




hadoop 的四大组件:
HDFS:分布式存储系统
MapReduce:分布式计算系统
YARN: hadoop 的资源调度系统
Common: 以上三大组件的底层支撑组件,主要提供基础工具包和 RPC 框架等
HDFS:是hadoop的文件系统。基于HDFS,你可以对文件进行操作,例如新建,删除,编辑,重命名等。HDFS(Hadoop Distributed File System)是Hadoop实现的一个分布式文件系统。它存储 Hadoop 集群中所有存储节点上的文件。对外部客户机而言,HDFS 就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。但是 HDFS 的架构是基于一组特定的节点构建的,存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小(通常为 64MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
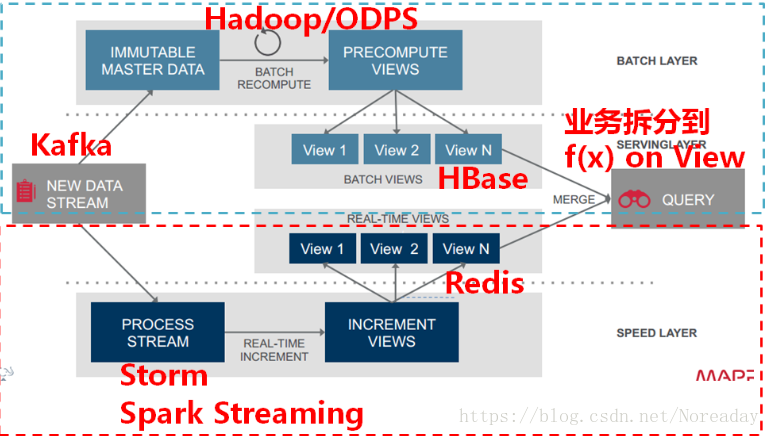
Lambda架构:https://blog.youkuaiyun.com/brucesea/article/details/45937875

















 2243
2243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









