



XXL-JOB路由策略
一、单节点策略
1. FIRST(第一个)
- 工作原理:选择第一个注册的执行器
- 作用:确保任务始终由固定实例处理
- 优点:
- 实现简单
- 结果可预测
- 调试方便
- 缺点:
- 单点故障风险
- 不支持负载均衡
- 适用场景:
- 开发测试环境
- 单实例部署场景
- 需要固定执行器的情况
2. LAST(最后一个)
- 工作原理:选择最后一个注册的执行器
- 作用:特殊场景下的固定路由
- 优点:
- 实现简单
- 与FIRST形成互补
- 缺点:
- 实际应用场景有限
- 负载不均衡
- 适用场景:
- 特定调试需求
- 轮换执行器测试
3. ROUND(轮询)
- 工作原理:按注册顺序轮询选择执行器
- 作用:基础负载均衡
- 优点:
- 简单负载均衡
- 无状态实现
- 缺点:
- 无法感知实例负载
- 处理时间不均时效果差
- 适用场景:
- 执行器能力均等场景
- 短期任务分发
4. RANDOM(随机)
- 工作原理:随机选择执行器
- 作用:简单随机分配
- 优点:
- 实现简单
- 概率平衡
- 缺点:
- 实际负载可能不均
- 无法保证结果一致性
- 适用场景:
- 无状态任务
- 简单任务分发系统
二、集群负载策略
1. HASH(哈希)
- 工作原理:对任务参数哈希取模
- 作用:相同参数路由到相同实例
- 优点:
- 参数关联型任务支持
- 结果可预测
- 缺点:
- 扩容时需重新哈希
- 参数分布不均导致负载不均
- 适用场景:
- 用户会话相关任务
- 需要固定路由的计算任务
2. CONSISTENT_HASH(一致性哈希)
- 工作原理:使用一致性哈希算法
- 作用:最小化实例变更影响
- 优点:
- 扩容影响最小化
- 负载相对均衡
- 缺点:
- 实现复杂
- 虚拟节点管理困难
- 适用场景:
- 频繁扩容/缩容场景
- 需要稳定路由的大规模集群
3. LFU(最少使用频率)
- 工作原理:选择历史调用最少的执行器
- 作用:基于频率的负载均衡
- 优点:
- 长期负载均衡
- 避免热点实例
- 缺点:
- 历史数据敏感
- 无法应对突发流量
- 适用场景:
- 长期运行任务
- 资源密集型任务
4. LRU(最近最少使用)
- 工作原理:选择最近最久未使用的执行器
- 作用:基于时效的负载均衡
- 优点:
- 利用空闲资源
- 短期负载均衡
- 缺点:
- 无法应对持续高负载
- 历史数据敏感
- 适用场景:
- 突发流量场景
- 周期性任务系统
三、特殊场景策略
1. FAILOVER(故障转移)
- 工作原理:失败时自动转移其他实例
- 作用:提高任务可靠性
- 优点:
- 高可靠性
- 自动容错
- 缺点:
- 失败重试增加延迟
- 可能重复执行
- 适用场景:
- 关键业务任务
- 金融交易系统
2. BUSYOVER(忙碌转移)
- 工作原理:选择空闲实例执行任务
- 作用:避免实例过载
- 优点:
- 资源利用率优化
- 防止雪崩
- 缺点:
- 需要实时状态监控
- 增加调度复杂度
- 适用场景:
- 资源敏感型系统
- 高负载波动场景
四、分片广播策略(核心重点)
原理机制
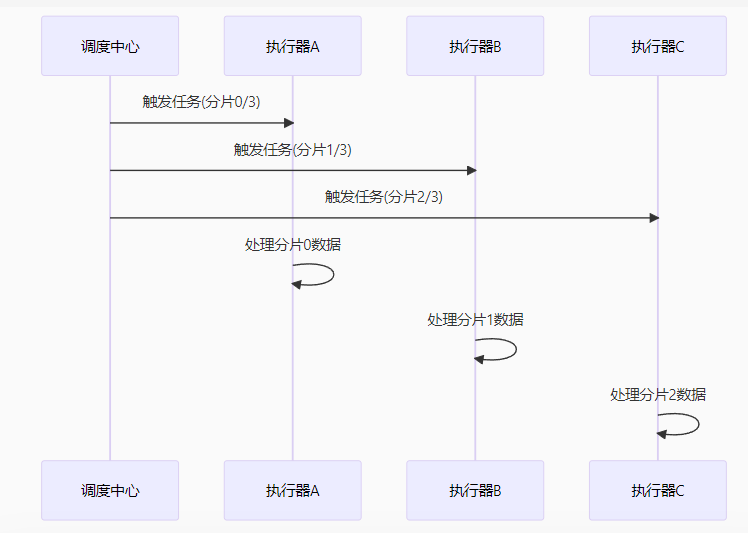
服务有多少个实例,总分片数就是多少。比如服务启动了4个实例,总分片数ShardTotal就是4,每个实例的ShardIndex分别是0,1,2,3
核心特点
- 广播触发:所有实例同时接收任务
- 分片参数:
shardIndex:当前分片索引shardTotal:总分片数
- 数据分区:每个实例处理不同数据子集
使用方法
@XxlJob("shardingJob")
public void shardingJob() {
// 获取分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
// 数据分片处理
List<Data> shardData = fetchDataByShard(shardIndex, shardTotal);
processShard(shardData);
}
private List<Data> fetchDataByShard(int index, int total) {
// 示例哈希分片查询
String sql = "SELECT * FROM table WHERE MOD(key, ?) = ?";
return jdbcTemplate.query(sql, new Object[]{total, index}, rowMapper);
}
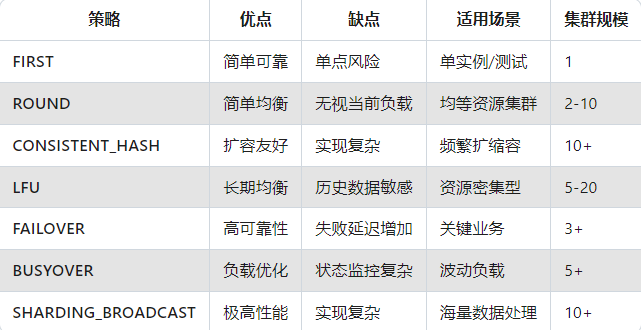
