 淘宝商品销量接口解析
淘宝商品销量接口解析







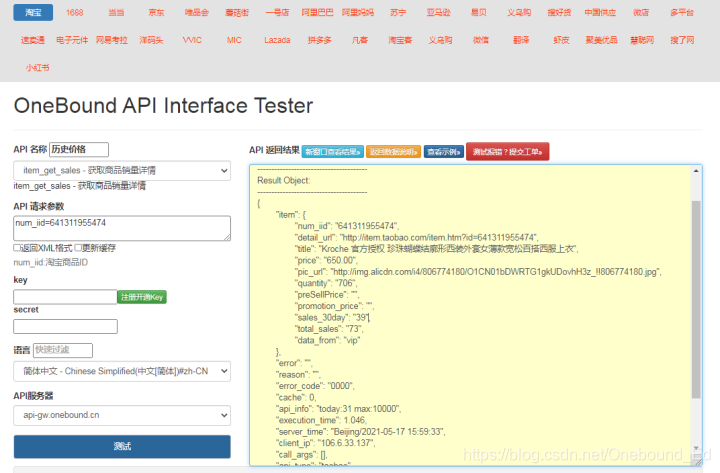
item_get_sales - 获取商品销量详情
获取淘宝商品精确销量接口
测试网址:点击注册测试
Result Object:
---------------------------------------
{
"item": {
"num_iid": "641311955474",
"detail_url": "http://item.taobao.com/item.htm?id=641311955474",
"title": "Kroche 官方授权 珍珠蝴蝶结廓形西装外套女薄款宽松百搭西服上衣",
"price": "650.00",
"pic_url": "http://img.alicdn.com/i4/806774180/O1CN01bDWRTG1gkUDovhH3z_!!806774180.jpg",
"quantity": "706",
"preSellPrice": "",
"promotion_price": "",
"sales_30day": "39",
"total_sales": "73",
"data_from": "vip"
},
"error": "",
"reason": "",
"error_code": "0000",
"cache": 0,
"api_info": "today:31 max:10000",
"execution_time": 1.046,
"server_time": "Beijing/2021-05-17 15:59:33",
"client_ip": "106.6.33.137",
"call_args": [],
"api_type": "taobao",
"translate_language": "zh-CN",
"translate_engine": "google_cn",
"server_memory": "5.34MB",
"request_id": "gw-4.60a222655cac7"
}

















 1739
1739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









