




💕"你笑的次数越多越好,因为你只有用笑才能不怀恶意地消灭罪恶。"💕
作者:Mylvzi
文章主要内容:数据结构之单链表的模拟实现

一.前言:
在上个顺序表的博客结尾针对ArrayList的缺陷留了一个思考题
![]()
大家可以去再看一下顺序表这篇博客https://blog.youkuaiyun.com/Mylvzi/article/details/133896470?spm=1001.2014.3001.5501
因为ArrayList的底层是一段连续内存的空间,进行插入/删除操作的开销很大,因此ArrayList不适合用于"需要大量添加/删除数据的场景",因此Java中又引入了LinkedList,即链表结构
二.链表
1.链表的概念及结构
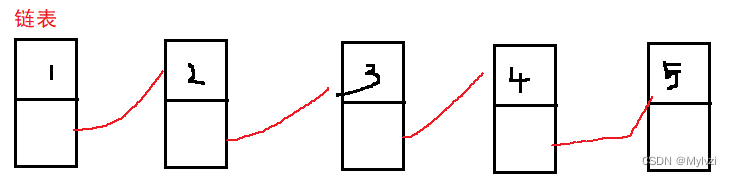
链表是物理地址不连续的线性表,逻辑顺序是通过"链条"连接起来的
可以将链表想象成拉着很多节车厢的火车
注意:
1.链表是由一个个结点(Node)组成的,每个结点都是从堆上申请的
2.堆为每个结点分配内存地址,分配时是随机的,所以链表的物理结构是不连续的
链表的分类:
按照不同的性质可以有多种分类方法:
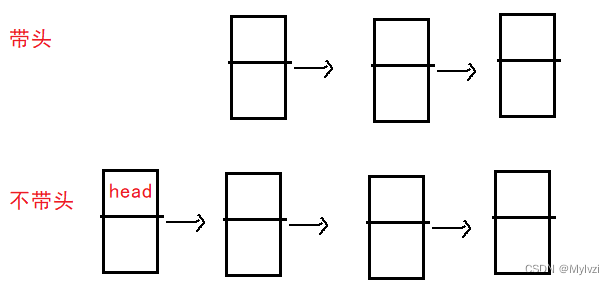
- 按照是否有"头节点":带头和不带头
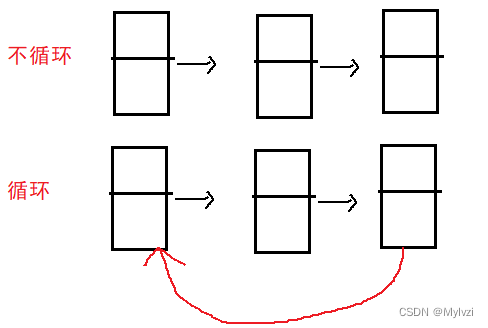
- 按照是否循环:循环和不循环
- 按照链表逻辑的方向:单向和双向
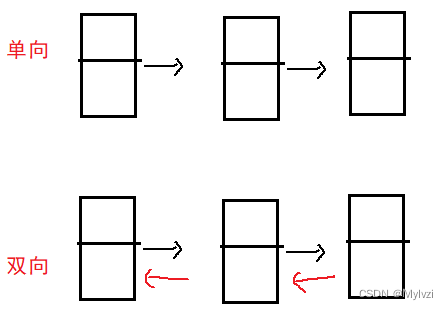
综上,链表可分为2 * 2 * 2 = 8种,在这里我们只需重点掌握两种链表即可
- 无头单项非循环链表 面试常考
- 无头双向非循环链表 Java中LinkedList的底层就是一个无头双向非循环链表
