



1. **Model Mixture(模型混合)**
- **含义**:在联邦学习中,不同客户端的模型可能会被混合或融合,以生成一个更通用的全局模型。这种技术可以用于处理客户端之间的异质性。
- **应用场景**:当不同客户端的数据分布差异较大时,模型混合可以帮助平衡全局模型的性能。
2. **Knowledge Distillation(知识蒸馏)**
- **含义**:一种模型压缩技术,将一个复杂模型(教师模型)的知识迁移到一个更简单的模型(学生模型)中。在联邦学习中,可以用于优化模型的大小和性能。
- **应用场景**:在资源受限的设备(如移动设备)上部署模型时,知识蒸馏可以帮助减少模型的计算和存储需求。
3. **Regularization(正则化)**
- **含义**:一种防止模型过拟合的技术,通过在损失函数中加入正则项来约束模型的复杂度。在联邦学习中,正则化可以帮助模型更好地泛化到不同客户端的数据。
- **应用场景**:当客户端数据量较小时,正则化可以防止模型过拟合。
4. **Personalized Behaviors (Client-Side)(客户端个性化行为)**
- **含义**:允许每个客户端根据自己的数据和需求调整模型,以实现个性化。
- **应用场景**:不同客户端可能有不同的用户行为模式,客户端个性化行为可以更好地适应这些差异。
5. **Meta-Learning(元学习)**
- **含义**:一种让模型学会“如何学习”的技术,通过在多个任务上训练模型,使其能够快速适应新任务。在联邦学习中,元学习可以帮助模型更好地适应不同客户端的任务。
- **应用场景**:当客户端的任务差异较大时,元学习可以帮助模型快速适应新任务。
6. **Model Decoupling(模型解耦)**
- **含义**:将模型的不同部分分离,以便更好地处理客户端之间的异质性。例如,可以将特征提取部分和分类部分分开,分别进行优化。
- **应用场景**:当客户端的数据特征差异较大时,模型解耦可以帮助更好地优化模型。
7. **PFL(Personalized Federated Learning,个性化联邦学习)**
- **含义**:一种联邦学习的变体,专注于为每个客户端生成个性化的模型,而不是一个通用的全局模型。
- **应用场景**:当客户端之间的数据分布差异较大时,PFL可以更好地满足每个客户端的需求。
8. **Clustering(聚类)**
- **含义**:将客户端分组,使得同一组内的客户端具有相似的数据分布。这样可以更好地优化全局模型。
- **应用场景**:当客户端数量较多且数据分布差异较大时,聚类可以帮助更好地管理客户端。
9. **Multi-task Learning(多任务学习)**
- **含义**:让模型同时学习多个任务,以提高模型的泛化能力和效率。在联邦学习中,多任务学习可以帮助模型更好地处理不同客户端的任务。
- **应用场景**:当客户端有多个任务需求时,多任务学习可以提高模型的性能。
10. **Personalized Behaviors (Server-Side)(服务器端个性化行为)**
- **含义**:服务器可以根据客户端的反馈和数据,调整全局模型以实现个性化。
- **应用场景**:服务器可以根据客户端的性能反馈,优化全局模型,以更好地满足客户端的需求。
11. **Biased Sampling(有偏采样)**
- **含义**:在数据采样时,根据某些标准(如数据分布或任务需求)进行有偏采样,以优化模型性能。
- **应用场景**:当某些客户端的数据更重要时,有偏采样可以帮助更好地优化模型。
参数样例解释:
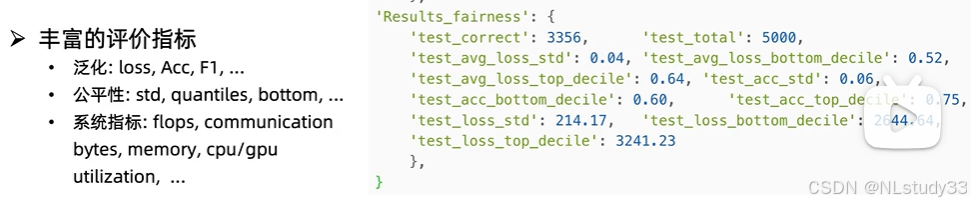
这是一个关于模型公平性(fairness)的测试结果的字典。以下是对每个键值对的详细解释:
### **测试结果字典**
1. **'test_correct'**:
- **含义**:测试集中正确预测的样本数量。
- **值**:3356
2. **'test_total'**:
- **含义**:测试集中的总样本数量。
- **值**:5000
3. **'test_avg_loss_std'**:
- **含义**:测试集上平均损失的标准差,用于衡量损失的离散程度。
- **值**:0.04
4. **'test_avg_loss_bottom_decile'**:
- **含义**:测试集上平均损失的底部十分位数(即最小的10%的平均损失)。
- **值**:0.52
5. **'test_avg_loss_top_decile'**:
- **含义**:测试集上平均损失的顶部十分位数(即最大的10%的平均损失)。
- **值**:0.64
6. **'test_acc_std'**:
- **含义**:测试集上准确率的标准差,用于衡量准确率的离散程度。
- **值**:0.06
7. **'test_acc_bottom_decile'**:
- **含义**:测试集上准确率的底部十分位数(即最小的10%的准确率)。
- **值**:0.60
8. **'test_acc_top_decile'**:
- **含义**:测试集上准确率的顶部十分位数(即最大的10%的准确率)。
- **值**:0.75
9. **'test_loss_std'**:
- **含义**:测试集上损失的标准差,用于衡量损失的离散程度。
- **值**:214.17
10. **'test_loss_bottom_decile'**:
- **含义**:测试集上损失的底部十分位数(即最小的10%的损失)。
- **值**:2644.64
11. **'test_loss_top_decile'**:
- **含义**:测试集上损失的顶部十分位数(即最大的10%的损失)。
- **值**:3241.23
### **总结**
这个字典提供了模型在测试集上的公平性测试结果,包括正确预测的数量、总样本数量、平均损失和准确率的标准差、底部和顶部十分位数。这些指标可以帮助评估模型在不同子群体上的表现差异,从而判断模型的公平性。

















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









