



SQL语句常见逻辑错误:这些“无声”的陷阱,你中招了吗?
除了显而易见的语法错误,SQL语句中更具挑战性的是那些不会报错,却默默导致结果不准确或性能低下的逻辑错误。这类错误往往需要我们对业务逻辑和数据特性有更深入的理解才能发现和解决。
首先来个非常
一、条件与筛选的逻辑陷阱
这部分错误往往出现在 WHERE、JOIN、HAVING 等子句中,导致数据筛选不准确。
-
NULL值的判断失误-
问题描述: 在SQL中,
NULL代表“未知”或“不存在”,它不能用=、<>、<、>等普通比较运算符进行判断。 -
错误示例:
SQL-- 错误:无法找出那些邮箱地址为空的用户 SELECT * FROM users WHERE email = NULL; -- 错误:无法找出邮箱地址不为空的用户 SELECT * FROM users WHERE email <> NULL; -
正确做法: 必须使用
SQLIS NULL或IS NOT NULL来判断NULL值。-- 正确:找出邮箱地址为空的用户 SELECT * FROM users WHERE email IS NULL; -- 正确:找出邮箱地址不为空的用户 SELECT * FROM users WHERE email IS NOT NULL; -
易错点延伸: 当对可能包含
NULL值的列进行COUNT()时,COUNT(column_name)只会计算非NULL的行,而COUNT(*)或COUNT(1)会计算所有行(包括NULL值所在的行)。
-
-
日期时间范围的“边缘”问题
-
问题描述: 在查询某个日期范围内的数据时,边界条件设置不当可能导致遗漏数据或包含额外数据。
-
错误示例: 假设要查询2023年1月1日全天的数据。
SQL-- 错误:只包含了2023-01-01 00:00:00 那一刻的数据 SELECT * FROM logs WHERE log_time = '2023-01-01'; -- 错误:可能会遗漏2023-01-01 23:59:59 的数据,取决于具体日期类型和数据库版本 SELECT * FROM logs WHERE log_time >= '2023-01-01' AND log_time <= '2023-01-01 23:59:59'; -
正确做法: 使用“大于等于起始时间,小于下一天的起始时间”的范围。
SQL-- 正确:查询2023年1月1日全天的数据 SELECT * FROM logs WHERE log_time >= '2023-01-01 00:00:00' AND log_time < '2023-01-02 00:00:00'; -- 或者使用 BETWEEN AND(如果列是日期类型,不含时间部分) -- 如果log_time是DATE类型,'2023-01-01' 会被视为 '2023-01-01 00:00:00' 到 '2023-01-01 23:59:59' SELECT * FROM logs WHERE log_date BETWEEN '2023-01-01' AND '2023-01-01'; -
