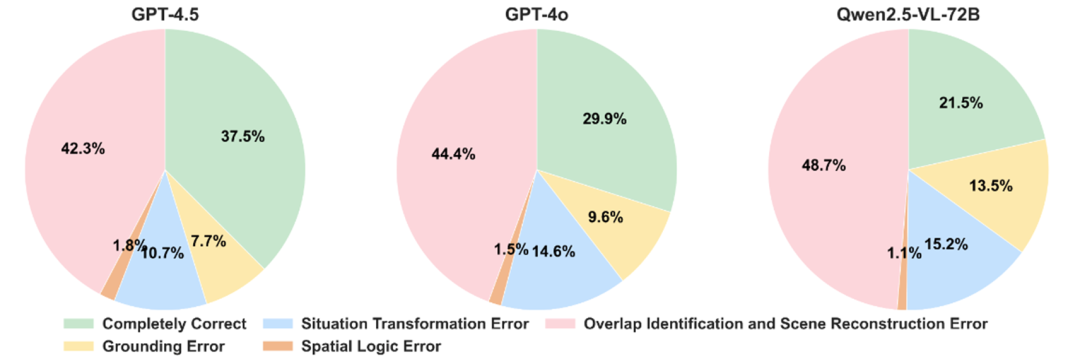
图4 模型错误分布统计(MMSI-Bench)
视频空间智能基准 MMSI-Video-Bench
基准介绍
相比MMSI-Bench,MMSI-Video-Bench从多图推理走向视频推理, 更强调模型对
全局空间构建 与 长时运动状态 的理解, 同时进一步引入了 基于时空信息的决策能力评测 ,覆盖 跨时间、多视角的多段视频推理 场景,包含 5大任务类型 : 空间构建(Spatial Construction) 、 运动理解(Motion Understanding) 、 规划(Planning) 、 预测(Prediction) 以及 跨视频推理(Cross-Video Reasoning) , 13个问题子类 ,形成一套系统而完整的视频空间智能评测体系(见图5)。

图5 MMSI-Video-Bench任务类型示例图
MMSI-Video-Bench的关键特点包括:
(1) 极具挑战性 :设计的问题具有挑战性,所有模型均表现吃力,即便是最表现最好的 Gemini 3 Pro ,与人类仍存在约 60%的性能差距 。
(2) 场景高度多样 :视频数据来源于 25个公开数据集 + 1个自建数据集 ,覆盖机器人操作、室内场景(从单房间到多层楼宇)、室外建筑与街景、自然风光、体育活动以及电影片段等多类型内容。
(3) 高质量标注 : 全部数据由 11位3D视觉研究 人员 全人工标注并进行严格质检,保证质量(如图6所示链路)。
(4) 面向领域的子基准 :受益于场景类型的丰富以及任务类型的全面性,MMSI-Video-Bench可以划分出 室内场景感知(Indoor Scene Perception)/机器人(Robot)/定位(Grounding)三大子基准,方便针对性测评模型特定能力 。

图6 MMSI-Video-Bench数据构建与问题子类分布
实验与分析
主流模型视频级空间智能表现不佳
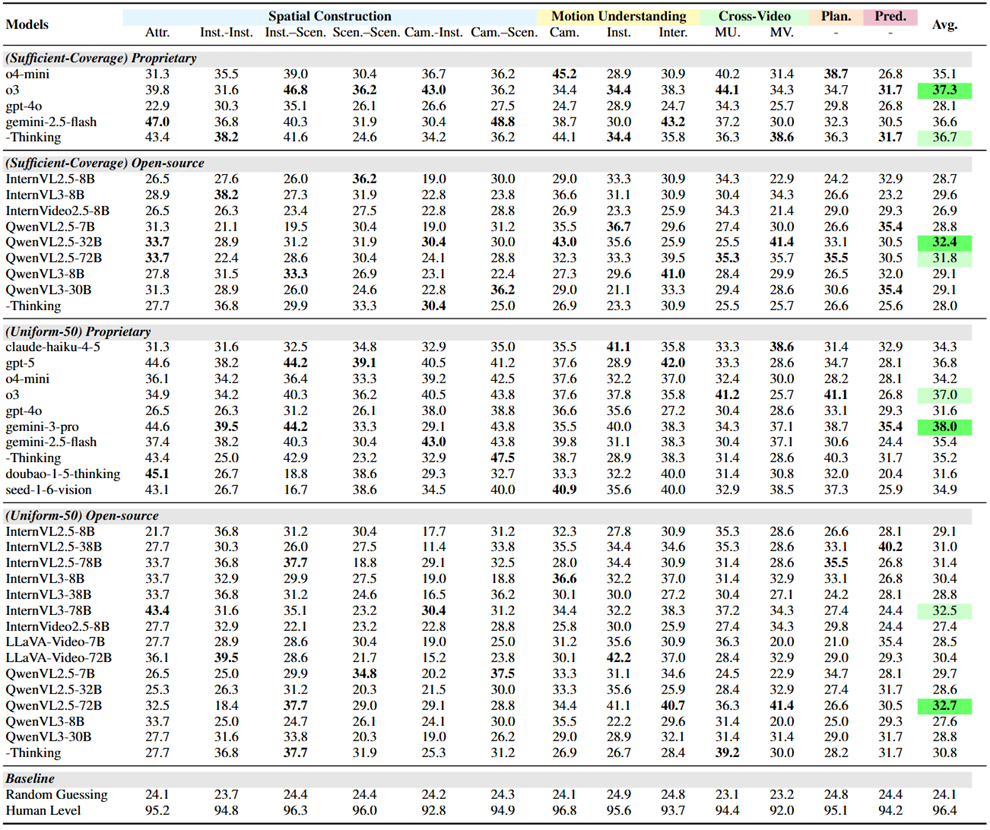
如表2所示,研究团队测评的25个主流模型 得分普遍偏低 :即便表现最好的模型Gemini 3 Pro也仅获得38.0分,与人类水平96.4分相比仍存在接近 60% 的显著差距 。
