



前沿科技速递🚀
上海人工智能实验室携手商汤科技,联合港中大与复旦,推出InternLM2.5系列大模型,引领智能科技新纪元!
卓越推理力:InternLM2.5,70亿参数基础模型,数学推理超群,力压Llama3、Gemma2-9B,MATH评测精准度飙升60%,直逼GPT-4 Turbo。
百万级上下文:支持1M tokens长文本,解锁120万汉字处理能力,LongBench领先,LMDeploy体验超长对话魅力,信息捕捉近乎完美。
强化工具集成:超越百网信息整合,Lagent即将揭秘,指令遵循、工具选择、智能反思,全方位提升工具使用效能。
Chat定制版:InternLM2.5-Chat,SFT+RLHF双重优化,指令精准、聊天流畅、功能强大,专为下游应用量身打造。
模型地址:https://opencsg.com/models/ShangHaiAILab/internlm2_5-7b
来源:传神社区
01 卓越推理能力
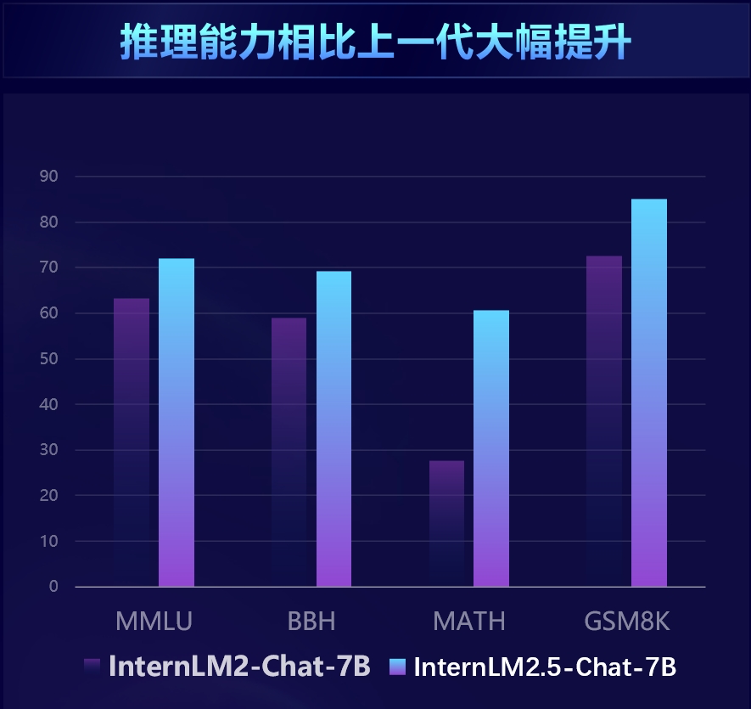
InternLM2.5 在数学推理方面取得了同量级模型中的最优精度,超越了 Llama3 和 Gemma2-9B。基于司南 OpenCompass 开源评测框架,InternLM2.5 在多个推理能力权威评测集上实现了显著性能提升,尤其在数学评测集 MATH 上达到了 60% 的准确率,与 GPT-4 Turbo 1106 版本相当,充分展示了其卓越的推理能力。
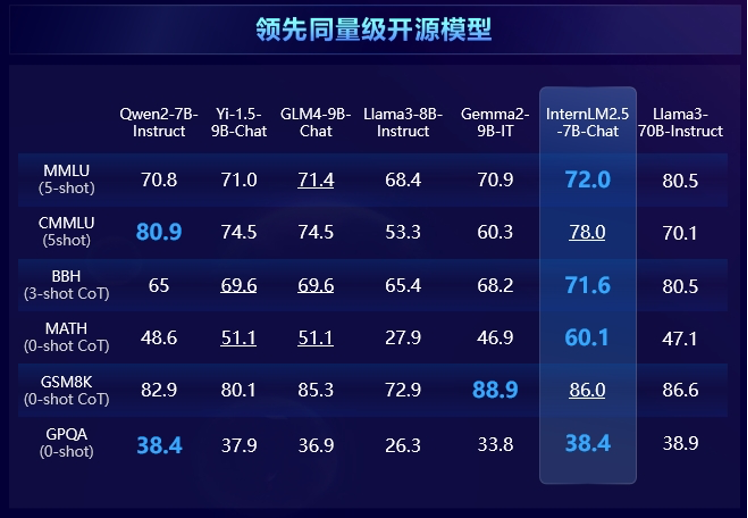
与国内外最新的主流开源模型相比,InternLM2.5在大部分推理评测集上综合领先于Llama3和Gemma2等同量级模型。
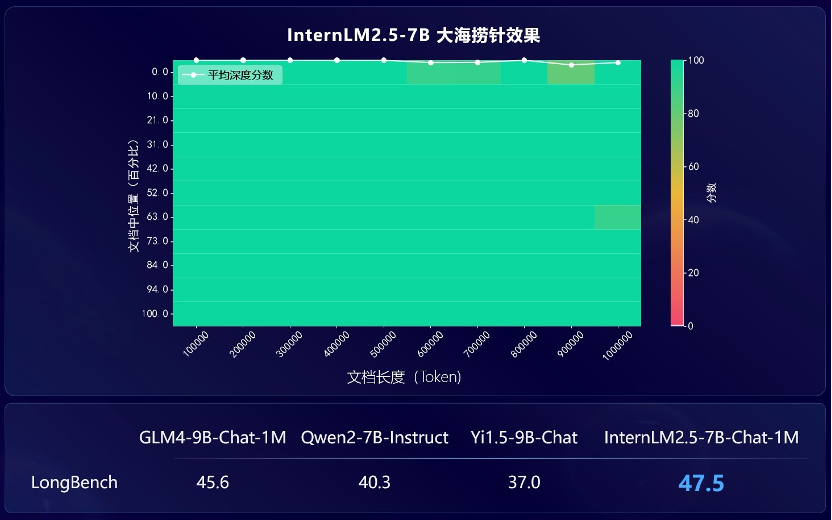
02 超长文本窗口
