




 本文详细解读了如何使用CUDA在ARM平台上通过共享内存优化矩阵乘法,涉及滑块算法、GPU并行计算思维,以及如何分配和使用__shared__ memory。实例演示了矩阵C=M*N的计算过程,包括thread协调和block操作的策略。
本文详细解读了如何使用CUDA在ARM平台上通过共享内存优化矩阵乘法,涉及滑块算法、GPU并行计算思维,以及如何分配和使用__shared__ memory。实例演示了矩阵C=M*N的计算过程,包括thread协调和block操作的策略。
代码部分
首先贴上代码,具体的讲解在后面展开。
__global__ void gpu_matrix_mult_shared(int *d_a, int *d_b, int *d_result, int m, int n, int k){
__shared__ int tile_a[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int tile_b[BLOCK_SIZE][BLOCK_SIZE];
int row = blockIdx.y * BLOCK_SIZE + threadIdx.y;
int col = blockIdx.x * BLOCK_SIZE + threadIdx.x;
int tmp = 0;
int idx;
for(int sub = 0; sub <= n/BLOCK_SIZE; ++sub){
idx = row * n + sub * BLOCK_SIZE + threadIdx.x;
tile_a[threadIdx.y][threadIdx.x] = row < m &&(sub * BLOCK_SIZE + threadIdx.x)<n?d_a[idx]:0;
