




 本文介绍了一位前端开发者如何通过分析网页和woff文件,解密小说网站上加密的月票数据,揭示了从加密字符到实际数值的转换过程。通过字体文件和编码映射,成功获取了每部小说的月票数。
本文介绍了一位前端开发者如何通过分析网页和woff文件,解密小说网站上加密的月票数据,揭示了从加密字符到实际数值的转换过程。通过字体文件和编码映射,成功获取了每部小说的月票数。
目录
获取woff文件url、加密关键数据、加密的月票数据、小说名
1、目标
- 我们要获取的内容就是每部小说的月票数
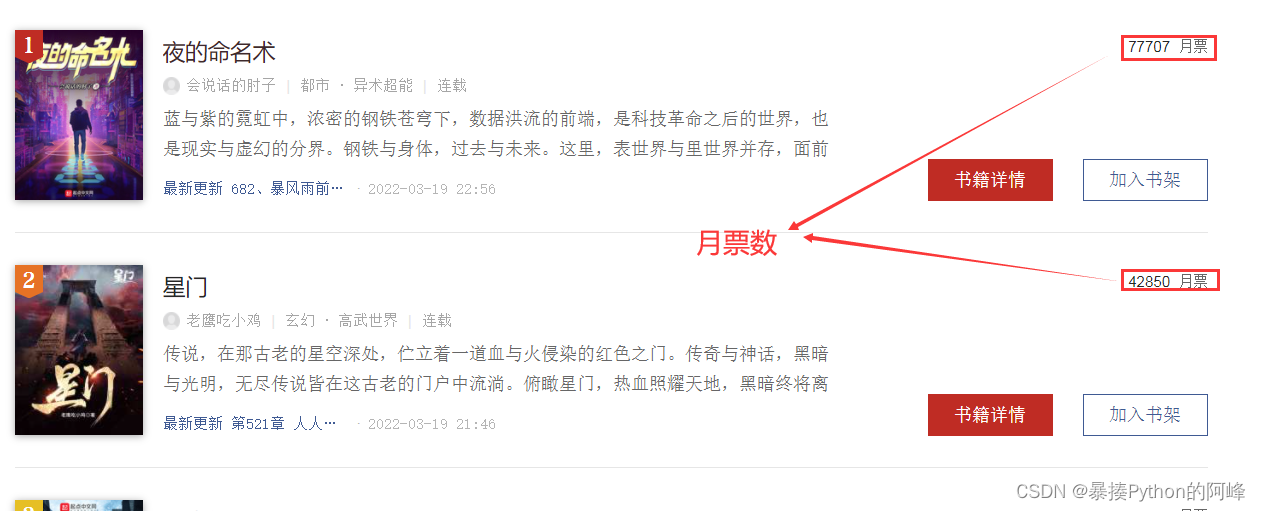
2、网页分析
- 我们通过网页检查,定位月票数时发现月票的数据被加密了
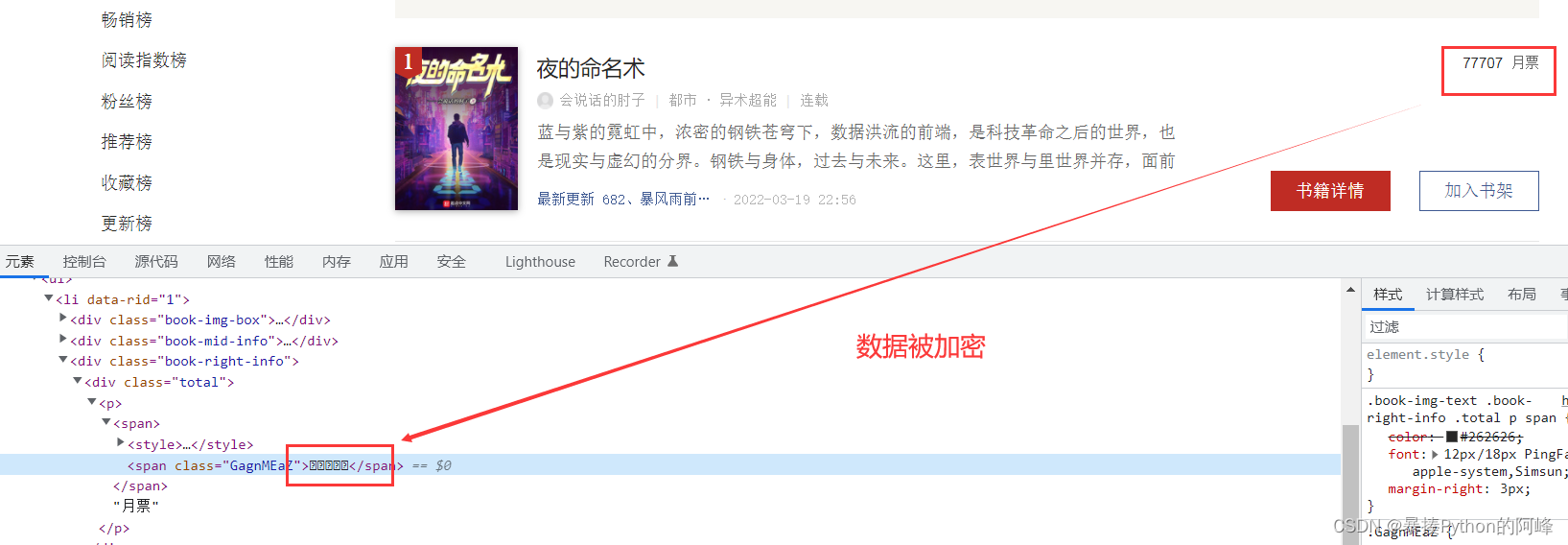
- 于是我们通过抓包,找到月票所在的数据包,发现在数据包的响应内容中,月票数被一些奇奇怪怪的数字和字符代替:
- 𘢓𘢓𘢓𘢏𘢒
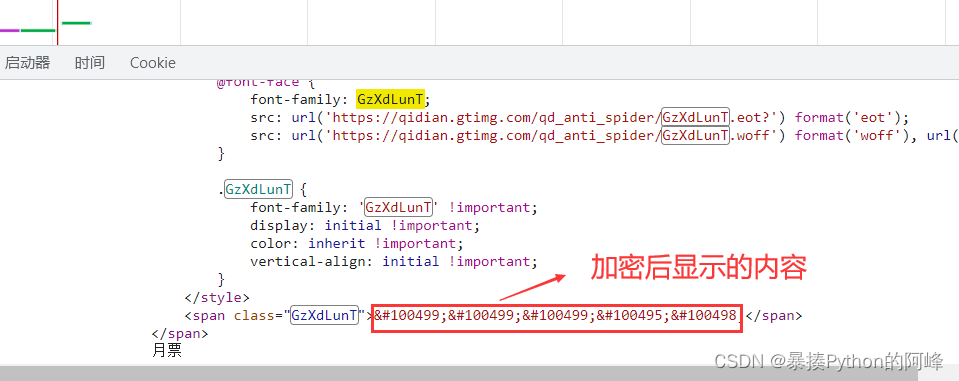
- 这些字符就是被加密后的样子,这时我们需要去找到解密的方法,我们可以在数据包中的响应内查看多个被加密的月票数据,发现他们都会有相同之处,那就是有一个相同的属性值:GzXdLunT,并且在font-face中出现了一个GzXdLunT.woff文件,所以这个属性值就是我们破案的关键。
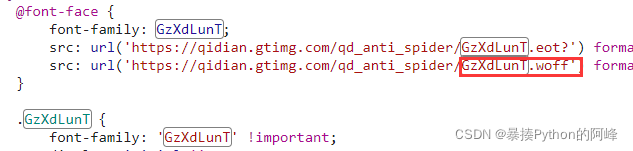
- 于是我们复制该属性值,在出现的各种数据包中查找是否有包含该属性值的文件名,于是我们找到了一个文件:GzXdLunT.woff
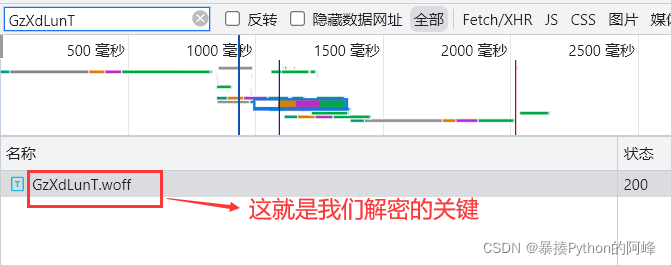
- 当我们鼠标双击该文件时,文件会自动下载
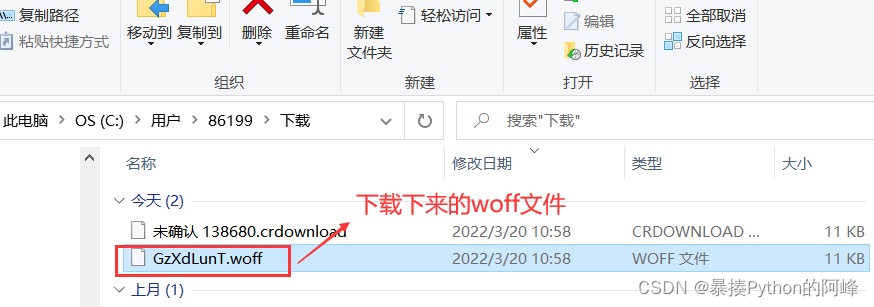
将此文件拖到我们的python文件目录中
二、思路步骤
1、找到关系映射表