与已有空间智能基准的结论一致,实验结果再次表明当前模型在 空间构建能力 上仍有明显短板。更关键的是,得益于MMSI-Video-Bench 在任务设计上的全面覆盖,研究团队进一步发现:模型在 运动理解、规划、预测以及跨视频推理 等能力上同样存在明显瓶颈。其中, 预测(Prediction) 是最具挑战性的主任务,而在更细分的问题子类上, 相机–实体空间关系 是最困难的一类问题。
此外,研究团队还对一些 专门进行过空间微调 的模型进行了测评,发现这些模型的能力 也 未能有效泛化 到 MMSI-Video-Bench上。
表2 主流模型在MMSI-Video-Bench上的对比结果
错误分析:定位模型任务瓶颈
为进一步定位模型性能受限的关键原因,研究团队对模型的推理结果进行了系统化复盘,并将错误归纳为 五大类型 (见图7):
(1) 定位错误(Detailed Grounding Error) : 模型在精细视觉感知层面出现失效,常见表现包括目标遗漏混淆,或“时间点-事件”对应关系感知错误。
(2) 几何推理错误(Geometric Reasoning Error) : 模型在基于多帧信息的空间几何关系的构建推理上存在偏差,对于相对位置或距离关系(如前后左右、远近)出现错误推断 。
(3) 提示输入对齐错误(Prompt Alignment Error) : 模型未能将提示信息(如新的情境假设、新增条件或辅助图像)与视频信息正确结合进行推理。
(4) 潜在逻辑推断错误(Latent Logical Inference Error) : 模型在需要依赖隐含线索或常识知识的推理任务中失败,例如选择恰当的参考对象进行运动状态推理,正确利用空间关系的传递性,或是基于物理常识进行推理预测。
(5) ID匹配错误(ID Mapping Error) : 模型在跨帧过程中难以保持一致的实体身份跟踪。
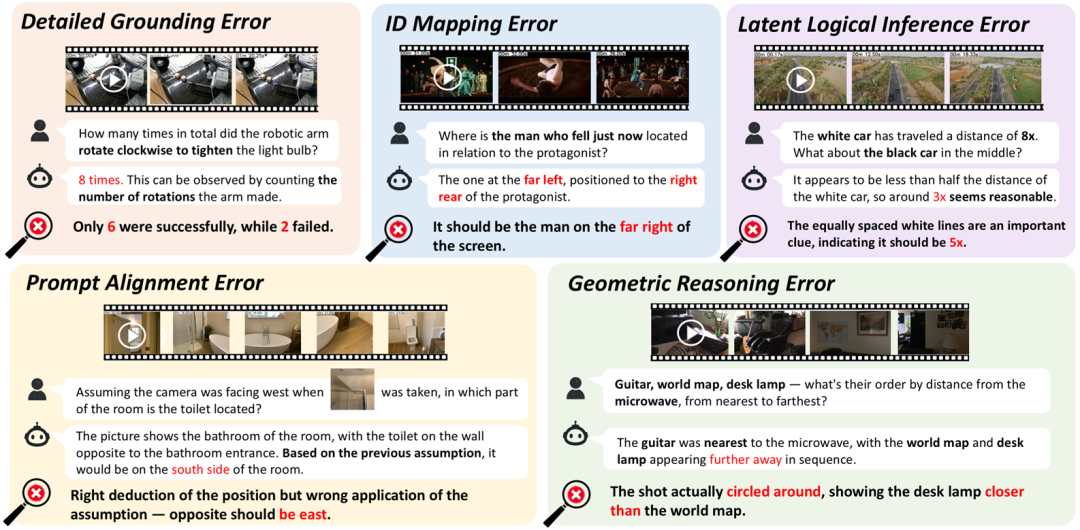
图7 MMSI-Video-Bench上模型的五大错误类型
研究团队选取Gemini-2.5-Flash、GPT-4o、O3、QwenVL2.5-72B四个具有代表性的模型进行了错误分析和统计,结果如图8所示。
总体来看, 几何推理错误 是出现最频繁、对性能影响也最大的错误类型,而进一步拆分到各任务后,可以看到更清晰的瓶颈来源:
