 微软Phi-3.5系列AI模型
微软Phi-3.5系列AI模型




前沿科技速递🚀
在人工智能领域,微软从未停止过创新的步伐。尽管与OpenAI的合作为微软带来了显著的成功,但他们显然不满足于此。近日,微软再次在AI领域引发关注,正式发布了三款全新的Phi-3.5系列AI模型。这些模型不仅在多语言和多模态任务中表现优异,还在多个基准测试中超越了当前市面上最先进的AI模型,如谷歌的Gemini 1.5 Flash和OpenAI的GPT-4o。
来源:传神社区
01 Phi-3.5系列模型简介
Phi-3.5 Mini Instruct:轻量级推理的佼佼者
Phi-3.5 Mini Instruct是一款专为计算资源受限环境设计的轻量级模型,拥有38亿参数,支持128k的Token上下文长度。这款模型特别适合代码生成、数学问题求解和逻辑推理等需要强大推理能力的任务。尽管体积小巧,Phi-3.5 Mini Instruct在多语言和多轮对话任务中表现出色,甚至在长上下文代码理解的RepoQA基准测试中超越了其他类似大小的模型,如Llama-3.1-8B-instruct和Mistral-7B-instruct。
Phi-3.5 MoE:微软的“专家混合”模型
Phi-3.5 MoE(专家混合)模型是微软首次推出的此类模型,它将多种不同类型的模型整合在一个框架中,每个模型专门处理不同的任务。拥有420亿活跃参数的Phi-3.5 MoE模型在代码、数学和多语言理解方面表现出色,通常在基准测试中超越了更大的模型,如在5-shot MMLU基准测试中,这款模型在STEM、人文学科、社会科学等多个学科的不同层次上超越了GPT-4o mini。
Phi-3.5 Vision Instruct:先进的多模态推理模型
Phi-3.5 Vision Instruct模型整合了文本和图像处理功能,特别适用于图像理解、光学字符识别、图表和表格理解以及视频总结等任务。该模型通过高质量、推理密集的数据进行训练,支持128k的Token上下文长度,使其能够处理复杂的多帧视觉任务。

