 Groq的张量流处理器:重新设计芯片架构以优化AI性能
Groq的张量流处理器:重新设计芯片架构以优化AI性能





 Groq是一家由Google TPU开发者创立的公司,致力于开发张量流处理器(TSP),以提供低延迟和高性能的AI解决方案。其独特的架构摒弃了传统CPU和GPU的复制品设计,转而采用单个处理器含数百个功能单元的模式。软件定义硬件的理念允许Groq通过预编排指令流减少硬件开销,提高性能。目前,Groq主要聚焦于云端推理市场,并计划扩展到自动驾驶和数据中心领域。Groq的TSP架构设计注重确定性,避免乱序执行和推测执行,以增强系统性能和响应时间的稳定性。
Groq是一家由Google TPU开发者创立的公司,致力于开发张量流处理器(TSP),以提供低延迟和高性能的AI解决方案。其独特的架构摒弃了传统CPU和GPU的复制品设计,转而采用单个处理器含数百个功能单元的模式。软件定义硬件的理念允许Groq通过预编排指令流减少硬件开销,提高性能。目前,Groq主要聚焦于云端推理市场,并计划扩展到自动驾驶和数据中心领域。Groq的TSP架构设计注重确定性,避免乱序执行和推测执行,以增强系统性能和响应时间的稳定性。

来源|Groq
翻译|贾川、程浩源、胡燕君
作为一家由多位前Google TPU开发者组建的芯片公司,Groq一经成立便备受关注。2016年底,曾领导研发Google张量处理单元(TPU,用于加速机器学习而定制的芯片)的Jonathon Ross离职创办了Groq,他们希望能为AI和HPC工作负载提供毫不妥协的低延迟和高性能。
不同于传统的CPU和GPU架构,Groq从头设计了一个张量流处理器 (TSP) 架构, 以加速人工智能、机器学习和高性能计算中的复杂工作负载。这个架构不是开发小型可编程内核并对其进行数百次复制,而是容纳一个具有数百个功能单元的单个处理器。

Groq的软件将深度学习模型编译成指令流,所有这些都是预编排的。他们用“软件定义硬件”的思路,将芯片中的控制和调度操作都交给软件完成,从而减少相应的硬件开销,压榨更多的性能。
目前,Groq主要面向云端推理领域。2021年4月,Groq宣布获得3亿美元新融资,用于开拓自动驾驶和数据中心行业市场。
近期,Groq首席架构师Dennis Abts完整介绍了Grop公司研发的软件定义横向扩展的张量流式多处理器(Tensor Streaming Processor,简称TSP)架构,主要包括搭建TSP架构的背景及构成,并说明了TSP的工作负载性能。
1
TSP的设计理念
Groq将软件定义(software-defined)的方法引入到多处理器中软硬件接口的设置问题。具体来说,静态和动态(static-dynamic)界面来区分什么应该在编译时做,什么应该在运行时执行;软硬件接口由通过指令集架构(ISA, instruction set architecture )来实现,仅仅向编译器暴露必要的体系结构内部状态。

我们将更多的控制权交给软件,并将那些应该硬件做的事交给芯片,而对于能在软件中完成的事情,则更多的放在软件堆栈中去做(在软件堆栈中这些任务也能完成得更好)。

面向确定性的设计(designing for determinism )要求我们在设计时作出选择,并对该设计理念一以贯之。我们必须确保硬件可以完全由编译器来控制,这不是要抽象掉硬件的细节,而是要显式地控制底层硬件。并且编译器能够清楚地了解硬件在任何给定周期内的工作情况。
传统的系统和CPU通常采用乱序执行(out-of-order execution)和推测执行(speculative execution)等技术在内存层次结构中暴露出附加的指令级并行(instruction level parallelism)和内存并发性(memory concurrency)。
而Groq则采取了不同方式,只在一个220兆字节的scratchpad内存中显式分配tensor,以便编译器知道tensor的位置以及它们如何在芯片上移动。编译器还可以利用大量的内存并发性,我们通过分区的全局地址空间来对此进行描述,并使其可以在整个系统中访问。

由于系统中的处理单元会达到数以万计(这些元素通常由异构组件组成,例如CPU、GPU、SmartNICs、FPGAs,所有这些组件都具有不同的故障特征和性能概况),系统层面的复杂性通常也会不断增加。
结果,系统的性能会发生变化,同时响应时间也会延长,这些变化也会相应地降低其他互联网应用程序的运行速度,所有需要机器各部分协作完成的事情最终都会受到这种延时的影响。
因此,我们尽量避免在系统层面出现这种资源浪费和滥用行为,同时引入新技术来帮助平衡系统负载,而无需在网络层面使用自适应路由和其他激进技术。
2
TSP微架构:软件定义硬件意味着什么
接下来让我们介绍微架构。首先是从传统的同构众核开始,每个核心都包含计算单元、整数单元、浮点单元、加载存储单元和网络接口。我们将这些功能单元分解并重新组织成SIMD功能单元,并将它们彼此相邻放置,便于控制并利用其空间局部性。这看起来与传统CPU有点不同,但执行方式却与传统CPU一样将较大的指令分解为微指令。同样,我们将深度学习操作分解为更小的微操作,并将它们作为一个整体执行,共同实现更大的目标。
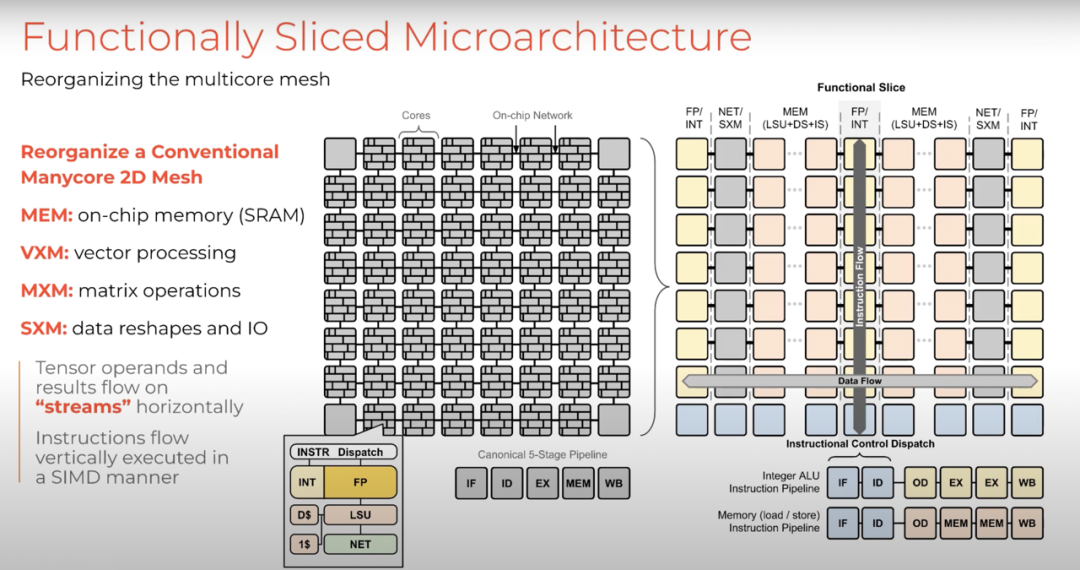
因此,如果我们只看芯片架构,会发现芯片是按照空间方向(spatial orientation)排列的,功能单元彼此相邻布置。它们通过在彼此之间传递操作数和结果来相
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















 928
928



 到【灌水乐园】发言
到【灌水乐园】发言







