




 本文通过导入Excel数据,展示了如何使用Python的pandas库进行数据分析,包括数据标准化、分组统计、时间序列处理及排序等操作。
本文通过导入Excel数据,展示了如何使用Python的pandas库进行数据分析,包括数据标准化、分组统计、时间序列处理及排序等操作。
用以下数据做一个简单的python数据分析案例
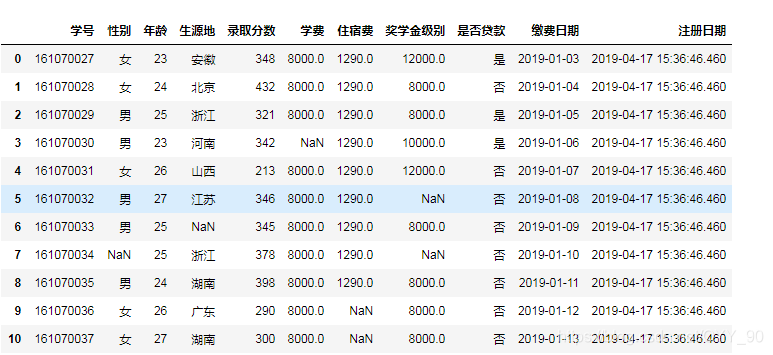
#导入excel数据
import pandas as pd
df= pd.read_excel(r'E:\ETL_soft\python\tt.xlsx')
df
#数据列的形式用中括号统一一下
#df['标准分']=(df.录取分数 - df.录取分数.min())/(df.录取分数.max()-df.录取分数.min())
#df
df['标准分']=(df['录取分数'] - df['录取分数'].min())/(df['录取分数'].max()-df['录取分数'].min())
df
#bins=[min(df.['录取分数'])-1,300,400,max(df.['录取分数'])+1]
#数据框里面的数据可以df.字段,如果是新增字段,可以用df['字段名']
bins=[min(df.录取分数)-1,300,400,max(df.录取分数)+1]
labels=['300分以下','300-400之间','400以上']
df['result']=pd.cut(df.录取分数,bins=bins,right=False,labels=labels)
df
#首先将日期用to_datetime改成标准格式,且format能加快速度,
#再应用apply更改时间为字符串,并命名周期
df['周期'] = to_datetime(df.注册日期,format="%Y/%m/%d").apply(lambda x: datetime.strftime(x,"%Y-%m-%d"))
df.head()
#进行分组
grouped = df['录取分数'].groupby(df['result'])
grouped.mean()
#统计各年份和月份出现的次数
#data.stop_datetime.dt.year.value_counts()
#data.stop_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1737
1737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