02 性能表现:超越市场领先者
Phi-3.5系列模型的性能在发布后迅速引起了行业内外的广泛关注和讨论。在多个独立的第三方基准测试中,Phi-3.5系列模型展现出了与市场上最先进的模型媲美的性能,甚至在某些测试中超越了包括谷歌的Gemini 1.5 Flash、Meta的Llama 3.1以及OpenAI的GPT-4o等知名AI产品。这一系列模型凭借其卓越的推理能力、多语言处理和多模态理解能力,成功在激烈的竞争中脱颖而出。
例如,在多语言MMLU基准测试中,Phi-3.5 Mini Instruct模型在多个语言任务中都取得了令人瞩目的成绩,特别是在处理复杂多语言任务时表现出了超强的适应能力。相比之下,其他更大参数的模型,如Llama 3.1-8B Instruct和Mistral-7B Instruct,在处理类似任务时往往需要更多的计算资源和时间,而Phi-3.5系列则以其精简的设计和高效的架构取得了更高的性价比。
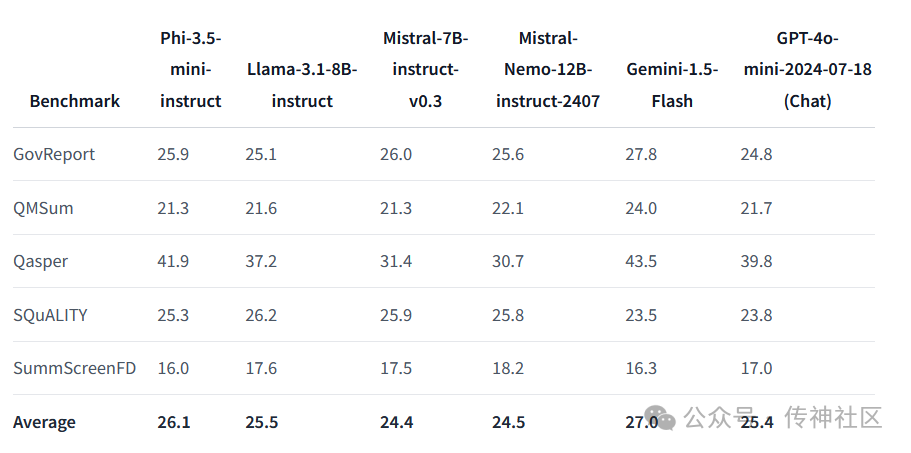
此外,Phi-3.5 MoE模型以其“专家混合”的独特架构,在应对高强度推理任务方面表现尤为出色。在多个高难度的推理基准测试中,它的表现甚至超越了GPT-4o mini等知名模型。值得一提的是,该模型在STEM、人文学科和社会科学等多个学科的MMLU测试中,均取得了超过预期的优异成绩,为未来多学科领域的AI应用提供了新的可能性。
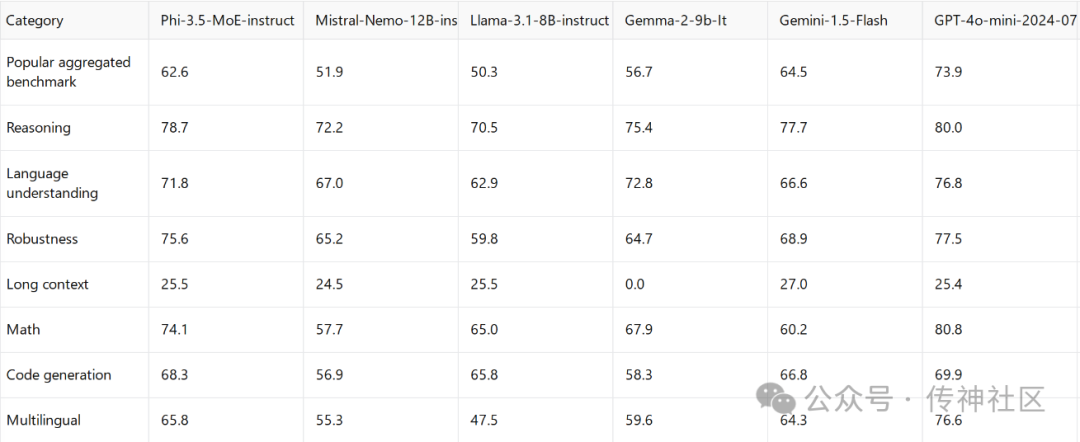
Phi-3.5 Vision Instruct模型在视觉任务中表现尤为突出。与传统模型相比,它不仅能够高效处理复杂的多帧视觉任务,还在图像理解、光学字符识别(OCR)和视频总结等任务中展现出更高的精度和效率。
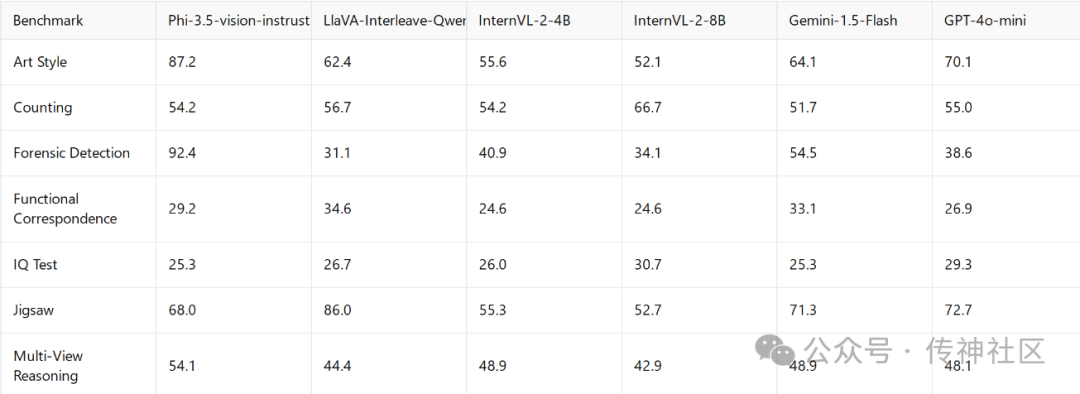