idx = (sub * BLOCK_SIZE + threadIdx.y) * k + col;
tile_b[threadIdx.y][threadIdx.x] = col<k && (sub * BLOCK_SIZE + threadIdx.y)<n? d_b[idx]:0;
__syncthreads();
for(int i = 0; i < BLOCK_SIZE; ++i){
tmp+= tile_a[threadIdx.y][i] * tile_b[i][threadIdx.x];
}
__syncthreads();
}
if(row < m && col < k){
d_result[row * k + col] = tmp;
}
}
讲解部分
由于Shared Memory空间极小,因此一般在优化矩阵乘法时无法完全将需要求解的矩阵从global memory完全提取到shared memory,因此需要采用“滑块”的算法。
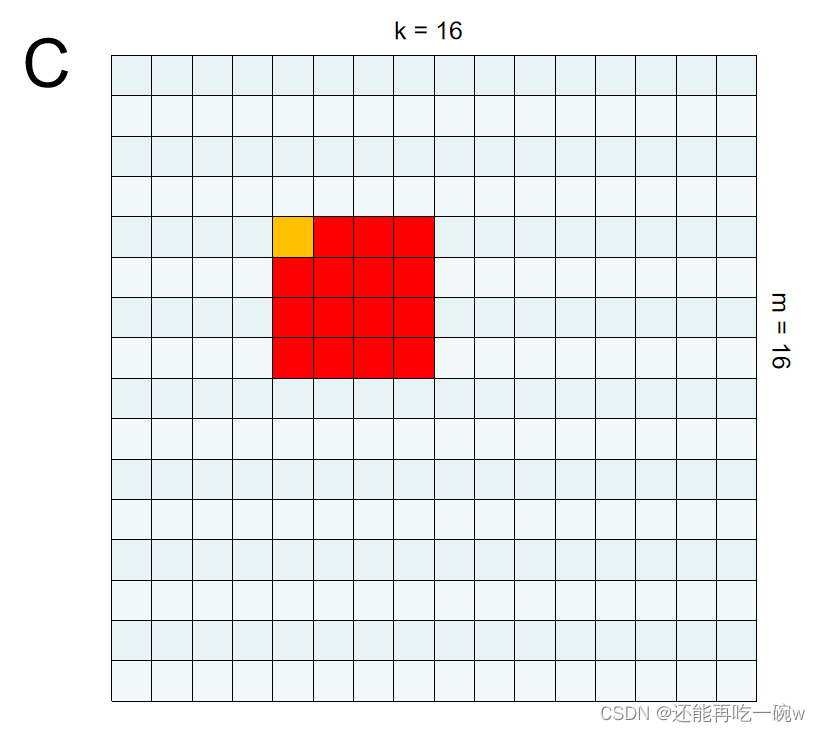
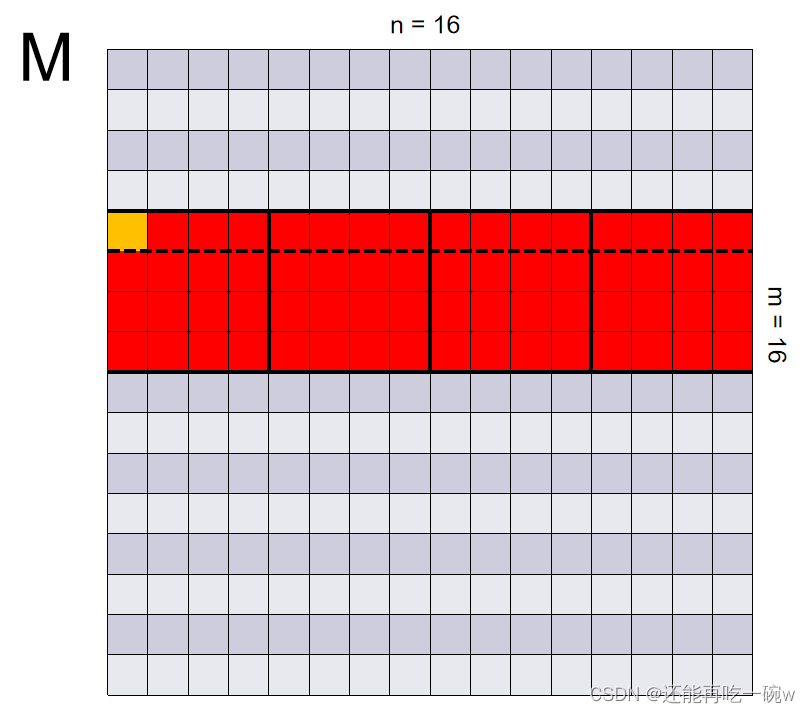
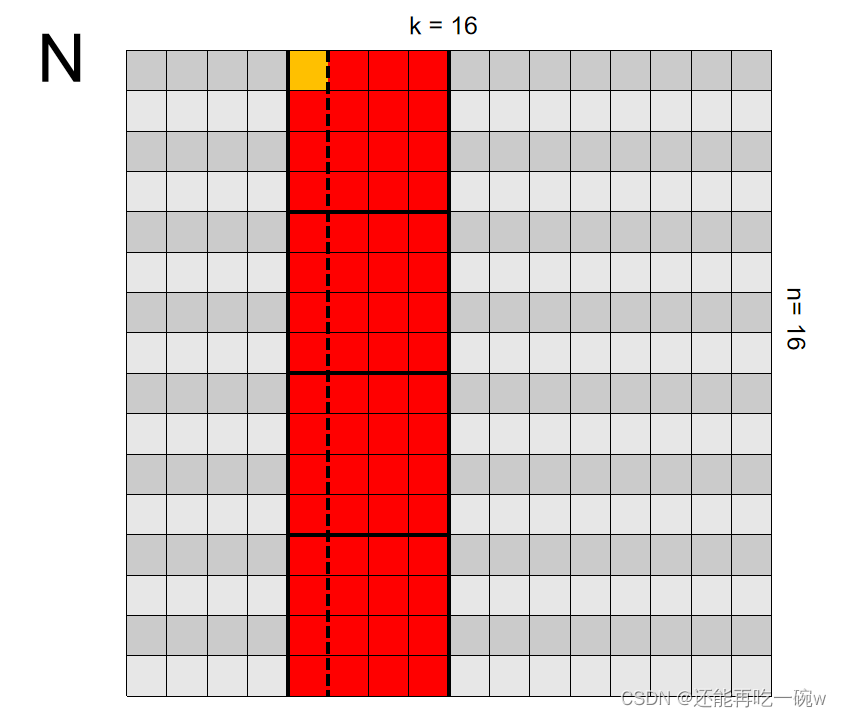
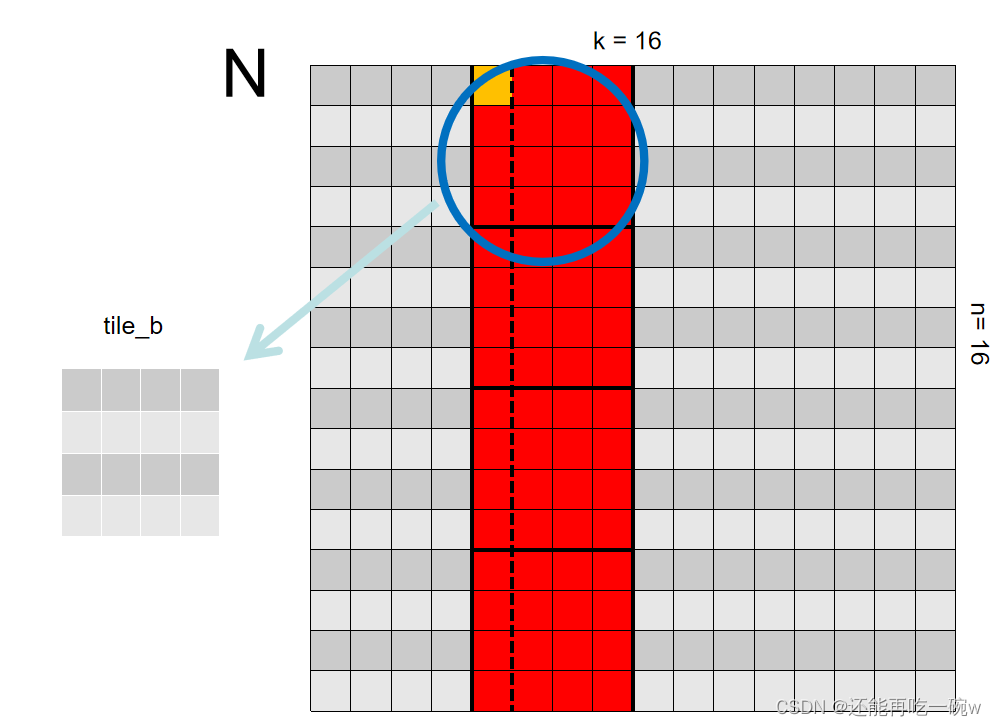
个人认为,要想搞定利用Shared Memory优化矩阵乘法,关键是要理解GPU的并行计算的思维。如下图一个具体的矩阵乘法案例 C = M * N所示:
由于该矩阵的最终输出大小是1616,可设定grid值为(4,4),block值为(4,4)(提示,尽量设定block的值为32的整数倍,本文章由于举得例子矩阵过小,所以设定block大小为44)。
