




引言:
- 介绍Java编程中常见的中文乱码问题
- 乱码问题可能给开发者带来的挑战和困扰
- 本文旨在分析问题原因并提供明确的解决方案
第一部分:乱码产生的原因
在编程世界里,字符编码像是一座隐形的桥梁,连接着人类的语言和计算机的二进制世界。然而,当这座桥梁出现了问题,就会导致我们在屏幕上看到一串串令人费解的字符——这就是我们所说的“乱码”。在Java的世界里,中文乱码尤其像是一块绊脚石,让无数开发者头疼不已。那么,乱码是如何产生的呢?让我们从多个角度来探索这个问题。
文化角度:编码的历史
在计算机还未出现的年代,人们通过书信和口头传达信息。而在计算机发明之后,我们需要一种方法将文字转化为计算机能理解的形式。最初,人们创建了ASCII码来表示英文字符,它仅需要7位二进制就能表示一个字符。但是,随着计算机的全球普及,这种方法显然无法涵盖世界上所有的语言,尤其是那些拥有大量字符的语言,比如中文。
技术角度:字符编码基础
为了解决这个问题,国际上制定了一系列的编码标准,其中最著名的当属Unicode。Unicode旨在为世界上所有的字符提供一个唯一的数字表示。在Unicode之下,还有不同的实现方式,比如UTF-8、UTF-16等。UTF-8是一种变长的编码方式,它能够使用1到4个字节来表示一个字符,这使得它能够高效地表示英文字符,同时也能够表示包括中文在内的其他语言的字符。
实践角度:常见乱码场景分析
在Java开发实践中,中文乱码通常出现在以下几个场景:
- 文件读写:如果在读取或写入文件时没有指定正确的编码格式,中文字符可能会变成乱码。
- 网络传输:当数据在网络上传输时,如果客户端和服务器端的编码设置不一致,也会产生乱码。
- 数据库存取:在存储或检索数据库中的中文数据时,如果数据库的编码设置不正确,同样会遇到乱码问题。
这些场景都涉及到编码的转换和匹配问题。在Java中,如果不注意相关的编码设置和转换,就很容易在数据流转换过程中遇到乱码问题。
第二部分:Java中处理中文乱码的挑战
想象一下,你辛苦编写了一个精美的Java程序,运行后却发现,期待中的中文输出变成了一串让人头疼的“???”或者一些奇特的符号。这不仅影响了程序的用户体验,更是给开发者带来了调试上的困扰。那么,在Java编程中,中文乱码问题具体会在哪些场景中出现呢?让我们一起来揭开乱码产生的神秘面纱。
遭遇乱码的典型场景
在Java中,处理字符串时不可避免地会与编码打交道。以下列举了几个常见的乱码场景:
- 文件读取和写入:当你尝试读取或保存一个包含中文字符的文件,如未指定正确的编码,结果通常会令人沮丧。
- 控制台输出:在不同操作系统下,控制台默认的编码可能不一样,直接使用System.out.println输出中文时,可能会出现乱码。
- Web应用开发:在Servlet和JSP中,处理中文输入和输出时,如果请求和响应的编码没有正确设置,就会产生乱码。
- 数据库操作:数据库和JDBC的连接没有配置适当的字符集,或者在SQL查询中未正确处理编码,这些都可能导致中文显示为乱码。
1.文件读取和写入
文件读写是最常见的乱码场景之一。当文件的保存编码与读取编码不一致时,就会出现乱码。
示例:
保存文件时使用GBK编码,读取时却使用UTF-8编码。
import java.io.*;
public class FileEncodingMismatch {
public static void writeFile(String text, String charsetName) throws IOException {
try (OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("example.txt"), charsetName)) {
writer.write(text);
}
}
public static String readFile(String charsetName) throws IOException {
StringBuilder content = new StringBuilder();
try (InputStreamReader reader = new InputStreamReader(new FileInputStream("example.txt"), charsetName)) {
char[] buffer = new char[1024];
int len;
while ((len = reader.read(buffer)) != -1) {
content.append(new String(buffer, 0, len));
}
}
return content.toString();
}