基本步骤:
- 利用python方法将woff文件转换成xml格式 -- 搜索cmap -- 找到map标签 -- 找到月票数据的对应关系
woff文件转换成xml文件的方法:利用 fontTools 模块
- 导入模块:from fontTools.ttLib import TTFont
- 创建对象,参数为字体加密文件:font = TTFont('GzXdLunT.woff')
- 转换成xml格式:font.saveXML('f.xml')
代码演示
# 利用python中的方法进行转换
# 1.fontTools模块
# 2.转换成xml格式 -- 搜索cmap -- 找到map标签 -- 找到对应关系
from fontTools.ttLib import TTFont
# 创建对象,参数为字体加密文件
font = TTFont('GzXdLunT.woff')
#转换成html文件
font.saveXML('f.xml')- 运行结果,生成了一个f.xml文件
-
搜索cmap找到map标签
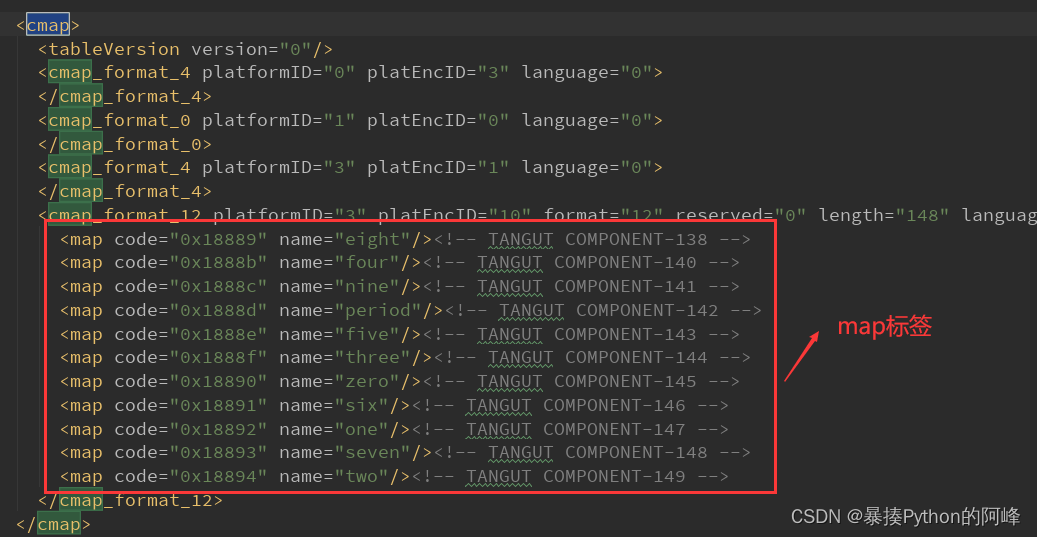
在map标签中我们可以看到code的属性值是一个16进制数,而且每个code后都有一个name属性,其值就是英文数字,而这个十六进制数转换成十进制就变成了月票中加密的数据,对应的name值就是月票数。
2、提供思路:解密一个数
我们解密月票的一个数字7,它加密的变成的是:𘢓
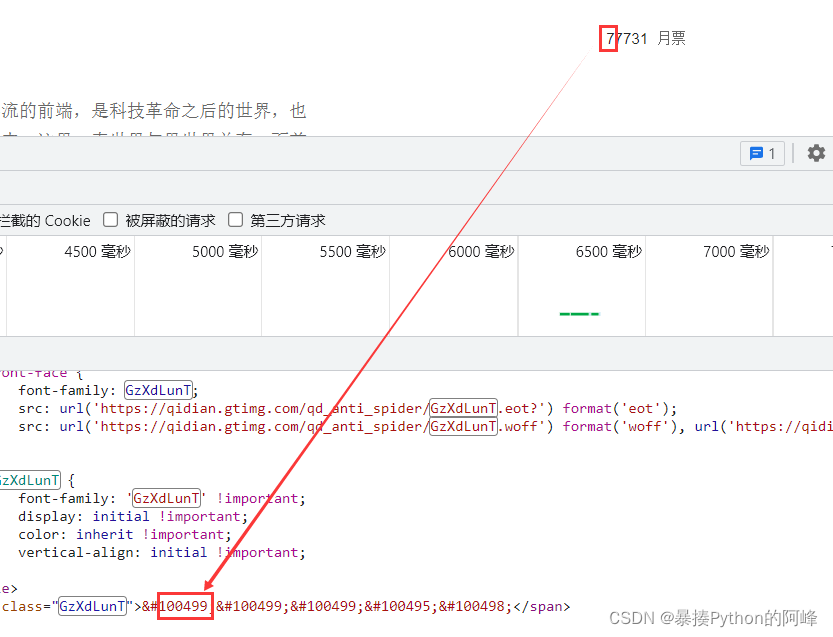
在关系映射表中找到,name的属性值为seven的map标签,复制map标签中的code属性值,将其转换成十进制
![]()
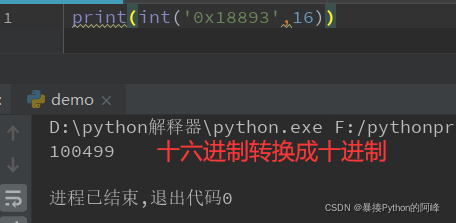
数据对应上了
3、编写代码思路
注意:woff文件是不断更新的,所以需要先获取到最新的woff文件
获取woff文件url、加密关键数据、加密的月票数据、小说名