注意:这里说的"有无头节点"中的头节点不属于链表中的有效数据,他更像是一个“傀儡节点”,仅仅作为前驱使用
三.无头单向非循环链表的实现
1.链表的结构
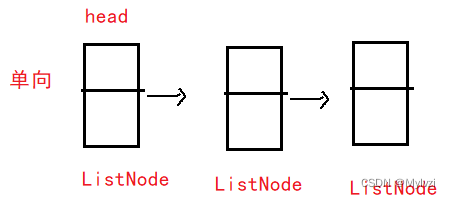
// 定义结点
static class ListNode {
int val;// 结点存储的数据
ListNode next;// 保存下一个结点的地址
public ListNode(int val) {
this.val = val;
}
}
// 定义头节点
public ListNode head = null;2.链表的插入
因为链表的物理地址并不是连续的,所以我们插入数据的位置是多样性的,总的来说可以分为三种
- 头插法:addFirst
- 尾插法:addLast
- 任意位置插入:addIndex
1.头插法
头插法及创建一个新的结点,将此结点插入到第一个结点之前
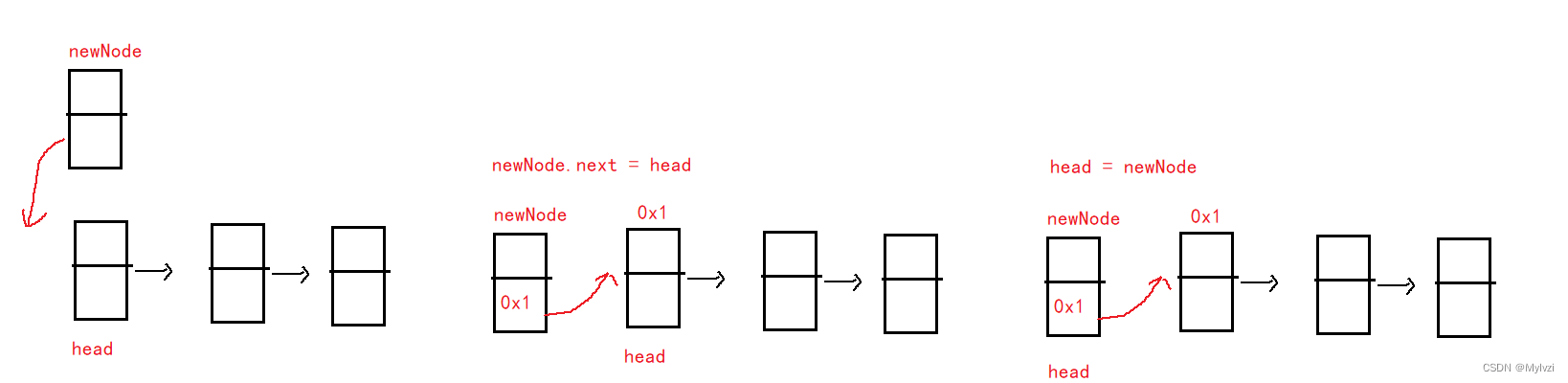
public void addFirst(int data) {
ListNode newNode = new ListNode(data);
// 头插法不需要考虑链表是否为空
newNode.next = head;
head = newNode;
}注意:
在链表中插入/删除数据时,最重要的一点是记得保存"下一节点",往往是先连接后面的结点,在进行其他的操作(如果不先连接后面的结点就会损失后面的所有节点火车一节车厢断开,则后面的车厢都断开了)
2.尾插法
尾插法即在链表的末尾添加一个新的结点
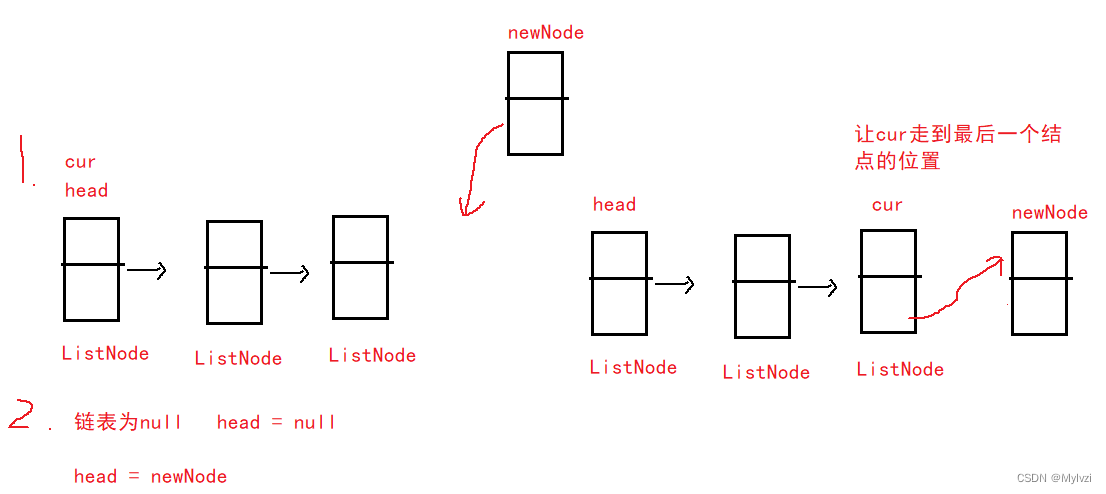
public void addLast(int data) {