public static void main(String[] args) throws IOException {
String text = "您好,我是Neoest";
// 以GBK编码保存文件
writeFile(text, "GBK");
// 尝试以UTF-8编码读取文件
String result = readFile("UTF-8");
System.out.println(result); // 输出乱码
}
}
解决方案:读写编码保持一致。
public static void main(String[] args) throws IOException {
String text = "您好,我是Neoest";
// 以GBK编码保存文件
writeFile(text, "UTF-8");
// 尝试以UTF-8编码读取文件
String result = readFile("UTF-8");
System.out.println(result); // 输出乱码
}
2.控制台输出
看下面这个例子,在我们的idea编辑器中,明明是很正常一段话,但是在打印到控制台之后会出现乱码呢;
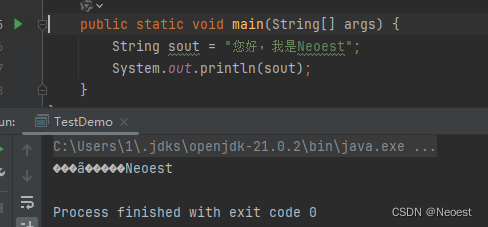
问题原因及解决方案:
1. 控制台默认编码设置:IDEA 控制台的默认编码可能与程序输出的编码不匹配。例如,如果程序输出是 UTF-8 编码,而控制台默认设置为其他编码(如 CP1252 或 GBK),那么中文字符可能会显示为乱码。
解决方案: 选择左上脚的“File” > “Settings” (Mac 上为 “IntelliJ IDEA” > “Preferences”)在打开的界面中输入"File Encodings",设置 “Global Encoding” 和 “Project Encoding” 为 UTF-8。

2. 项目文件编码设置:IntelliJ IDEA 允许您为每个项目单独设置文件编码。如果项目文件编码与您程序中用于字符串的编码不一致,那么输出到控制台的字符串可能会出现乱码。
解决方案: 选择左上脚的“File” > “Settings” (Mac 上为 “IntelliJ IDEA” > “Preferences”)在打开的界面中输入"File Encodings" 查看到当前文件被设置为GBK。
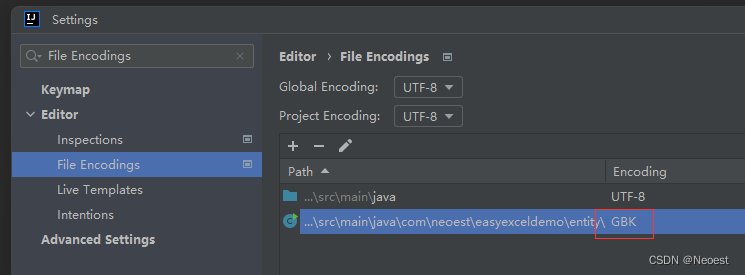
注:(当前文件的编码格式可以在右下角快捷选择),选择编码后按“convert”转换(强烈建议转换之前将当前文件拷贝出去,转换完毕文件格式之后再复制回来。)
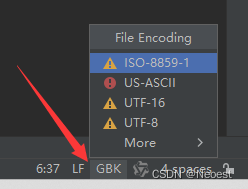
本文当中示例控制台乱码既是此处的问题。两者编码一致后问题解决。
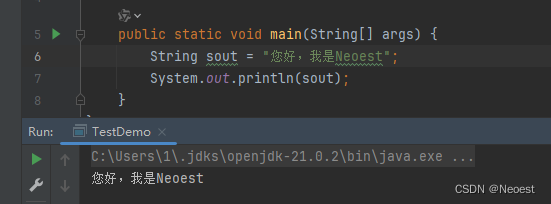
方案二、
3. 系统默认编码:在某些情况下,IDEA 控制台会使用操作系统的默认字符编码。如果操作系统的编码设置不是 UTF-8(尤其在 Windows 系统中),这可能会导致控制台输出乱码。
以windows为例,打开命令提示符。你可以在搜索栏输入 cmd 并回车来打开它,输入命令 chcp 并按回车
Active code page: 936
代码页 936 是用于简体中文字符的代码页,对应于 GBK 编码,而代码页 65001 表示 UTF-8 编码。如何设置还请自行搜索/
MacOS与linix教程还请自行搜索。
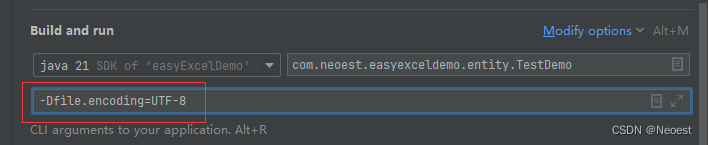
4. JVM 默认编码:Java 虚拟机(JVM)在没有明确指定编码的情况下,会使用系统默认编码来转换字节到字符。如果 JVM 的默认编码和程序输出编码不一致,可能导致乱码。
解决方案:
Web应用开发中的乱码
Web应用中的乱码通常发生在客户端与服务器交互过程中,特别是在HTTP请求和响应时。
示例:
在Servlet中,如果没有设置正确的请求和响应编码,就可能出现乱码。现在绝大多数框架中都架构师在设计系统时都考虑了编码统一管理。此处不做赘述。
@WebServlet("/greeting")
public class GreetingServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("UTF-8"); // 设置请求编码
response.setCharacterEncoding("UTF-8"); // 设置响应编码
response.setContentType("text/html;charset=UTF-8"); // 设置内容类型和字符集、
