




在robotframework当中,要实现web自动化,则需要使用SeleniumLibrary这个库。
目前版本中,有180+关键字。随着版本的更新,关键字的个数和名字也会有所变动。
在网上没有找到较为全面的关于这个库的关键字介绍,所以此篇文章按照关键字类别,列举常用的关键字,作为参考工具。
1、SeleniumLibrary的安装:
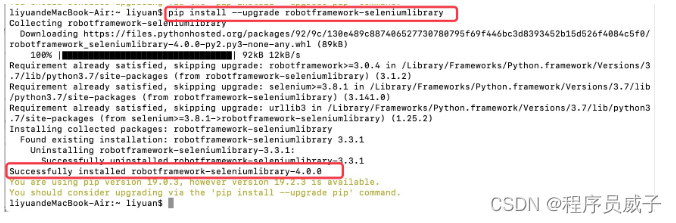
前提:已安装好python环境并配置好环境变量。然后在命令行当中,运行以下命令:
pipinstall--upgraderobotframework-seleniumlibraryAI写代码
2、SeleniumLibrary结构、和Selenium的关系
SeleniumLibrary是一个python第三方库(存放在python安装目录下的Lib/site-packages/SeleniumLibrary)。它的结构如下,其中keywords目录下存放的是关键字。
在源码中,是分门别类的来存放关键字。包括alert弹框、表格/select/iframe等元素操作、等待、窗口等。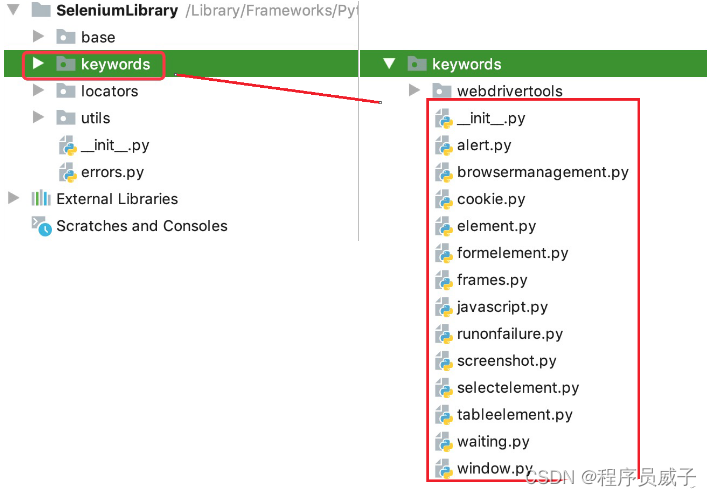
SeleniumLibrary的源代码中,很多地方都直接使用了selenium的API来封装网页的操作,可以说是在selenium之上,封装了更多的元素操作关键字,提供给robot框架的使用者。毕竟有现成的“轮子”,就没有必要再重新造了。
比如上图中elment.py当中的鼠标操作。在selenium当中,ActionChains类是用来专门实现鼠标操作的。
以元素双击操作为例,如果使用python+selenium库来实现双击操作,需要以下代码
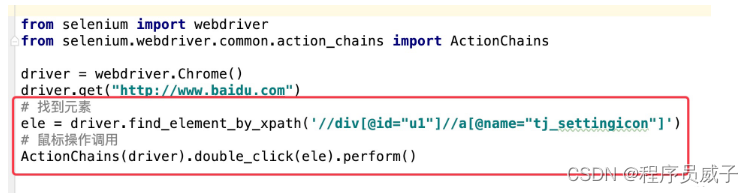
在SeleniumLibrary当中,关键字**double click element** 就将元素和鼠标双击操作封装在一起。只要传入元素定位即可(如下图所示)。

3、SeleniumLibrary关键字分类解读
1) 引入SeleniunLibrary库时,初始化参数
SeleniumLibrary在robotframework当中,引入时会将SeleniumLibrary这个类初始化。
初始化的参数是对所有关键字生效的。

**Timeout:**等待超时时间。关键字当中有timeout参数的,都使用此处的默认值,5秒。
**Timeout:**等待超时时间。关键字当中有timeout参数的,都使用此处的默认值,5秒。
Implicit wait: 隐性等待时长。0.0表示没有隐性等待。
run on failure: 关键字运行失败时的动作。Capture Page Screenshot是截取页面图片的关键字。表示运行失败时,自动截取当前网页图片, 即失败时自动截图功能。
Screenshot root directory: 截取的网页图片存放路径 。None表示不指定路径 ,默认与输出文件同目录。
我们在robot当中引入SeleniumLibrary时,可以修改默认参数值。比如修改默认timeout为15s

2)元素定位语法:
在web自动化当中,有8大定位方式。无论用什么样的语言/框架,定位方式都是通用的。
在robot框架当中,定位语法有以下2种表达方式:
定位策略:定位表达式(比如 id:kw)
定位策略=定位表达式(比如 id=kw)
在robot当中,除了8大定位方式以外,还额外扩展了几种,整体的定位方式如下(摘抄自官方文档):
| 定位策略 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1884
1884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









