 零基础入门Transformer学习路线
零基础入门Transformer学习路线





说到 Transformer,不少人第一反应是:高深、数学多、工程量大。的确,它涉及注意力机制、多头结构、位置编码等概念,但它的核心思想并不复杂,只要方法得当、学习路径清晰,即使是零基础,也能逐步从理解原理到亲手实现小模型。
下面是一份专为零基础设计的入门路线图,既有原理梳理,也有实战建议,循序渐进,让你把 Transformer 真正学“明白、学通透”。
✅ 零基础学 Transformer 的入门路线
🔹 1. 打好基础:Python + 数学 + 深度学习
Transformer 属于深度学习领域,零基础学之前,建议先补三块基石:
| 模块 | 内容 | 推荐时间 |
|---|---|---|
| Python 基础 | 变量、循环、函数、类 | 1~2 周 |
| Numpy / Tensor | 数组操作、矩阵乘法 | 1 周 |
| 深度学习原理 | 神经网络、反向传播、CNN/RNN 理解 | 2~3 周 |
🧩 资源建议:
-
B站目前讲的最好的【Transformer教程】20分钟让初中生全面理解Transformer,建议收藏!——人工智能/深度学习/大模型_哔哩哔哩_bilibili -
《DeepLizard PyTorch 系列》(YouTube)
免费分享一套人工智能+大模型入门学习资料给大家,如果想自学,这套资料很全面!
关注公众号【AI技术星球】发暗号【321C】即可获取!
【人工智能自学路线图(图内推荐资源可点击内附链接直达学习)】
【AI入门必读书籍-花书、西瓜书、动手学深度学习等等...】
【机器学习经典算法视频教程+课件源码、机器学习实战项目】
【深度学习与神经网络入门教程】
【计算机视觉+NLP入门教程及经典项目实战源码】
【大模型入门自学资料包】
【学术论文写作攻略工具】
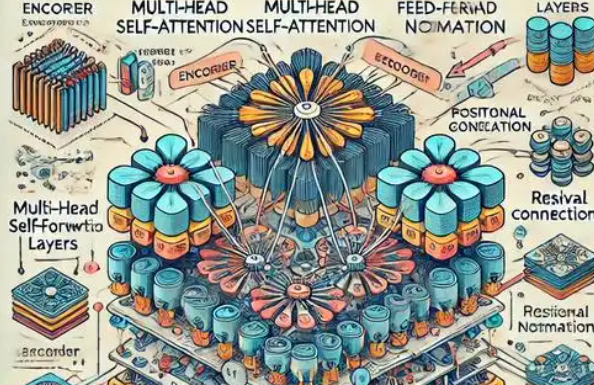
🔹 2. Transformer 核心思想入门
当你有了基础,可以开始理解 Transformer 的设计动机和结构组成。
Transformer 是用来处理序列的模型,其亮点是引入了“注意力机制”,可以让模型关注序列中的不同位置,避免了 RNN 的“串行”问题。
Transformer 架构由以下几部分构成:
| 模块 | 说明 |
|---|---|
| 词嵌入 Embedding | 把离散单词转为向量 |
| 位置编码 Positional Encoding | 弥补模型“顺序感”的缺失 |
| 多头注意力 Multi-Head Attention | 模拟“多个注意力通道”,可并行处理上下文信息 |
| 前馈网络 Feed-Forward | 类似普通神经网络处理 |
| 残差连接与归一化 | 保证深层网络稳定训练 |
| 编码器 & 解码器结构 | Encoder 提取输入特征,Decoder 生成输出(如翻译) |
🧩 推荐学习资源:
-
动画网站:https://jalammar.github.io/illustrated-transformer/
-
中文图解文章:知乎「Transformer 原理图解」
🔹 3. 实战初体验:用 PyTorch 训练 Mini-Transformer
不需要一上来就自己造模型,推荐你用 PyTorch 的现成模块构建一个小型 Transformer:
import torch.nn as nn
transformer = nn.Transformer(
d_model=512,
nhead=8,
num_encoder_layers=6,
num_decoder_layers=6
)📌 推荐练习项目:
-
字符级翻译模型:英文字母转变成另一种表示形式
-
简单文本摘要:对一句话生成简短摘要(seq2seq)
-
Transformer 分类器:对文本进行情感分析(正面/负面)
🔹 4. 学习 HuggingFace Transformers 框架
HuggingFace 是目前最受欢迎的 Transformer 开源库,可以让你快速加载并使用预训练模型(如 BERT、GPT-2、T5):
pip install transformersfrom transformers import pipeline
classifier = pipeline("sentiment-analysis")
print(classifier("I love learning Transformers!"))🔍 HuggingFace 提供了:
-
上百种预训练模型
-
快速微调接口
-
与 PyTorch 完美兼容
-
中文模型(如中文BERT、ChatGLM)也很丰富
🔹 5. 进阶阶段:自定义 Transformer 模型
当你理解了核心结构,可以尝试自己从头实现:
-
编写多头注意力模块
-
添加位置编码的实现
-
模拟完整 Encoder-Decoder 架构
-
可视化注意力权重图(看模型关注了哪些词)
这样做可以加深理解并为研究方向打基础。
🧠 总结学习路线
| 阶段 | 内容 | 目标 |
|---|---|---|
| 基础准备 | Python、Numpy、深度学习知识 | 学会操作张量与构建简单模型 |
| 理解原理 | Transformer 架构与模块功能 | 理解注意力机制与模型思路 |
| 代码实践 | PyTorch 实现、HuggingFace 项目 | 用代码还原原理并调试模型 |
| 项目驱动 | 文本分类、摘要、翻译等 | 运用 Transformer 解决实际任务 |
| 进阶挑战 | 自定义模块、论文复现 | 具备深入探索的能力 |
🚀 推荐学习资源
-
HuggingFace 官方教程:https://huggingface.co/learn
-
B站搜索「Transformer 动画讲解」「BERT 中文微调」
-
《The Annotated Transformer》(附代码解析)
-
书籍推荐:《自然语言处理入门与实践》《Transformer详解》

















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









