




不论是正则,xpath,bs4都是数据解析的工具,下面我大概写一下这三种爬取页面的基本的格式,直接上案例吧,一般用xpath比较多
urllib和requests
urllib和requests都是基于网络请求的模块
urllib无法进行UA伪装,所以现在大都用的requests,如果在不需要进行UA伪装即可爬取的页面,我们也可以使用urllib,它更简洁。
re正则
ex = "<li>.*?<a>(.*?)</a>.*?</li>"
list = re.findall(ex, page_text, re.S)
在ex里面可以定位a标签里面的内容,接着再findall查找全部
爬取页面图片的src
import re
import requests
url = 'http://www.521609.com/qingchunmeinv/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'
}
page_html = requests.get(url=url, headers=headers)
page_html.encoding = 'gb2312'
page_text = page_html.text
ex = '<li>.*?<img src="(.*?)" width=.*?</li>'
img_src_list = re.findall(ex, page_text, re.S)
for src in img_src_list:
print(src)
# 这里仅仅抓到了图片src的内容
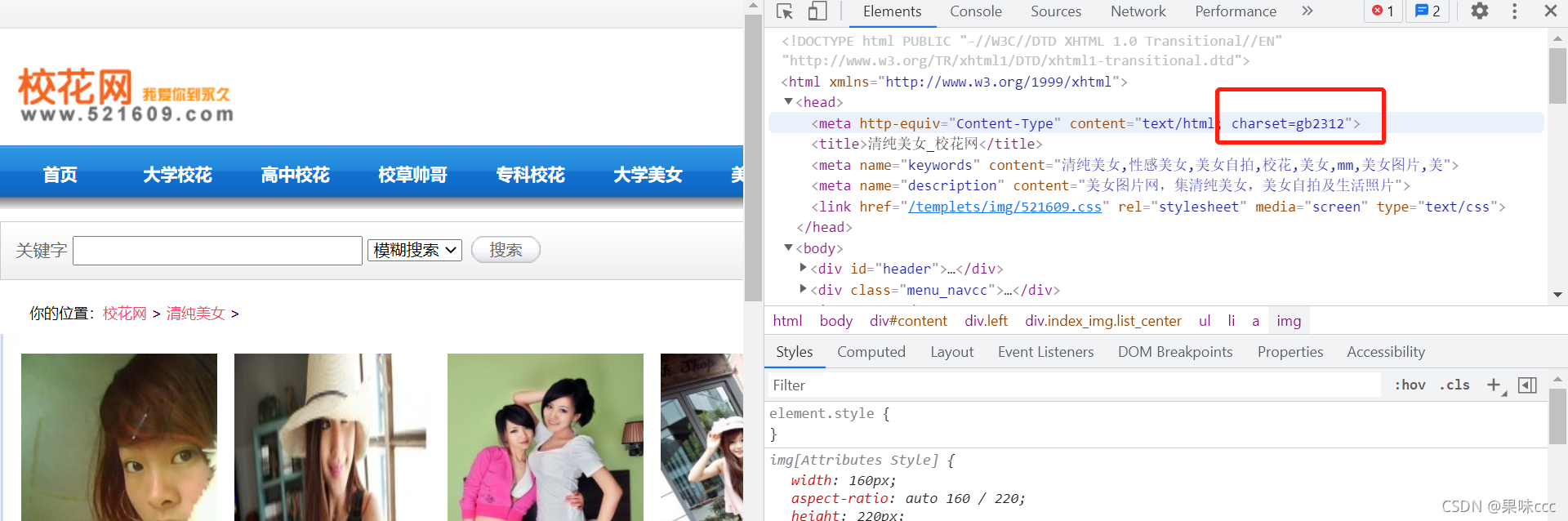
page_html.encoding是在获取网页源码出现编码异常时可以使用,具体编码方式可以在头部信息里面看到,比如拿校花网为例:
xpath
xpath要使用到lxml中的etree进行实例化
实例化etree对象,Html标签以树状的形式显示
- 页面数据:etree.Html(page_text)
- 本地文档:etree.parse(‘filename’)
xpath模糊匹配
- //div[contains(@id, “ng”)]:匹配id属性中包含ng的所有div标签
- //div[starts-with(@id,“ta”)]:匹配id中以ta为开头的所有div标签
取文本
- /text() 取该标签下的直系文本内容
- //text()取该标签下的所有文本内容
局部数据
将定位到的页面中的标签作为待解析的数据,再次使用xpath表达式解析待解析的数据
在局部解析的时候,xpath表达式中要使用 ./ 的操作。./ 表示的就是当前的局部数据
爬取站长之家的图片素材

import requests
from lxml import etree
index = ''
for i in range(1, 4):
if i>1:
index = f'_{i}' # 根据第二页的url来设置
url = f'https://sc.chinaz.com/tupian/rentiyishu{index}.html'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'
}
html = requests.get(url=url, headers=headers)
html.encoding = 'utf-8'
html = html.text
# print(html)
'''
<div class="box picblock col3" style="width:186px;height:311px">
<div>
<a target="_blank" href="//sc.chinaz.com/tupian/210914453743.htm" alt="极品诱人性感女人体艺术图片"><img src2="//scpic.chinaz.net/Files/pic/pic9/202109/apic35084_s.jpg" alt="极品诱人性感女人体艺术图片"></a>
</div>
<p><a target="_blank" href="//sc.chinaz.com/tupian/210914453743.htm" alt="极品诱人性感女人体艺术图片">极品诱人性感女人体艺术图片</a></p>
</div>
'''
doc = etree.HTML(html)
contents = doc.xpath('//a[@target="_blank"]/img')
for content in contents:
link = 'https:' + content.xpath('./@src2')[0]
name = content.xpath('./@alt')[0]
with open('photo_art/%s.jpg'%name, "wb") as f:
photo = requests.get(link, headers=headers).content
f.write(photo)
print(name, '保存完毕')
bs4
from bs4 import BeautifulSoup
soup = Beautiful(page_text, 'lxml')
- soup.p 获取到第一次出现的p标签
- soup.find(‘div’,class_ = ‘song’) 获取到第一次出现的class属性为song的div标签
- soup.findall(‘tag_name’, attrName =‘value’)
soup.select(‘选择器’):
- 类选择器:.
