




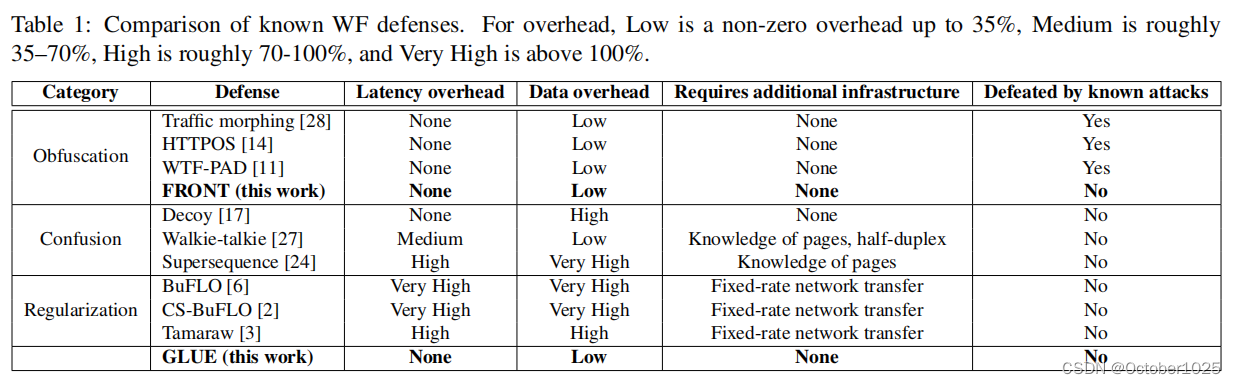
 本文介绍了两种新的网络安全防御技术FRONT和GLUE,FRONT通过混淆跟踪前端和随机数据包分布提高攻击者学习难度,而GLUE则通过粘合痕迹来欺骗攻击者,防止他们对多页浏览进行分类。两者在数据开销和性能上优于前任方案,如WTF-PAD。
本文介绍了两种新的网络安全防御技术FRONT和GLUE,FRONT通过混淆跟踪前端和随机数据包分布提高攻击者学习难度,而GLUE则通过粘合痕迹来欺骗攻击者,防止他们对多页浏览进行分类。两者在数据开销和性能上优于前任方案,如WTF-PAD。
2020 usenix
前人
- WTF-PAD[2016] -> broken by DF
- Tamaraw[2014] ->
FRONT:侧重于用虚拟数据包混淆跟踪前端。随机化了虚拟数据包的数量和分布,以实现跟踪间随机性,从而阻碍攻击者的学习过程。
GLUE:在单独的跟踪之间添加虚拟数据包,看起来好像客户端正在连续访问页面而没有暂停,使攻击者无法找到他们的起点或终点,也便无法对其进行分类。
在33%的数据开销下,攻击者性能和信息泄露分析方面,FRONT优于WTF-PAD;GLUE 数据开销约为22%-44%,可以将最佳WF攻击的准确性 TPR 和精度降低到与最佳重量级防御相当的水平,这两种防御都没有延迟开销。
FRONT
概述
实现可部署性需具备三个特性:零延迟(无延迟开销)、轻量级(数据开销小)、易于实施
唯一已知的与 FRONT 共享这些属性的防御是 WTF-PAD。在 WTF-PAD 中,客户端和服务器分别维护两个直方图,在其中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1532
1532




 到【灌水乐园】发言
到【灌水乐园】发言







