





1. 数据集显示
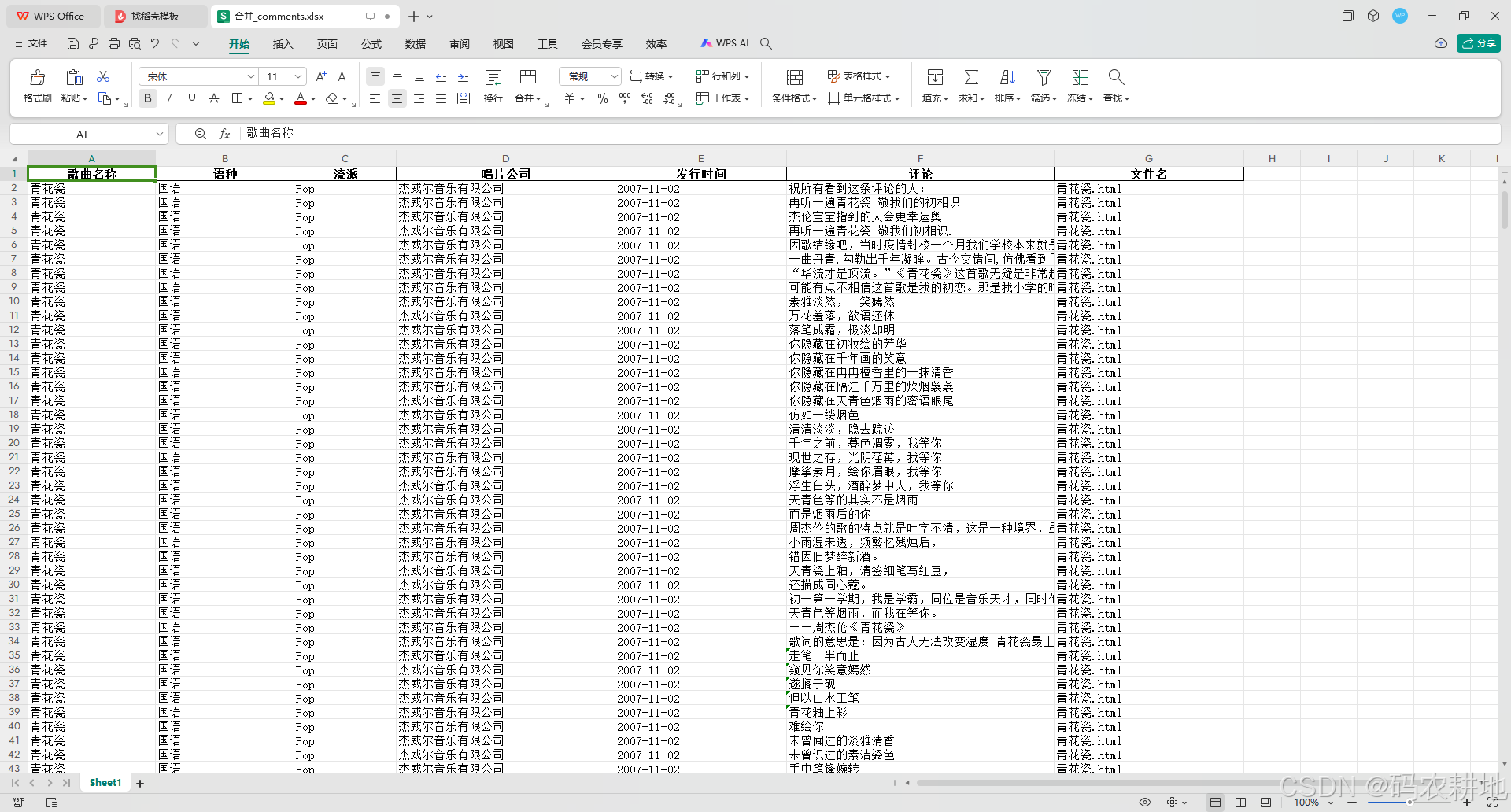
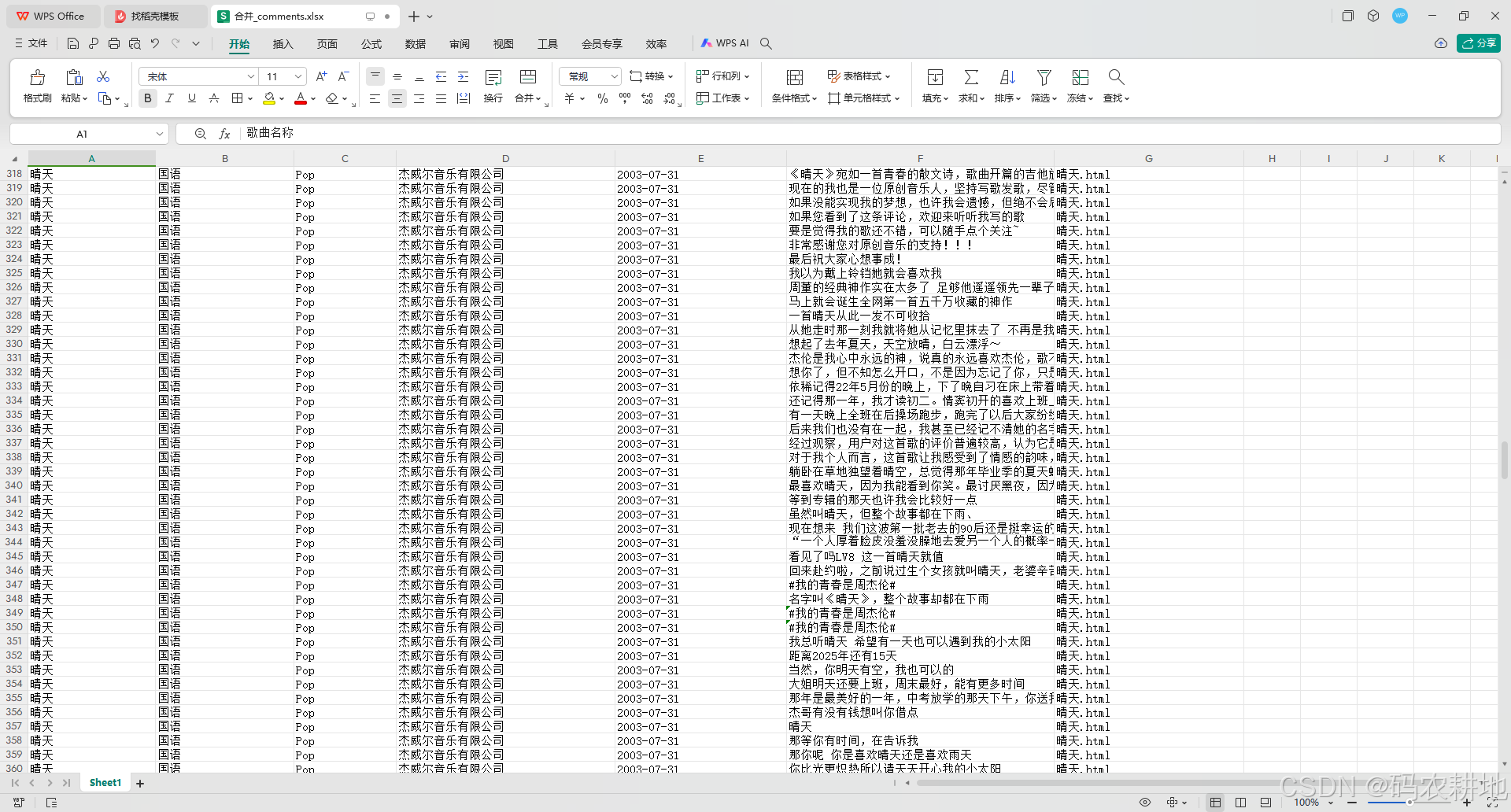
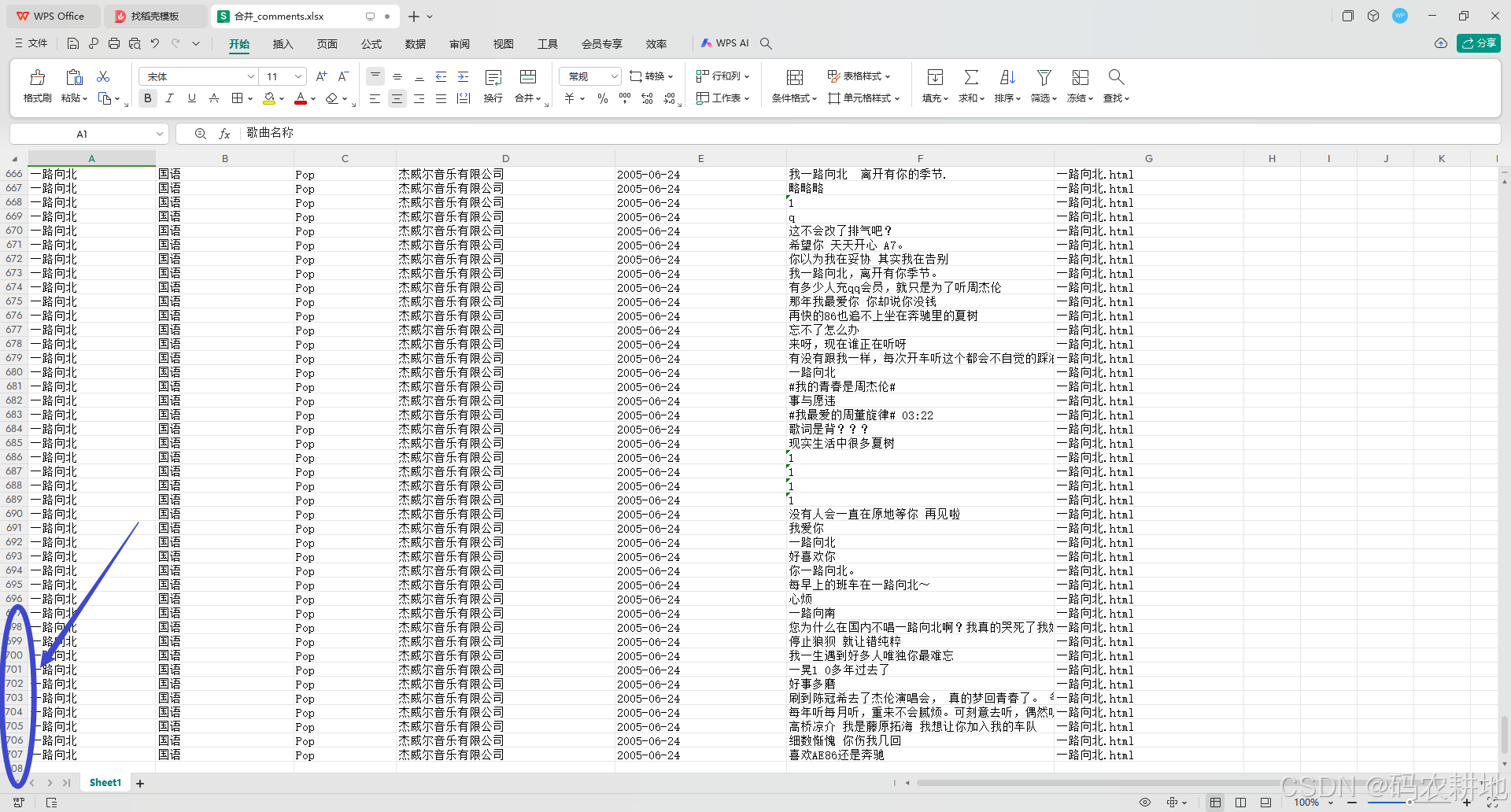

2. 代码结构分析
1. 文件头部与模块引入
from lxml import etree
import pandas as pd
import os
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
-
模块功能:
lxml.etree:解析 HTML 文件。pandas:存储和操作表格数据。os:处理文件路径。jieba:中文分词工具。collections.Counter:统计词频。wordcloud:生成词云。matplotlib.pyplot:可视化工具。
-
全局配置:
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False- 设置字体和负号显示,确保在生成图表时支持中文和符号。
2. HTML 文件解析与评论提取
combined_df = pd.DataFrame()
- 目标文件:指定了多个 HTML 文件作为数据源,文件路径存储在
file_paths列表中。 - 数据合并表:使用
pandas.DataFrame()初始化一个空表,用于存储解析结果。
2.1 文件读取与解析
with open(file_path, 'r', encoding='utf-8') as file:
html_content = file.read()
tree = etree.HTML(html_content)
- 逐一读取文件内容,使用
lxml.etree.HTML解析 HTML 结构。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









