




 本文深入探讨CUDA中的前缀和(Prefix Sum)问题,通过多个步骤逐步优化,从ScanThenFan到ReduceThenScan,利用Shared Memory、Warp Shuffle等技术,将时间从72390us降低至2467us,详细解析了CUDA并行计算的挑战和解决方案。
本文深入探讨CUDA中的前缀和(Prefix Sum)问题,通过多个步骤逐步优化,从ScanThenFan到ReduceThenScan,利用Shared Memory、Warp Shuffle等技术,将时间从72390us降低至2467us,详细解析了CUDA并行计算的挑战和解决方案。

撰文 | Will Zhang
在上一篇《CUDA高性能计算经典问题①:归约》中,我们讨论了CUDA中如何实现高效Reduction,这次来讨论下一个经典问题Prefix Sum(前缀和),也被称为Scan/Prefix Scan等。Scan 是诸如排序等重要问题的子问题,所以基本是进阶必学问题之一。
1
问题定义
首先我们不严谨地定义这个问题,输入一个数组input[n],计算新数组output[n], 使得对于任意元素output[i]都满足:
output[i] = input[0] + input[1] + ... input[i]
一个示例如下:

如果在CPU上我们可以简单地如下实现:
void PrefixSum(const int32_t* input, size_t n, int32_t* output) {
int32_t sum = 0;
for (size_t i = 0; i < n; ++i) {
sum += input[i];
output[i] = sum;
}
}问题来了,如何并行?而且是几千个线程和谐地并行?这个问题里还有个明显的依赖,每个元素的计算都依赖之前的值。所以第一次看到这个问题的同学可能会觉得,这怎么可能并行?
而更进一步地,如何用CUDA并行,Warp级别怎么并行,Shared Memory能装下数据的情况怎么并行,Shared Memory装不下的情况如何并行等等。
2
ScanThenFan
首先我们假设所有数据都可以存储到Global Memory中,因为更多的数据,核心逻辑也是类似的。
我们介绍的第一个方法称为ScanThenFan,也很符合直觉,如下:
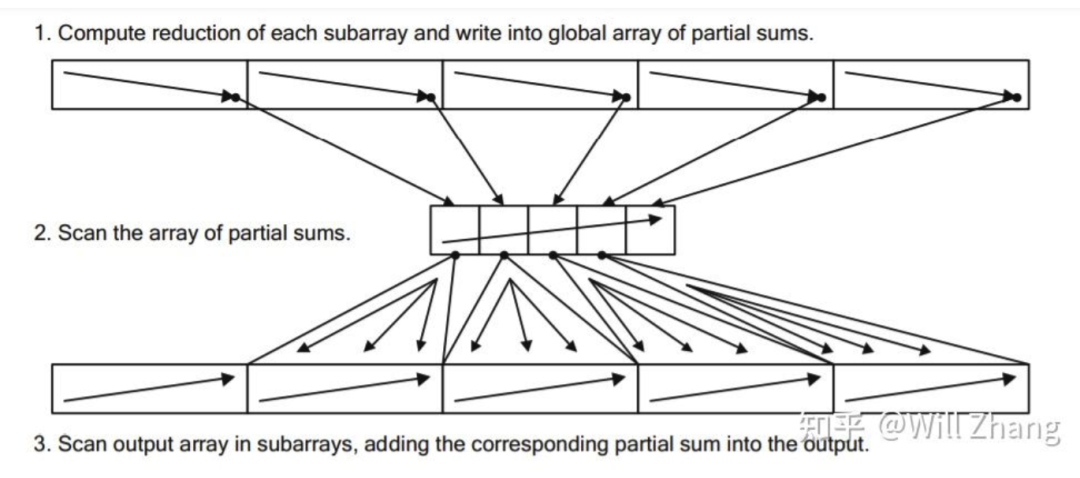
-
将存储在Global Memory中的数据分为多个Parts,每个Part由一个Thread Block单独做内部的Scan,并将该Part的内部Sum存储到Global Memory中的PartSum数组中
-
对这个PartSum数组做Scan,我们使用BaseSum标识这个Scan后的数组
-
每个Part的每个元素都加上对应的BaseSum
如下图
3
Baseline
我们先不关注Block内如何Scan,在Block内先使用简单的单个线程处理,得到如下代码:
__global__ void ScanAndWritePartSumKernel(const int32_t* input, int32_t* part, int32_t* output, size_t n,
size_t part_num) {
for (size_t part_i = blockIdx.x; part_i < part_num; part_i += gridDim.x) {
// this part process input[part_begin:part_end]
// store sum to part[part_i], output[part_begin:part_end]
size_t part_begin = part_i * blockDim.x;
size_t part_end = min((part_i + 1) * blockDim.x, n);
if (threadIdx.x == 0) { // naive implemention
int32_t acc = 0;
for (size_t i = part_begin; i < part_end; ++i) {
acc += input[i];
output[i] = acc;
}
part[part_i] = acc;
}
}
}
__global__ void ScanPartSumKernel(int32_t* part, size_t part_num) {
int32_t acc = 0;
for (size_t i = 0; i < part_num; ++i) {
acc += part[i];
part[i] = acc;
}
}
__global__ void AddBaseSumKernel(int32_t* part, int32_t* output, size_t n,
size_t part_num) {
for (size_t part_i = blockIdx.x; part_i < part_num; part_i += gridDim.x) {
if (part_i == 0) {
continue;
}
int32_t index = part_i * blockDim.x + threadIdx.x;
if (index < n) {
output[index] += part[part_i - 1];
}
}
}
// for i in range(n):
// output[i] = input[0] + input[1] + ... + input[i]
void ScanThenFan(const int32_t* input, int32_t* buffer, int32_t* output,
size_t n) {
size_t part_size = 1024; // tuned
size_t part_num = (n + part_size - 1) / part_size;
size_t block_num = std::min<size_t>(part_num, 128);
// use buffer[0:part_num] to save the metric of part
int32_t* part = buffer;
// after following step, part[i] = part_sum[i]
ScanAndWritePartSumKernel<<<block_num, part_size>>>(input, part, output, n,
part_num);
// after following step, part[i] = part_sum[0] + part_sum[1] + ... part_sum[i]
ScanPartSumKernel<<<1, 1>>>(part, part_num);
// make final result
AddBaseSumKernel<<<block_num, part_size>>>(part, output, n, part_num);
}现在的代码里很多朴素实现,但我们先完成一个大框架,得到此时的耗时72390us作为一个Baseline。
4
Shared Memory
接着,我们看ScanAndWritePartSumKernel函数,我们先做个简单的优化,将单个Part的数据先Load到Shared Memory中再做同样的简单逻辑,如下
__device__ void ScanBlock(int32_t* shm) {
if (threadIdx.x == 0) { // naive implemention
int32_t acc = 0;
for (size_t i = 0; i < blockDim.x; ++i) {
acc += shm[i];
shm[i] = acc;
}
}
__syncthreads();
}
__global__ void ScanAndWritePartSumKernel(const int32_t* input, int32_t* part,
int32_t* output, size_t n,
size_t part_num) {
extern __shared__ int32_t shm[];
for (size_t part_i = blockIdx.x; part_i < part_num; part_i += gridDim.x) {
// store this part input to shm
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 937
937



 到【灌水乐园】发言
到【灌水乐园】发言







