




神经网络算法的训练阶段是其核心环节,目的是通过不断调整网络参数,让模型能够从训练数据中学习到有效的模式和规律,从而具备对未知数据进行准确预测或分类的能力。
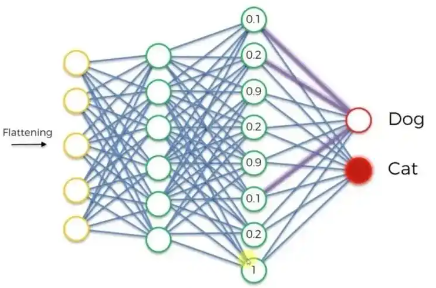
训练阶段的详细流程和关键要点:
数据准备与预处理
- 数据收集与清洗
- 收集数据:根据具体任务收集相关数据集。例如在图像分类任务中,收集包含不同类别(如动物、植物、交通工具等)的图像数据;在自然语言处理任务中,收集大量的文本数据,如新闻文章、评论等。
- 数据清洗:去除数据中的噪声、缺失值和异常值。例如,在处理房价数据时,若发现某个房屋面积数据为负数或远超正常范围,需进行修正或剔除;在文本数据中,去除乱码、特殊符号等无关信息。
- 数据划分
- 划分原则:将数据集划分为训练集、验证集和测试集。训练集用于模型的参数更新;验证集用于在训练过程中评估模型的性能,调整超参数(如学习率、网络层数、神经元数量等);测试集则用于最终评估模型在未见过的数据上的泛化能力。
- 常见比例:常见的划分比例为训练集占70% - 80%,验证集占10% - 15%,测试集占10% - 15%。但具体比例可根据数据量和任务需求进行调整。
免费分享一套人工智能入门学习资料给大家,如果你想自学,这套资料非常全面!
关注公众号【AI技术星球】发暗号【321C】即可获取!
【人工智能自学路线图(图内推荐资源可点击内附链接直达学习)】
【AI入门必读书籍-花书、西瓜书、动手学深度学习等等...】
【机器学习经典算法视频教程+课件源码、机器学习实战项目】
【深度学习与神经网络入门教程】
【计算机视觉+NLP经典项目实战源码】
【大模型入门自学资料包】
【学术论文写作攻略工具】
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