-
空间构建任务 表现低,主要源于 几何推理能力 不足;
-
在 运动理解任务 中,模型很难在 快速、细微或长时间跨度的运动 中保持精确定位;
-
对于 规划与预测任务 ,除了几何推理错误外,模型还经常 无法有效 正确 理解提示输入 ,并将其与视频信息进行有效的 联合推理 ;
-
跨视频推理任务 的失败主要源于 多目标跨视频定位的复杂性 ,以及模型难以利用 潜在线索 (例如持续锁定同一目标)来完成推理。
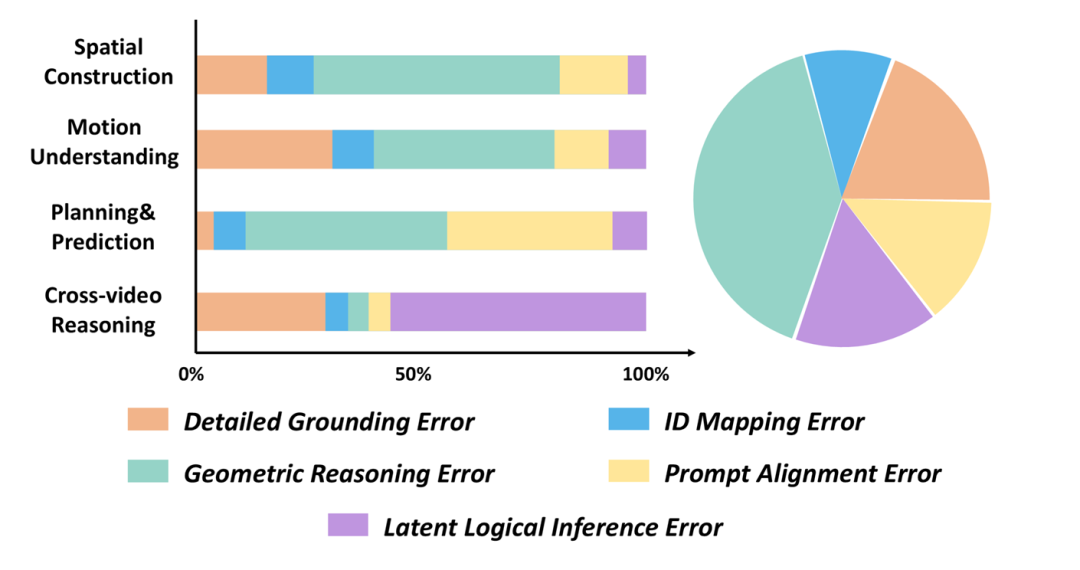
图8 模型错误分布统计(MMSI-Video-Bench,按任务拆分)
MMSI系列基准:从多图到视频的演变
从任务设计的角度来看,MMSI-Bench聚焦多图像关键帧层面,强调模型的局部空间理解与短时运动感知的能力,更像是空间智能的"基本门槛"。而MMSI-Video-Bench则是进一步迈向连续视频观测,要求模型在长时间信息流中提取关键线索,完成 全局空间布局建模与长时运动状态理解 。时间维度的引入与观测密度的提升,使MMSI-Video-Bench的任务类型更加丰富全面且接近真实世界,进而对模型能力提出了更高的要求(见图9,强推理模型在多图空间智能的领先明显,但在视频空间智能的领先有限)。
模型在这两个基准上表现出的几大主要错误模式(前四种错误类型)高度相似,由于时间维度的引入,模型在MMSI-Video-Bench上还存在ID匹配时的错误,观测密度的提升导致MMSI-Video-Bench上各类错误的表现形式更多样。其中,几何重建推理错误是两个基准共同的主要错误模式。总体而言,MMSI系列基准通过系统性的评测与错误分析,揭露了现阶段模型在空间智能方面的关键能力瓶颈,也为未来空间智能模型的技术演进指明了研究方向。

图9 模型在MMSI系列基准表现汇总
两个基准均已参与司南年度评测集评选活动,诚邀广大社区用户参与投票,也期待您留下专业评价与建议。
MMSI-Bench:
https://hub.opencompass.org.cn/benchmark-detail/2505.23764
MMSI视频底座:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









