



AI圈又炸了!
11月底,阿里巴巴通义实验室突然发布了一款名为Z-Image-Turbo的图像生成模型。乍一看,这似乎又是一个"平平无奇"的新模型——直到你看到这组数据:仅用61.5亿参数,在多项评测中表现优于部分200亿参数模型;生成一张512×512的图像,约耗时0.8秒;更引人注意的是,它的中文文字渲染准确率达0.988,在该领域表现突出。
在AI模型"越大越强"的军备竞赛中,Z-Image-Turbo用实际表现证明:小而美的模型,也能跑得又快又稳。它就像一辆极致调校的小钢炮,在一众"大排量油老虎"中脱颖而出,用更低的成本、更快的速度,交出了眼前一亮的答卷。
Z-Image-Turbo是什么?
先来拆解一下这个名字。“Z”代表“造相”(图像创造),“Turbo”表示经过蒸馏优化的高速版本。整个模型走的是“小而精”路线:只用61.5亿参数(相当于竞品Qwen-Image的1/3),却在多个基准测试中表现不俗。
它的三大核心亮点包括:
- 参数效率高
30层Transformer,推理只需8步(传统模型需100+步),Elo评分在开源模型中位列前茅(1025分)。
- 推理速度优异
生成512×512像素图像约需0.8秒,在消费级GPU(RTX 4090)上就能流畅运行,峰值显存仅16GB。
- 中文文字渲染突出
这是尤为引人注意的地方——在英文文字准确率0.987的基础上,中文文字准确率达0.988,在中文场景下表现优异。
从训练成本看,Z-Image-Turbo总共消耗31.4万个H800 GPU小时(约63万美元),这个成本远低于同类大模型。更重要的是,它是完全开源的,意味着你可以在自己的电脑上部署,而不用担心API调用成本。
技术突破①:单流架构的设计哲学
你可能不知道,大多数图像生成模型都采用"双流架构"——文本信息和图像信息各走各的通道,最后再拼接起来。这就像两条平行的铁轨,虽然稳定,但效率不高。
Z-Image-Turbo采用的"单流架构"(S3-DiT)则完全不同:它把文本Token、视觉语义Token和图像VAE Token统统放在一个序列里,就像把所有乘客都装进一节车厢,一次性拉走。
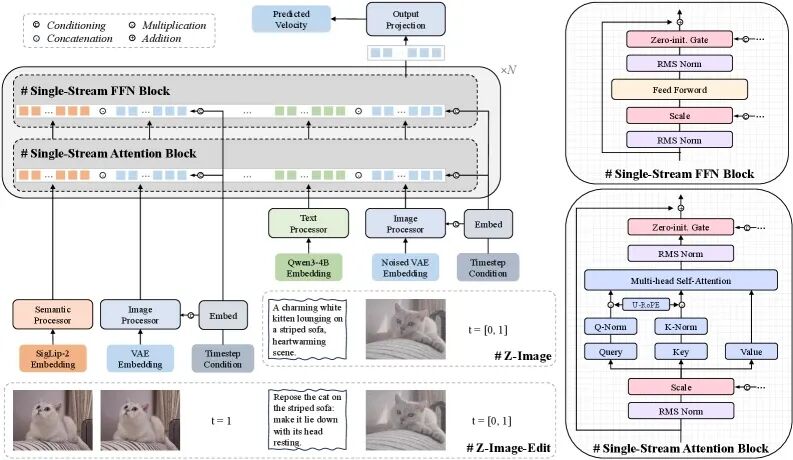
图1: S3-DiT单流架构设计。相比传统双流架构,单流设计将文本、语义和图像Token统一处理,显著提升了参数效率和训练稳定性
这种设计带来三大好处:参数效率更高,不需要分别为文本和图像维护两套注意力机制,同样的参数量能榨出更多性能。推理速度更快,单条数据流意味着计算路径更短,训练更稳定,GPU利用率更高。:统一的Token序列让模型更容易学习文本和图像之间的对应关系。
用个比喻来说,传统双流架构像是开两辆车分别运货,单流架构则是开一辆大货车一次性装完——显然后者更经济实惠。
技术突破②:解耦蒸馏的速度魔法
如果说单流架构是Z-Image的"骨架",那么"解耦分布匹配蒸馏"(Decoupled-DMD)就是它的"涡轮增压器"。
传统的模型蒸馏就像是"照葫芦画瓢"——让小模型模仿大模型的输出。但这种方法有个致命缺陷:推理步数减少时,图像质量会断崖式下跌,出现色偏、细节丢失等问题。
Z-Image团队的解决方案很巧妙:他们把蒸馏过程拆解成两个独立组件:
- CFG增强(CA)
:作为"引擎",负责推动模型快速前进
- 分布匹配(DM)
:作为"稳定器",确保生成质量不掉线