在需要处理长文档和复杂智能体交互的应用场景中,模型对上下文长度的支持提出了更高的要求。InternLM2.5 提出了解决方案,将上下文长度从上一代模型 InternLM2 的 200K 提升到了 1M(约合 120 万汉字),进一步释放了模型在超长文本应用中的潜力。
在模型的预训练过程中,从自然语料中筛选出 256K Token 长度的文本,并通过合成数据进行补充,以避免语料类型过于单一而导致的域偏移,使得模型在扩展上下文的同时尽量保留其能力。
采用业界流行的“大海捞针”评估方法,InternLM2.5 在 1M token 范围内实现了几乎完美的信息召回,展示了其出色的长文处理能力。用户可以通过 LMDeploy 体验百万字超长上下文推理。
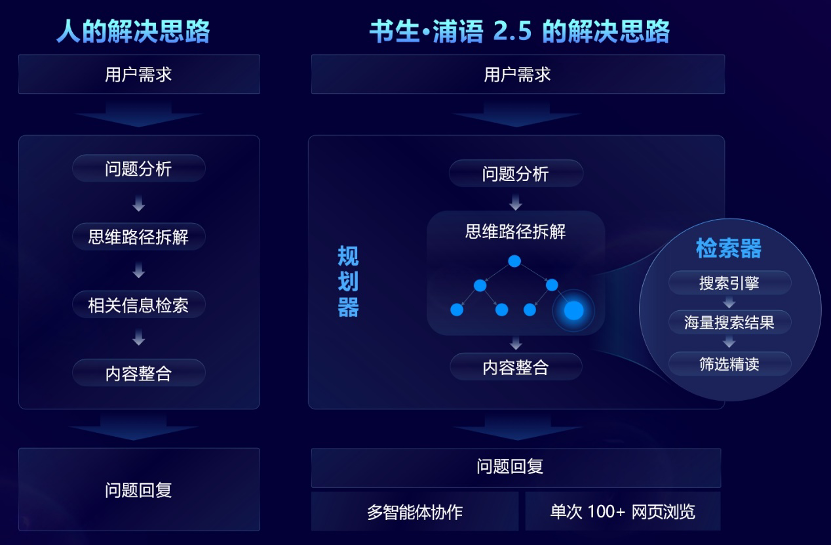
03 多智能体协作框架
针对需要大规模复杂信息搜索和整合的问题场景,书生·InternLM2.5研究团队创新性地提出了“规划器”模式,通过调动内部多智能体协作,在模拟“人类解决思路”的前提下,更高效准确地进行全网信息检索与整合。
联合团队创造性地研发了 MindSearch 多智能体框架,模拟人类思维过程,引入任务规划、任务拆解、大规模网页搜索和多源信息归纳总结等步骤。正如图所示,多人协作查找统一信息。规划器专注于任务的规划、拆解和信息归纳,采用图结构编程的方式进行规划,并根据任务状态进行动态拓展;搜索器负责发散式搜索并总结网络搜索结果,使整个框架能够基于上百个网页的信息进行筛选、浏览和整合。
04 上手实践
想要体验最前沿的多智能体协作技术吗?快来跟随我们一起上手实践书生·浦语2.5吧!想要进一步体验书生·浦语2.5模型的话快来传神社区下载吧!


欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https:// github.com/opencsg
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