五、路由策略对比表
代码优化
原项目有个定时任务,需要从数据库中查询出所有满足条件的数据,并进行后续处理。当前是一次性从数据库中查询出所有满足条件的数据,并在配置xxljob任务时路由策略选择的是第一个,这在数据量比较少的时候也没啥问题,但是数据量一旦过多,就会非常消耗数据库性能。
@XxlJob("clearEmptyLibraryJob")
public void clearEmptyLibrary() {
log.info("clearEmptyLibraryJob start");
StopWatch stopWatch = new StopWatch();
stopWatch.start();
try {
// 查询满足条件的待删除库
List<SearchLibraryRespVo> respVos = this.selectLibraryToDelete();
if (CollectionUtils.isEmpty(respVos)) {
log.info("没有待删除库");
return;
}
// todo 后续处理逻辑
} catch (Exception e) {
log.error("clearEmptyLibraryJob error", e);
}
}
/**
* 一次性查询所有满足条件的待删除库
* @return
*/
private List<SearchLibraryRespVo> selectLibraryToDelete() {
ResponseResult<List<SearchLibraryRespVo>> responseResult = libraryInfoFeignApi.selectLibraryToDelete();
if(responseResult == null || !responseResult.isSuccess() || responseResult.getData() == null){
log.error("获取空库失败!");
return Lists.newArrayList();
}
return responseResult.getData();
}
由此可以采用分片广播的策略,让每个服务实例可以并行处理不同的数据,这样就可以充分利用服务资源和有效降低数据库压力。
@XxlJob("clearEmptyLibraryJob")
public void clearEmptyLibrary() {
log.info("clearEmptyLibraryJob start");
StopWatch stopWatch = new StopWatch();
stopWatch.start();
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
try {
// 每个服务实例只处理自己分片的库
List<SearchLibraryRespVo> respVos = this.selectLibraryToDelete(shardIndex, shardTotal);
if (CollectionUtils.isEmpty(respVos)) {
log.info("没有待删除库");
return;
}
// todo 后续处理逻辑
} catch (Exception e) {
log.error("clearEmptyLibraryJob error", e);
}
}
/**
* 每个服务实例只处理自己分片的库
* @return
*/
private List<SearchLibraryRespVo> selectLibraryToDelete(int shardIndex, int shardTotal) {
ResponseResult<List<SearchLibraryRespVo>> responseResult = libraryInfoFeignApi.selectLibraryToDelete(shardIndex, shardTotal);
if(responseResult == null || !responseResult.isSuccess() || responseResult.getData() == null){
log.error("获取空库失败!");
return Lists.newArrayList();
}
return responseResult.getData();
}

















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