规避方法: 对于时间范围查询,始终考虑“左闭右开”原则(
>= 起始时间 AND < 下一天起始时间),这能确保数据范围的精确性。
-
-
IN与EXISTS的选择不当(性能问题)-
问题描述:
IN和EXISTS都能实现子查询,但在特定场景下,它们的性能差异可能非常大。 -
错误示例(性能角度):
SQL-- 假设 large_users 表非常大,而 small_orders 表相对较小 -- 当子查询结果集(small_orders.user_id)非常大时,IN 的性能可能下降 SELECT * FROM large_users WHERE user_id IN (SELECT user_id FROM small_orders WHERE order_date >= '2023-01-01'); -
优化建议:
-
当子查询结果集较小或固定时,
IN效率通常较高。 数据库会将IN列表中的值进行排序后查询主表。 -
当子查询结果集较大或不确定时,
EXISTS通常更优。EXISTS会对主查询的每一行去判断子查询是否存在匹配项,只要找到第一个匹配就停止,而不是执行整个子查询。
-- 当 small_orders 表很大时,用 EXISTS 可能会更高效 SELECT * FROM large_users lu WHERE EXISTS (SELECT 1 FROM small_orders so WHERE so.user_id = lu.user_id AND so.order_date >= '2023-01-01'); -
-
规避方法: 结合实际数据量和查询需求,通过
EXPLAIN分析两种写法的执行计划,选择最优方案。通常JOIN也能替代它们,且性能往往更好。
-
二、数据操作 (DML) 的逻辑陷阱
在插入、更新、删除数据时,一不小心就会造成数据混乱或丢失。
-
UPDATE或DELETE语句无WHERE条件-
问题描述: 这是最危险的错误之一,它不会报错,却会把整个表的数据全部修改或删除。
-
错误示例:
SQL-- 灾难性:会把 products 表的所有库存都设置为 0 UPDATE products SET stock = 0; -- 灾难性:会删除 users 表的所有用户数据 DELETE FROM users; -
规避方法: 永远,永远,永远在执行
UPDATE或DELETE前,先用SELECT语句带上相同的WHERE条件进行测试,确认筛选出的数据是预期的目标数据。在生产环境中,务必开启事务,操作完成后再COMMIT。
-
-
INSERT语句字段与值不匹配-
问题描述: 列名与值列表的顺序、数量或数据类型不一致,导致数据插入到错误的列或发生隐式转换错误。
-
错误示例:
SQL-- 假设 users 表结构是 (id INT, name VARCHAR(50), age INT) -- 错误:值的顺序与列名不符,或类型不匹配 INSERT INTO users (name, id, age) VALUES (1, 'Alice', '25'); -
正确做法: 始终明确指定列名,并确保值与列名一一对应且类型兼容。
SQL-- 正确:列名与值顺序和类型都匹配 INSERT INTO users (id, name, age) VALUES (1, 'Alice', 25); -
规避方法: 养成显式列出所有列名的好习惯,避免依赖默认顺序。
-
三、聚合与分组的逻辑陷阱
GROUP BY 和聚合函数的滥用或误用,常会导致统计结果偏差。
-
GROUP BY遗漏非聚合列-
问题描述: 在
SELECT语句中,如果同时出现了聚合函数(如COUNT(),SUM(),AVG())和非聚合列,那么所有非聚合列都必须出现在GROUP BY子句中,否则会报错(或在某些DB中给出不确定的结果)。 -
错误示例:
SQL-- 错误:会报错,因为 employee_name 没有在 GROUP BY 中 SELECT department, AVG(salary), employee_name FROM employees GROUP BY department; -
正确做法: 将所有非聚合列都放入
SQLGROUP BY。-- 正确:按部门和员工姓名分组,但通常这样的分组可能没有太大意义 SELECT department, employee_name, AVG(salary) FROM employees GROUP BY department, employee_name; -- 如果只想按部门计算平均薪资,则只选择部门和聚合函数 SELECT department, AVG(salary) FROM employees GROUP BY department; -
规避方法: 记住原则:“SELECT列表中,除了聚合函数之外的所有列,都必须出现在GROUP BY子句中。”
-
-
HAVING与WHERE的混淆-
问题描述:
WHERE用于过滤原始行,在分组之前执行;HAVING用于过滤分组后的结果。如果混淆,可能导致结果不准确或查询效率低下。 -
错误示例: 假设我们想找到平均薪资高于50000的部门中,男性员工的平均薪资。
SQL-- 错误:WHERE 对分组后的结果过滤,HAVING 对原始行过滤 SELECT department, AVG(salary) FROM employees WHERE AVG(salary) > 50000 -- WHERE 不能直接使用聚合函数 GROUP BY department HAVING gender = 'Male'; -- HAVING 通常用于聚合结果的过滤 -
正确做法:
SQL-- 正确:先过滤出男性员工,然后按部门分组并计算平均薪资,最后过滤平均薪资高于50000的部门 SELECT department, AVG(salary) AS avg_dept_salary FROM employees WHERE gender = 'Male' -- 先用 WHERE 过滤原始行 GROUP BY department HAVING avg_dept_salary > 50000; -- 再用 HAVING 过滤分组后的结果 -
规避方法:
-
WHERE是“行过滤器”:应用于FROM和JOIN后的原始数据集。 -
HAVING是“组过滤器”:应用于GROUP BY后的分组结果集,可以包含聚合函数。 -
优先级:
WHERE->GROUP BY->HAVING->SELECT->ORDER BY。
-
-
四、事务与并发的逻辑陷阱
在多用户环境中,如果不正确处理事务,可能导致数据一致性问题。
-
事务隔离级别不理解
-
问题描述: 不同的事务隔离级别(如
READ UNCOMMITTED,READ COMMITTED,REPEATABLE READ,SERIALIZABLE)对并发操作的可见性和一致性有不同的影响。理解不足可能导致脏读、不可重复读、幻读等问题。 -
常见影响:
-
脏读 (Dirty Read): 读取到其他事务未提交的数据。
-
不可重复读 (Non-Repeatable Read): 同一事务内,两次读取同一行数据,结果不同(因为其他事务修改并提交了该行)。
-
幻读 (Phantom Read): 同一事务内,两次执行相同查询,第二次查询发现新增了符合条件的行(因为其他事务插入了新行并提交)。
-
-
规避方法: 根据业务需求选择合适的隔离级别。MySQL的默认隔离级别是
REPEATABLE READ,它能解决脏读和不可重复读,但仍可能出现幻读(在某些条件下)。对于对数据一致性要求极高的场景,可能需要更严格的隔离级别或额外的锁机制。
-
接下来我会用高校常用的课程数据库(schooldb)来展示逻辑错误为什么需要得到重视:
多对多关系中的重复计数问题
问题描述: 在处理多对多关系(通过一个中间表连接)并尝试对一方进行计数时,如果直接进行 JOIN 后再 COUNT,可能会因为 JOIN 产生了重复行而导致计数结果偏高。
场景: 我们想统计选修了任意课程的学生总人数。
错误示例:
SQL
-- 错误尝试:直接 JOIN 后 COUNT 学生学号
SELECT COUNT(s.学号) AS 选课学生总数
FROM student s
JOIN score sc ON s.学号 = sc.学号;
错误分析:
-
数据重复:
student表和score表通过学号连接。如果一个学生选修了多门课程(即在score表中有多个记录),那么在JOIN之后,该学生的记录会在结果集中出现多次。 -
计数偏差:
COUNT(s.学号)会对JOIN后产生的每一行进行计数。如果学生2013110101选了11003和21001两门课,他会出现在JOIN结果的两行中,因此会被COUNT两次,导致最终统计的学生总数多于实际的独立学生数。
实际运行结果(在 schooldb 中):
首先,让我们看看原始数据中到底有多少个不同的学生选了课:
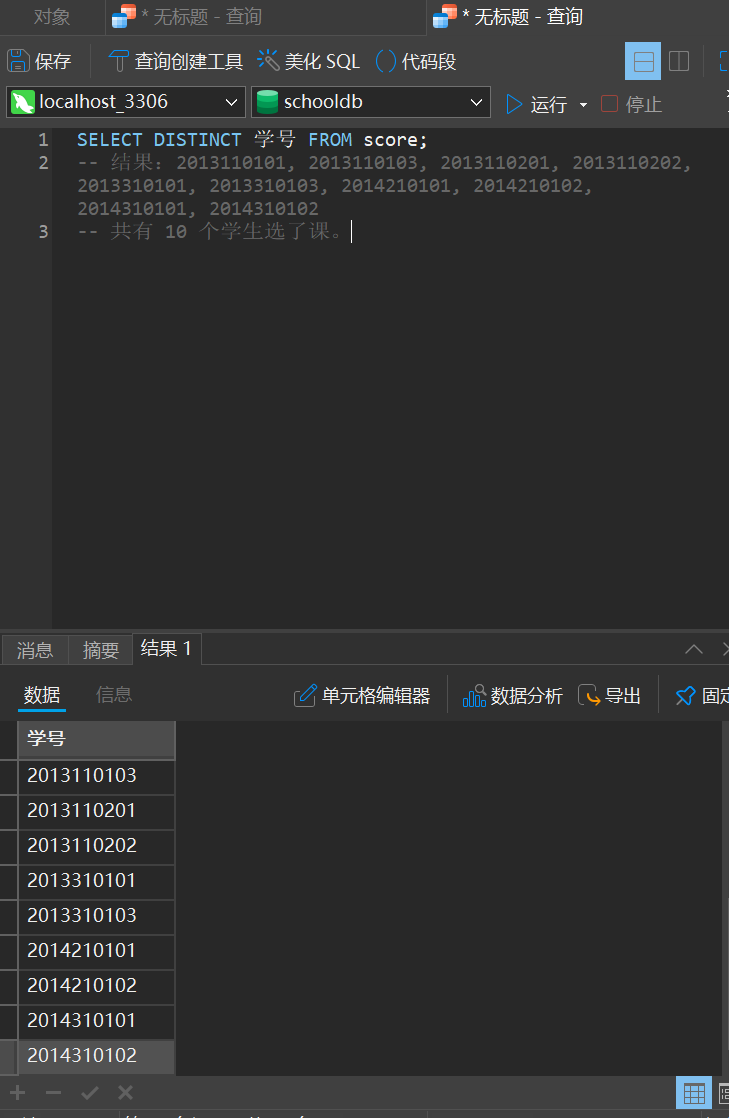
现在看错误查询的结果:
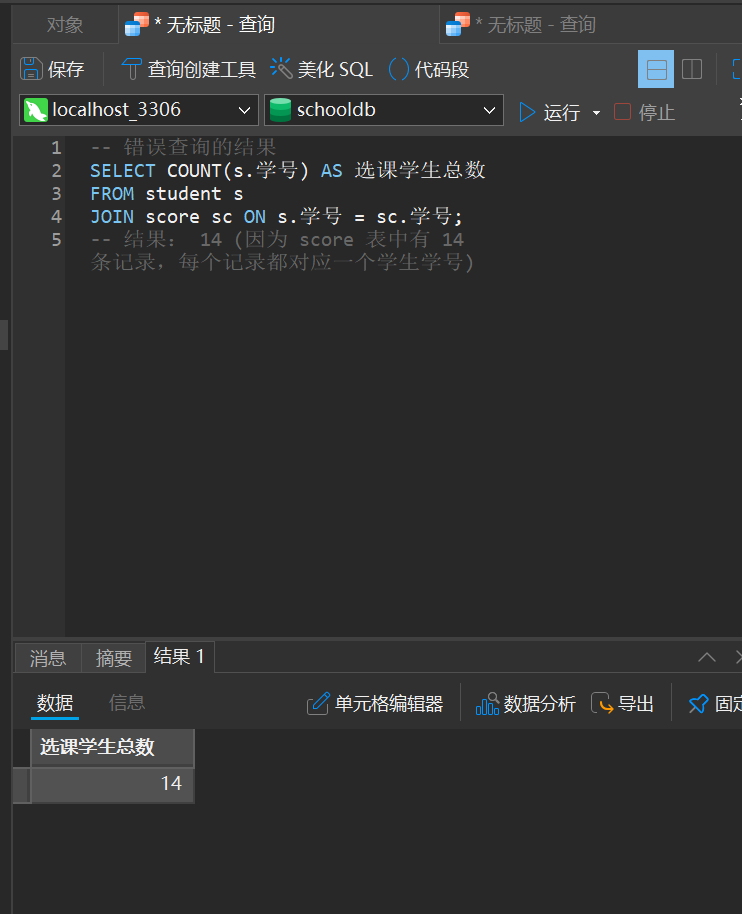
显然,与实际不符。
正确做法:
我们需要确保在计数时,每个唯一的学生只被计算一次。
SQL
-- 正确方法一:先找出所有选课的唯一学生学号,再计数
SELECT COUNT(学号) AS 选课学生总数
FROM (SELECT DISTINCT 学号 FROM score) AS distinct_students;
-- 结果: 10
-- 正确方法二:如果只是为了统计选课的学生人数,甚至可以只查询 score 表
SELECT COUNT(DISTINCT 学号) AS 选课学生总数
FROM score;
-- 结果: 10
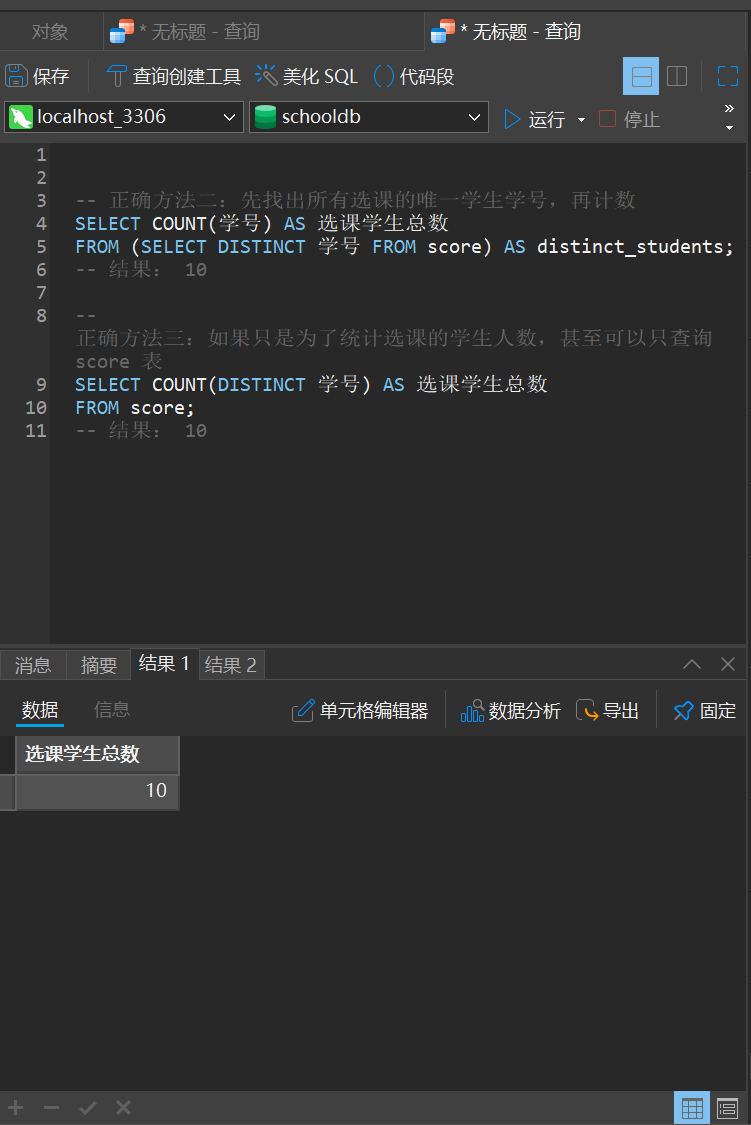
可以看到,结果已变成正确的了。
重点:
-
解释多对多关系: 学生与课程是多对多关系,通过
score表连接。 -
展示
JOIN后的中间结果集: 可以先不COUNT,直接SELECT s.学号, s.姓名, sc.课程号,让学生看到同一个学生学号是如何重复出现的。 -
强调
COUNT(DISTINCT column_name)的作用: 它是解决这类计数问题的关键。 -
引导思考: 在什么情况下,
JOIN后直接COUNT(*)或COUNT(列名)是可以的(例如,如果主表记录在从表只有一对一关系)。
通过这个具体的演示,你可以清晰地展示SQL中逻辑错误的危害,以及如何运用正确的SQL知识来规避这些问题。
这些逻辑错误在实际开发中非常常见,而且由于它们不会导致语法报错,所以往往需要更仔细的检查和对数据模型的理解才能发现。在你的演示中,通过这些例子能够很好地说明逻辑错误如何“无声无息”地影响结果,并强调 EXPLAIN 和 DISTINCT 等工具的重要性。
我的反思与建议
这些逻辑错误往往是“沉默的杀手”,它们不像语法错误那样直截了当。要避免它们,关键在于:
-
深入理解SQL的执行顺序和每条语句的语义:了解数据库内部如何处理你的查询,例如
WHERE先于GROUP BY,HAVING后于GROUP BY。 -
业务逻辑与SQL语句的紧密结合:在编写SQL前,清晰地定义你要解决的业务问题,并在脑海中模拟数据流转和筛选过程。
-
小步快跑,逐步构建复杂查询:先写简单的部分,逐步添加
JOIN、WHERE、GROUP BY等,每一步都进行测试,确认结果符合预期。 -
善用
EXPLAIN:这是SQL优化的利器,通过它能分析查询的执行计划,发现潜在的性能瓶颈和不合理的逻辑。 -
单元测试与数据验证:为关键的SQL逻辑编写单元测试,并使用典型数据和边界数据进行测试,验证结果的准确性。

















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