- 首先构建一个字典,获取向网页发送请求
li = []
url = 'https://www.qidian.com/rank/yuepiao/'
headers = {
'User-Agent': ',
'Cookie': '',
'Referer': ''
}
res = requests.get(url, headers=headers)- 先获取月票数据对应加密的文件,(正则获取)
![]()
#获取月票数据对应加密的文件
li_url = re.findall("\); src: url\('(.*?)'\) format\('woff'\),",res.text)[0]- 获取加密的关键字(正则获取)

#获取加密的关键字
li_key = re.findall("https://qidian.gtimg.com/qd_anti_spider/(.*?).woff",li_url)[0]- 获取加密的月票数据(正则获取)
![]()
#获取加密的月票数据
li_data = re.findall(f'<span class="{li_key}">(.*?)</span></span>月票</p>',res.text)- 获取小说名
#获取小说名
html = etree.HTML(res.text)
li_name = html.xpath('//*[@id="book-img-text"]/ul/li[*]/div[2]/h2/a/text()')- 将加密文件url、加密的月票数据放入、小说名放到列表li中
li = []
li.append(li_url) #放入加密文件url
li.append(li_data) #放入加密数据
li.append(li_name) #放入小说名- 列表li中的数据展示

获取关系映射表,解密数据
- 对加密文件url发送请求
url = li[0]
headers = {
'User-Agent': ''
}