response.getWriter().write("您好,我是Neoest");
}
}
数据库操作中的乱码
如果数据库或JDBC连接没有使用正确的字符集配置,那么在插入和查询中文数据时就会出现乱码问题。
示例:
以下是JDBC连接MySQL数据库时,可能出现的乱码问题。
public class DatabaseEncoding {
public static void main(String[] args) throws SQLException {
String url = "jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=UTF-8";
try (Connection conn = DriverManager.getConnection(url, "username", "password")) {
try (Statement stmt = conn.createStatement()) {
// 插入中文数据
String sqlInsert = "INSERT INTO mytable (content) VALUES ('您好,我是Neoest')";
stmt.executeUpdate(sqlInsert);
// 查询中文数据
String sqlSelect = "SELECT content FROM mytable WHERE id = 1";
try (ResultSet rs = stmt.executeQuery(sqlSelect)) {
if (rs.next()) {
String content = rs.getString("content");
System.out.println(content); // 如果字符集设置不正确,此处可能输出乱码
}
}
}
}
}
}
国际化和本地化问题
在多语言支持的应用程序中,如果没有正确处理国际化(i18n)和本地化(l10n)相关的编码问题,可能导致某些语言出现乱码。
解决方案:使用Unicode编码(如UTF-8)并确保整个应用程序的国际化流程支持此编码。
在每个场景中,我们都看到了中文乱码可能发生的情况和具体的代码示例。了解这些场景有助于我们在实际工作中预防和快速解决编码问题,保证数据的正确表示和传输。
第三部分:工具和资源
当处理编码问题时,有一些工具和资源可以大大简化我们的工作。无论你是开发人员还是内容创建者,以下是一些可以帮助你正确处理字符编码的工具和资源。
编码转换工具
- Notepad++: 一个流行的文本编辑器,提供了转换文件编码的功能,非常适合检查和修改文件的编码。
- iconv: 一个命令行程序,可以在不同的编码之间转换文本文件的编码。在 Linux 和 macOS 上通常预安装,也可以在 Windows 上使用。
- 在线编码转换器: 如 “Convert Encoding” 网站,允许你上传文件并将其编码从一种转换为另一种。
字符集检测工具
- chardet: 是一个字符编码检测库,可以通过命令行或作为库集成在你的项目中。它支持多种语言的绑定,包括 Python 的 chardet 模块。
开发库和API
- Unicode Consortium: 提供了关于 Unicode 标准的完整文档和各种字符的代码点信息。
- International Components for Unicode (ICU): 一个成熟的、广泛使用的 Unicode 和国际化支持库,提供了丰富的 API,适用于各种编程语言。
正确地处理编码是确保软件国际化和本地化成功的关键。利用这些工具和资源,你可以确保你的应用程序能够无缝地处理全球用户的数据,并避免乱码问题的发生。
第四部分:结语
随着我们深入探讨了编码的复杂世界,我们发现了一些关键的概念和实用的工具,它们是理解和处理字符编码问题的基石。从代码页的选择到编码转换的细微差别,再到国际化的实践,我们已经涵盖了编码领域的多个方面。
尽管编码问题可能看起来令人生畏,但凭借正确的知识和工具,它们是可以被理解和解决的。重要的是要始终保持好奇心,并且愿意去探索和学习新的技术和方法。
我希望这篇博客能够作为一个有价值的资源,帮助你在编码的旅途中导航。无论你是在调试一个棘手的字符显示问题,还是在努力使你的应用更好地支持多种语言,记住:耐心和持续的学习是你最好的伙伴。
最后,别忘了分享你的经验和学习。在处理编码问题的过程中,社区支持是不可或缺的。参与讨论,贡献你的见解,你不仅能帮助自己,也能帮助到他人。
祝你在编码的世界中旅途愉快,期待在字符的海洋里与你相遇!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