- ID选择器:#
- 层级选择:>表示一个层级,空格表示多个层级
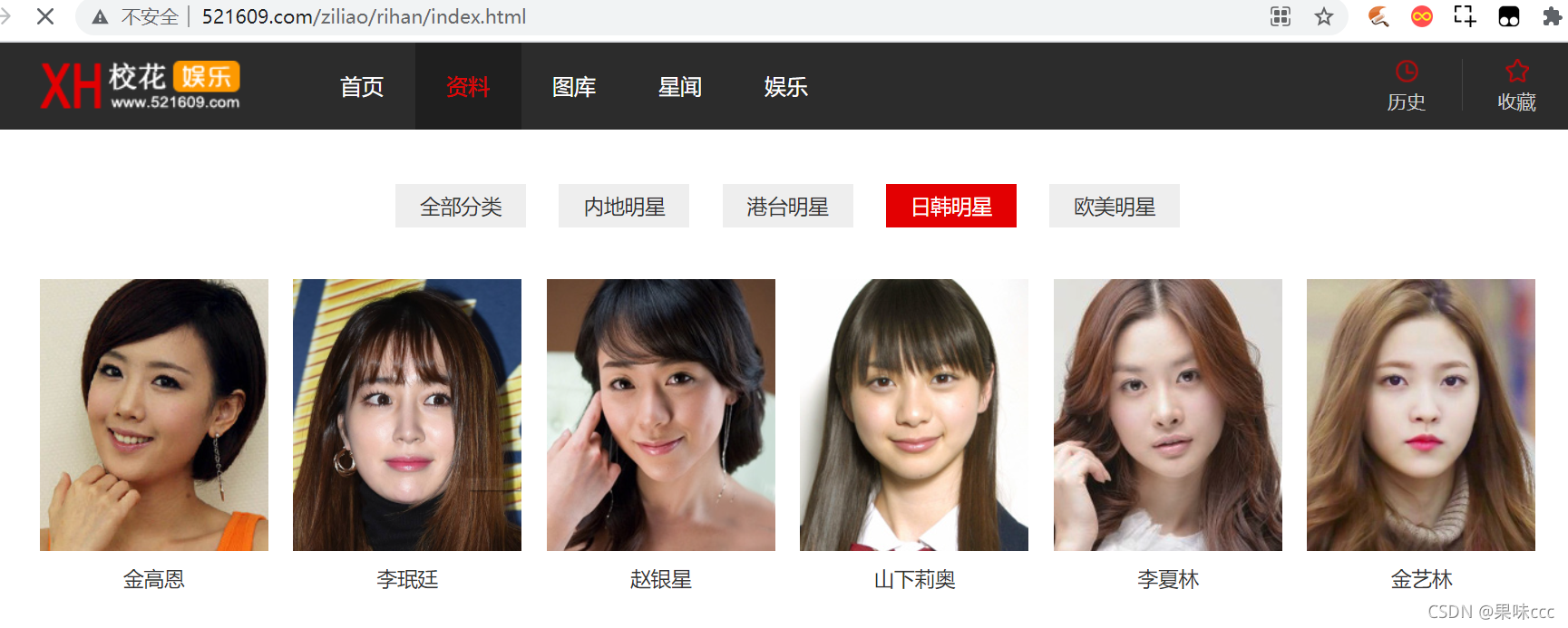
爬取校花娱乐网图片
爬取这个网站明星的图片以及名字作为保存项
import requests
from bs4 import BeautifulSoup
import urllib
for page_num in range(1,10):
url_end = ''
if page_num > 1:
url_end = f'_{page_num}'
url = 'http://www.521609.com/ziliao/rihan/index' + url_end +'.html'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'
}
page_text = requests.get(url=url, headers=headers)
page_text.encoding = 'utf-8'
page_text = page_text.text
# print(page_text)
soup = BeautifulSoup(page_text, 'lxml')
tag_list = soup.select(' li>a>span>img')
for tag in tag_list:
name, src = tag['alt'], 'http://www.521609.com/'+ tag['src']
addr = f'photo/{name}.jpg'
src_response = urllib.request.urlretrieve(src, addr)
print(name, src,"已下载")
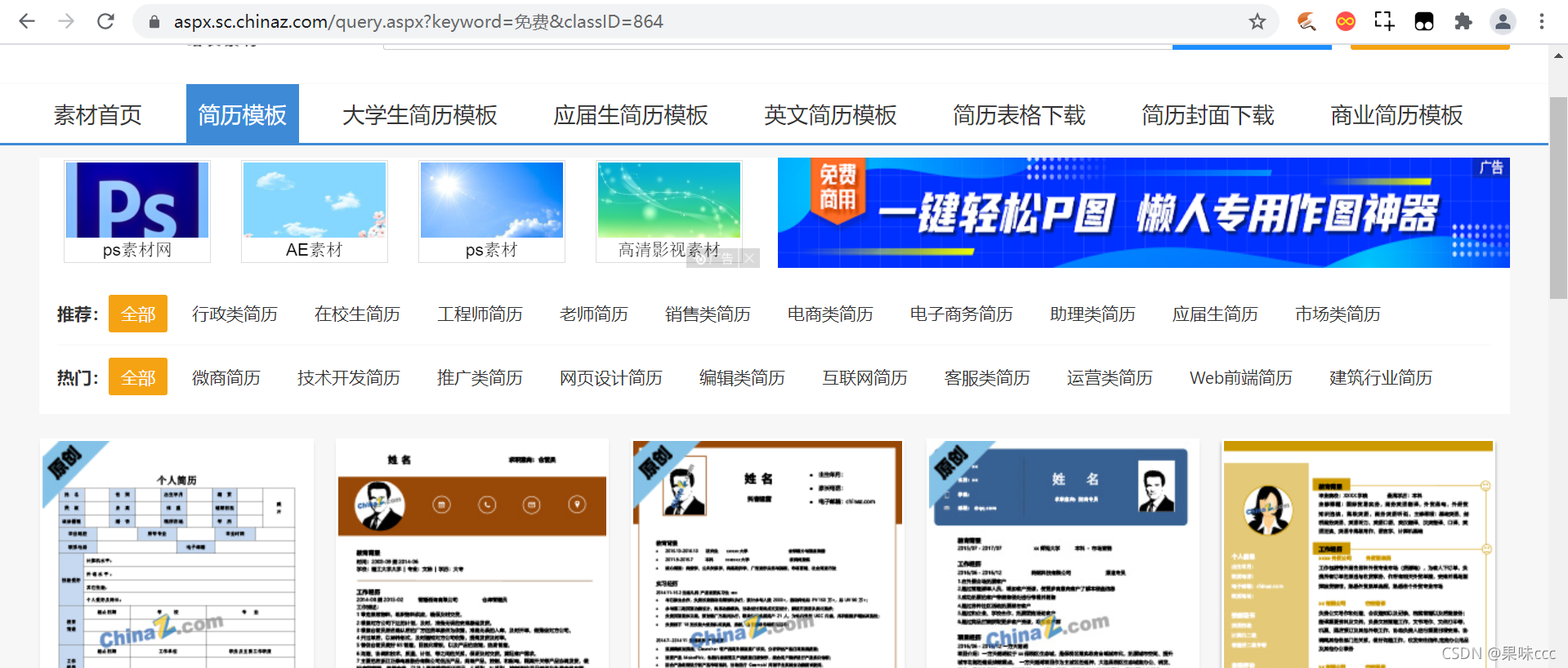
爬取免费简历
import requests
from bs4 import BeautifulSoup
import urllib
url = 'https://aspx.sc.chinaz.com/query.aspx?keyword=免费&classID=864'
for i in range(1, 6):
print(f'————第{i}页了————')
params = {
'page': str(i)
}
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'
}
html = requests.get(url=url, headers=headers, params=params).text
soup = BeautifulSoup(html, 'lxml')
a_list = soup.select('a.title_wl' )
for a in a_list:
detail_link = 'https:' + a['href']
# print(detail_link)
detail_html = requests.get(url = detail_link, headers=headers)
detail_html.encoding = 'utf-8'
detail_html = detail_html.text
# print(detail_html)
detail_soup = BeautifulSoup(detail_html, 'lxml')
download_rar = detail_soup.select('ul.clearfix>li>a')[1]['href']
title = detail_soup.h1.text
urllib.request.urlretrieve(download_rar, 'resume_rar/%s'%title)
print(title, "下载完毕")

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