图2: 解耦蒸馏效果对比。从左到右依次为原始SFT模型、标准DMD、解耦DMD和最终的Z-Image-Turbo。
可以明显看到解耦方案成功解决了色偏和细节退化问题
这种解耦设计让Z-Image-Turbo在仅用8步推理的情况下,就能达到传统模型100步的效果。这就好比F1赛车的换挡逻辑优化——同样的发动机,通过精细调校就能跑出更快的圈速。
更进一步,团队还引入了DMDR技术(DMD+强化学习),通过奖励模型进一步优化语义对齐和美学质量。RL释放创造力,DMD保证稳定性——这种"油门+刹车"的组合拳,让模型既快又稳。
性能对比:小参数如何打败大模型
数据最有说服力。我们来看看Z-Image-Turbo在实战中的表现:
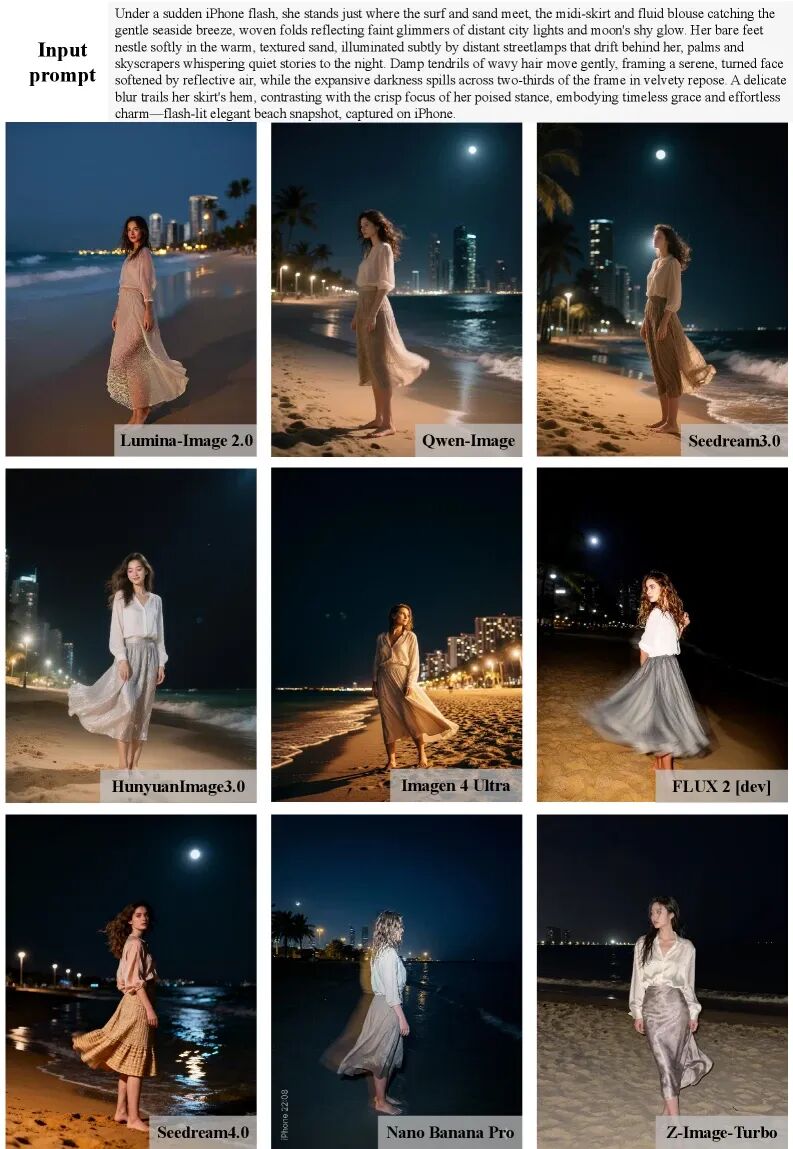
图3: Z-Image-Turbo与8款顶级竞品的生成质量对比(沙滩场景)。尽管参数量最小,Z-Image-Turbo在光影细节、人物皮肤质感等方面表现出色
从上图可以看到,Z-Image-Turbo在与Lumina-Image 2.0、Qwen-Image、Seedream 4.0、Nano Banana Pro等一众强敌的PK中,丝毫不落下风。
关键性能指标对比:
| 模型 | 参数量 | FID↓ | CLIP↑ | Elo评分 |
| Qwen-Image | 20B | 4.5 | 0.8017 | 1008 |
| Z-Image-Turbo | 6.15B | 3.5 | 0.8048 | 1025 |
| Nano Banana Pro | 未知 | 2.8 | 0.8100 | 1048 |
看到这组数据,你会发现一个惊人的事实:Z-Image-Turbo用不到Qwen-Image 1/3的参数,跑出了更好的成绩。FID分数越低越好(它降了22%),CLIP分数越高越好(它还提升了0.4%),Elo评分更是甩开17分。
这意味着什么?在显卡价格动辄上万的今天,更小的模型=更低的部署成本+更快的推理速度。一台RTX 4090就能跑通Z-Image-Turbo,而20B参数的竞品可能需要A100才能流畅运行。
杀手锏:中文文字渲染的逆袭
如果你用过Midjourney或DALL-E生成带中文文字的海报,就会知道那个痛点:生成的汉字不是笔画错乱,就是直接变成乱码。这是因为国外模型主要在英文数据上训练,对中文的字形结构"水土不服"。