在具体的基准测试中,Phi-3.5 Vision Instruct模型的表现甚至超越了一些拥有更大参数量的知名模型,如Gemini 1.5 Flash和GPT-4o。在诸如艺术风格识别和法证检测等任务中,Phi-3.5 Vision Instruct的表现明显优于LlaVA-Interleave-Qwen-7B和InternVL-2系列等竞争对手,而在复杂的多视图推理任务中,它也展示了出色的能力。这种卓越的性能表明,尽管Phi-3.5系列模型在参数量上更为精简,但在推理速度和资源利用效率上,远远优于其他同类模型。
03 典型示例
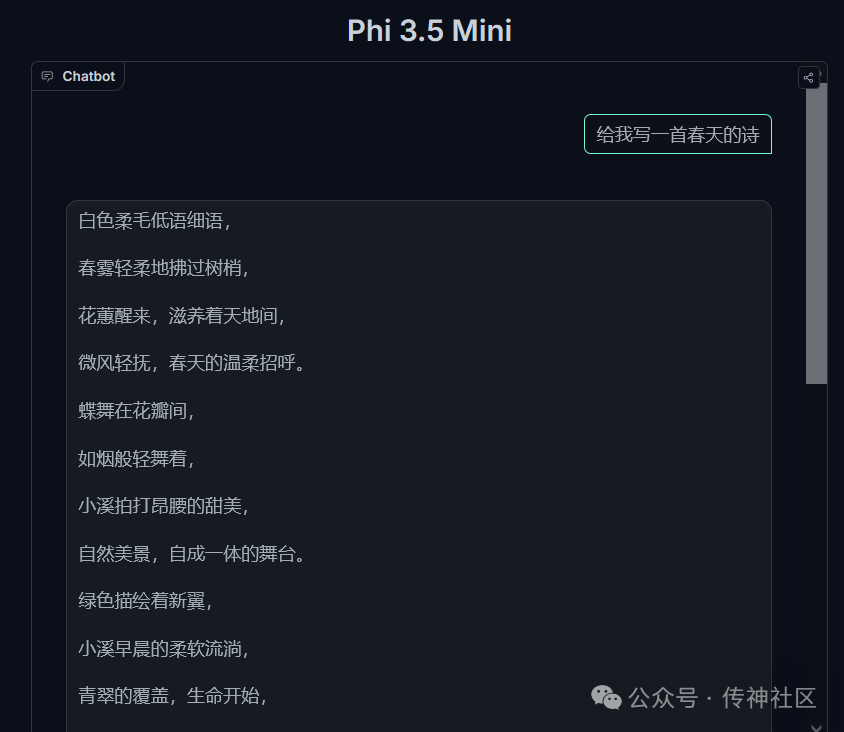
小编使用生成了一些示例,我们一起来看看吧!
Phi-3.5-mini-instruct:
Phi-3.5-vision-instruct:
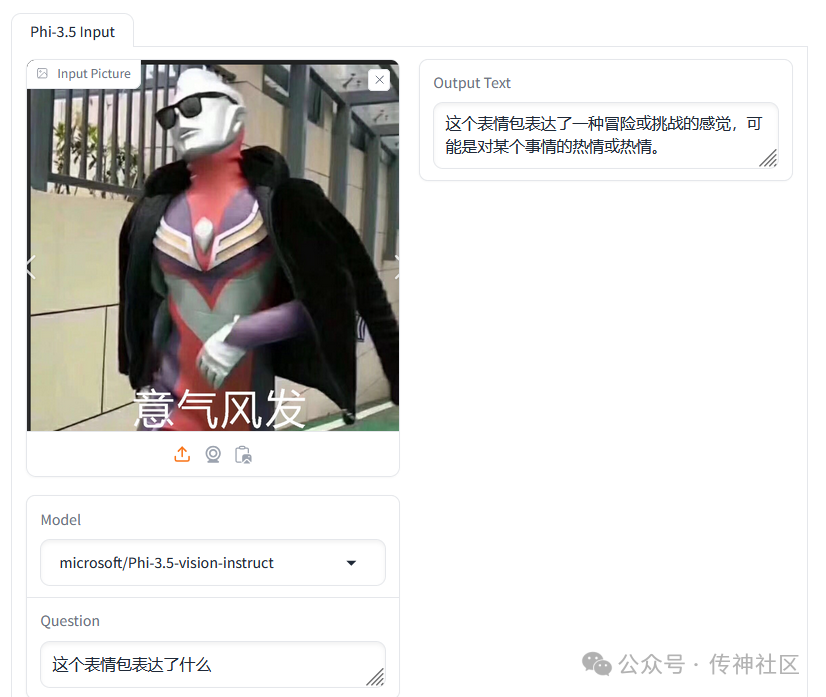
通过上面的实例可以看出,Phi-3.5系列模型无论是在语言表达还是图像识别与解读方面都是很不错的,感兴趣的话快来传神社区下载吧!
04 模型下载
传神社区:
Phi-3.5-mini-instruct:
https://opencsg.com/models/microsoft/Phi-3.5-mini-instruct
Phi-3.5-vision-instruct:
https://opencsg.com/models/microsoft/Phi-3.5-vision-instruct
欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https://github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区


















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