ListNode newNode = new ListNode(data);
// 如果为空 链表中没有一个节点 直接插入
if(head == null) {
head = newNode;
return;
}
ListNode cur = head;
// 让cur走到链表的最后一个节点
while (cur.next != null) {
cur = cur.next;
}
cur.next = newNode;
}3.任意位置插入
给指定的位置index,在指定位置插入一个节点(第一节点对应的index为0)
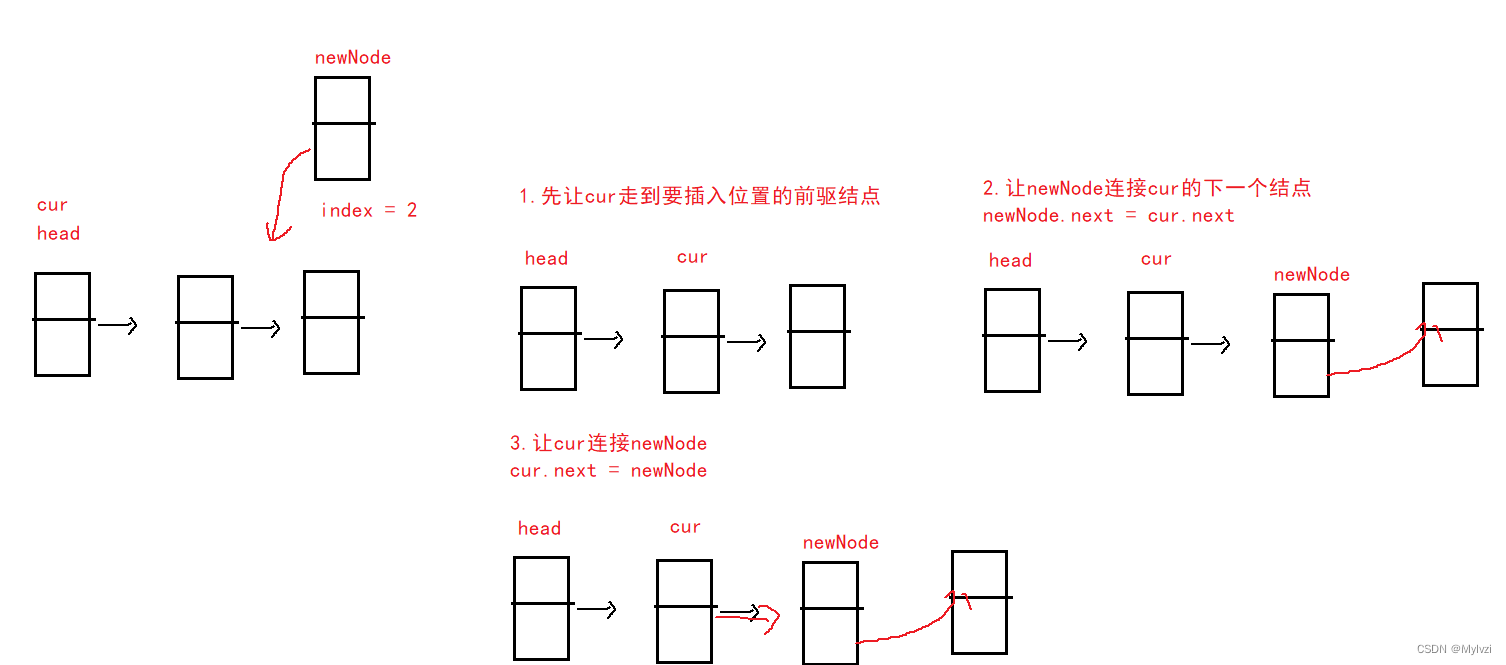
public void addIndex(int index,int data) {
// 先检查index是否合法
if(index < 0 || index > size()) {
throw new posOutOfBoundException(index + "位置不合法");
}
if (index == 0) addFirst(data);
if (index == size()) addLast(data);
// 让cur走到要删除结点的前驱节点 走index - 1步
ListNode cur = head;
for (int i = 0; i < index-1; i++) {
cur = cur.next;
}
ListNode newNode = new ListNode(data);
newNode.next = cur.next;
cur.next = newNode;
}3.查找是否包含关键字key的结点
// 判断是否包含
public boolean contains(int key) {
ListNode cur = head;