图4: Z-Image的双语文字渲染能力展示。从海报、书籍封面到宣传单,中英文混排场景下文字也清晰可读,准确率高达0.988
Z-Image-Turbo在这方面做出了关键突破:
英文文字准确率: 0.987(已达业界顶尖水平)中文文字准确率: 0.988(甚至略高于英文!)综合文字准确率: 0.8671(在CVTG-2K基准测试中)
这个0.988是什么概念?意味着100个汉字中,只有不到2个会出错。而国外竞品FLUX.2的中文准确率只有约0.83,Z-Image足足领先18%。
这对国内创作者意味着什么?你终于可以用AI生成带中文文字的:
-
电商产品主图("新品上市""限时抢购")
-
公众号封面图(标题文字清晰可读)
-
活动宣传海报(中英文混排也不怕)
-
社交媒体配图(带文字的Meme、表情包)
这是国产AI在垂直领域的一次出色表现。

图5: Z-Image生成的多样化高质量图像样例。从人物肖像、体育运动到建筑景观、动物特写,18张样本展示了模型的全面生成能力
应用场景举例:
内容创作者: 公众号封面、小红书配图、B站封面
电商运营: 产品主图、营销素材、活动海报
设计师: 初期概念草图、视觉灵感参考
企业用户: 内部文档配图、演示资料美化
尤其是对于需要中文文字渲染的场景,Z-Image-Turbo是当前可用的优质选项之一。
技术民主化的新里程碑
Z-Image-Turbo的意义不仅仅是又一个"更快的图像生成模型"。它用实际行动证明了一件事:在AI"军备竞赛"的今天,"小而美"也是一条可行的路。
从61.5亿参数打败200亿参数对手,到0.8秒生成一张图,再到中文文字渲染的完美支持——这些突破背后的逻辑是:技术不应该只服务于大公司和顶尖实验室,而应该让更多普通人能用得起、用得好。
当一台RTX 4090就能跑通Z-Image-Turbo,当中文创作者不再需要忍受"文字乱码"的痛苦,当开源社区可以自由魔改和优化模型——AI技术才真正走向了民主化。
如果你也关注AIGC领域的最新发展,不妨关注阿里巴巴通义实验室的后续动作。据说他们还在开发图像编辑版本(Z-Image-Edit)和视频生成功能。如果这些功能也能延续"小而美"的设计哲学,那将是国产AI的又一次重大突破。
社区地址
OpenCSG社区:https://opencsg.com/models/AIWizards/Z-Image-Turbo
hf社区:https://huggingface.co/Tongyi-MAI/Z-Image-Turbo
关于 OpenCSG
OpenCSG 是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论,由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。
更多推荐





















 9702
9702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