首先,聚焦于单一的thread:因为在核函数的最后,需要在每个thread中给矩阵C对应的元素赋值,因此需要在首先通过左边变换得到每个thread对应于矩阵C元素的位置。
int row = blockIdx.y * BLOCK_SIZE + threadIdx.y;
int col = blockIdx.x * BLOCK_SIZE + threadIdx.x;
如图矩阵C中标黄的元素所对应的线程中,blockIdx为(1,1),threadIdx为(0,0),因此,row = 4,col = 4。
其次,开始关注整个block的操作,每一个block都负责求解对应矩阵中相同位置的矩阵元素值,例如blockIdx为(1,1)所对应的即为矩阵C中标红的部分。
由线性代数的矩阵乘法可知:

通过此式子可以看出,申请的两块shared memory分别用来存储矩阵M和矩阵N中对应的元素,即图中红色标记部分。
__shared__ int tile_a[BLOCK_SIZE/2][BLOCK_SIZE*2];
__shared__ int tile_b[BLOCK_SIZE*2][BLOCK_SIZE/2];
申请空间后,即将对应的元素赋值到对应的shared memory中即可:
idx = row * n + sub * BLOCK_SIZE + threadIdx.x;
tile_a[threadIdx.y][threadIdx.x] = row < m &&(sub * BLOCK_SIZE + threadIdx.x)<n?d_a[idx]:0;
idx = (sub * BLOCK_SIZE + threadIdx.y) * k + col;