res1 = requests.get(url, headers=headers)- 保存xml文件
font2 = TTFont(BytesIO(res1.content)) #BytesIO在内存中读写bytes
font2.saveXML('c.xml')- 获取关系映射表
cmap = font2.getBestCmap()- 构建一个字典,用来翻译
trans = {'zero':0,'one':1, 'two':2, 'three':3, 'four':4, 'five':5, 'six': 6, 'seven':7, 'eight':8, 'nine':9}- 通过for循环,清洗加密的月票数据,也就是将𘢓清洗成100499
n = 0
li_num = []
for i in li[1]:
n += 1
data = f'月票榜第{n}:'
#定义以一个空列表,用来存放匹配出的英文排序
li1 = []
cp1 = re.findall('.#(.*?);', i) #通过正则,分离出想要的信息
for j in cp1:
li1.append(cmap[int(j)])
#读出月票数
for k in li1:
data += str(trans[k])
li_num.append(data)- 将小说名和月票数保存在csv文件中
f = open('小说.csv', 'a', encoding='utf-8')
#基于文件对象构建csv写入对象
csv_write = csv.writer(f)
#构建表头
csv_write.writerow(["小说", "月票"])
for i in range(len(li_num)):
#写入csv文件内容
csv_write.writerow([f"{li[2][i]}", f"{li_num[i]}"])



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