tile_b[threadIdx.y][threadIdx.x] = col<k && (sub * BLOCK_SIZE + threadIdx.y)<n? d_b[idx]:0;
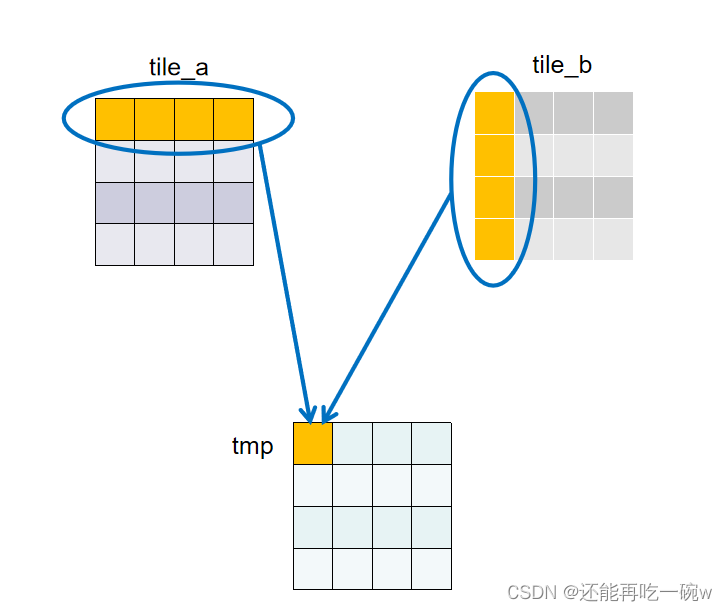
接下来的__syncthreads();本人认为则是理解gpu并行计算极为重要的一步,该函数的作用为等待所有线程执行完毕。由于一个线程只需要负责一处shared memory的赋值,且一个block共享一个shared memory,因此这一步执行完毕后,一个block中的shared memory才算是完全的将矩阵M和矩阵N对应的元素提取出来了。下图所示为sub=0时提取的shared memory。
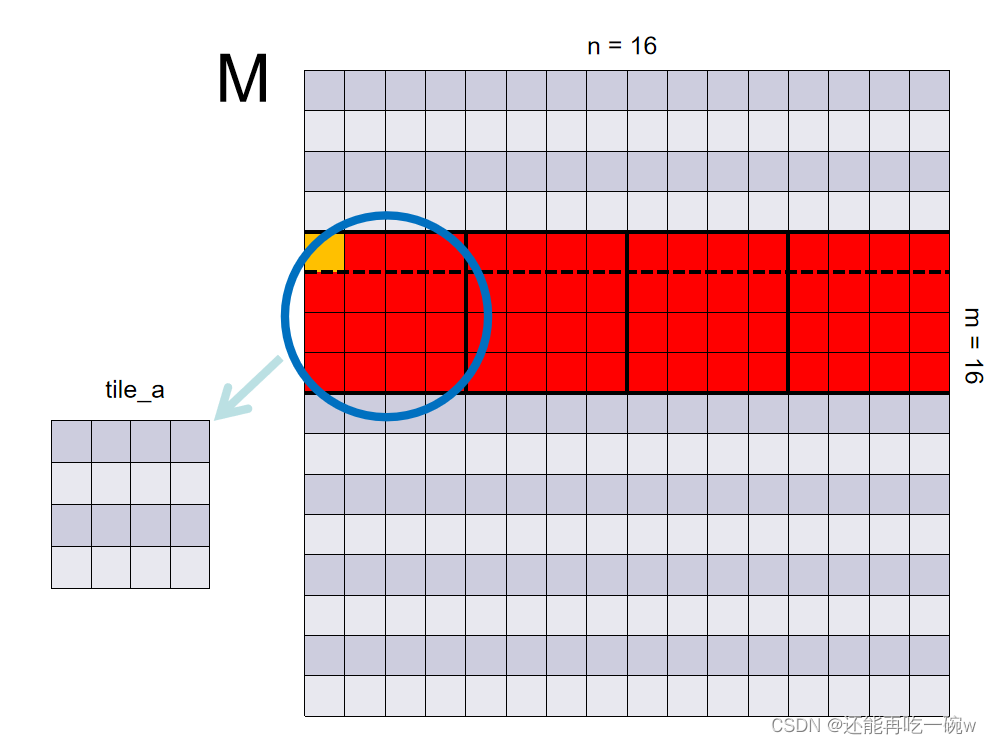
之后即可提取shared memory中的值进行对应相乘再相加,得到了公式中第一次滑动部分的结果。
for(int i = 0; i < BLOCK_SIZE; ++i){
tmp+= tile_a[threadIdx.y][i] * tile_b[i][threadIdx.x];
}
接下来依旧是__syncthreads();,目的为等待所有线程的第一次滑动计算结束。
之后依次计算第二次滑动、第三次滑动……,再将tmp累加即可得到最后的值。最终将得到的值赋给最后的结果。
if(row < m && col < k){
d_result[row * k + col] = tmp;
}

















 2309
2309




 到【灌水乐园】发言
到【灌水乐园】发言