while (cur != null) {
if (cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
}4.求链表的长度
// 返回长度
public int size() {
ListNode cur = head;
int cnt = 0;// 设置计数器
while (cur != null) {
cnt++;
cur = cur.next;
}
return cnt;
}5. 删除第一次出现关键字为key的节点
要进行此删除操作,关键还是要在删除对应节点之后仍然连接之后的结点
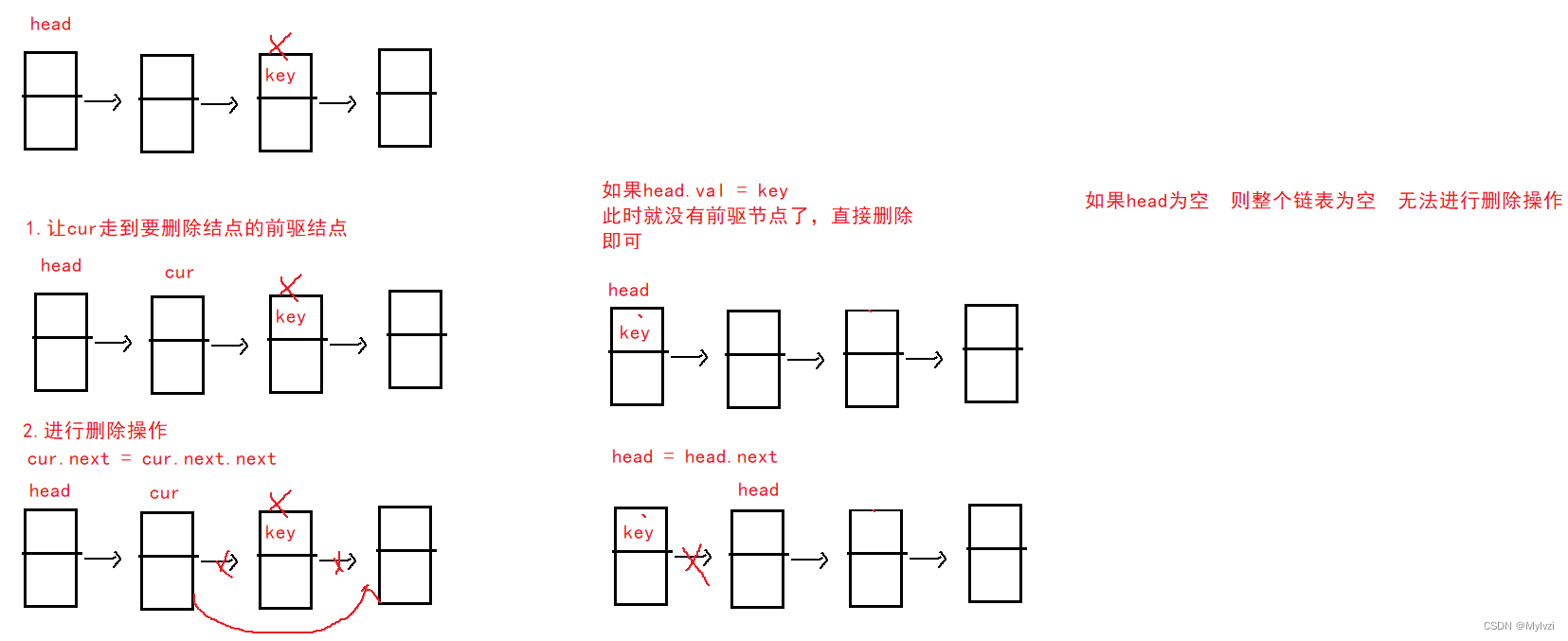
public void remove(int key) {
if(head == null) {
throw new RuntimeException("链表为空 无法删除");
}
if (head.val == key) {
head = head.next;
return;
}
// 让cur走到要删除节点的前驱节点
ListNode cur = findPrevNode(key);
if(cur == null) {
System.out.println("没有你要删除的结点");
return;
}
cur.next = cur.next.next;
}
// 找要删除结点的前驱结点
private ListNode findPrevNode(int key) {
ListNode cur = head;
while (cur != null) {
if (cur.next.val == key) {
return cur;
}
cur = cur.next;
}
return null;
}6.删除所有值为key的节点
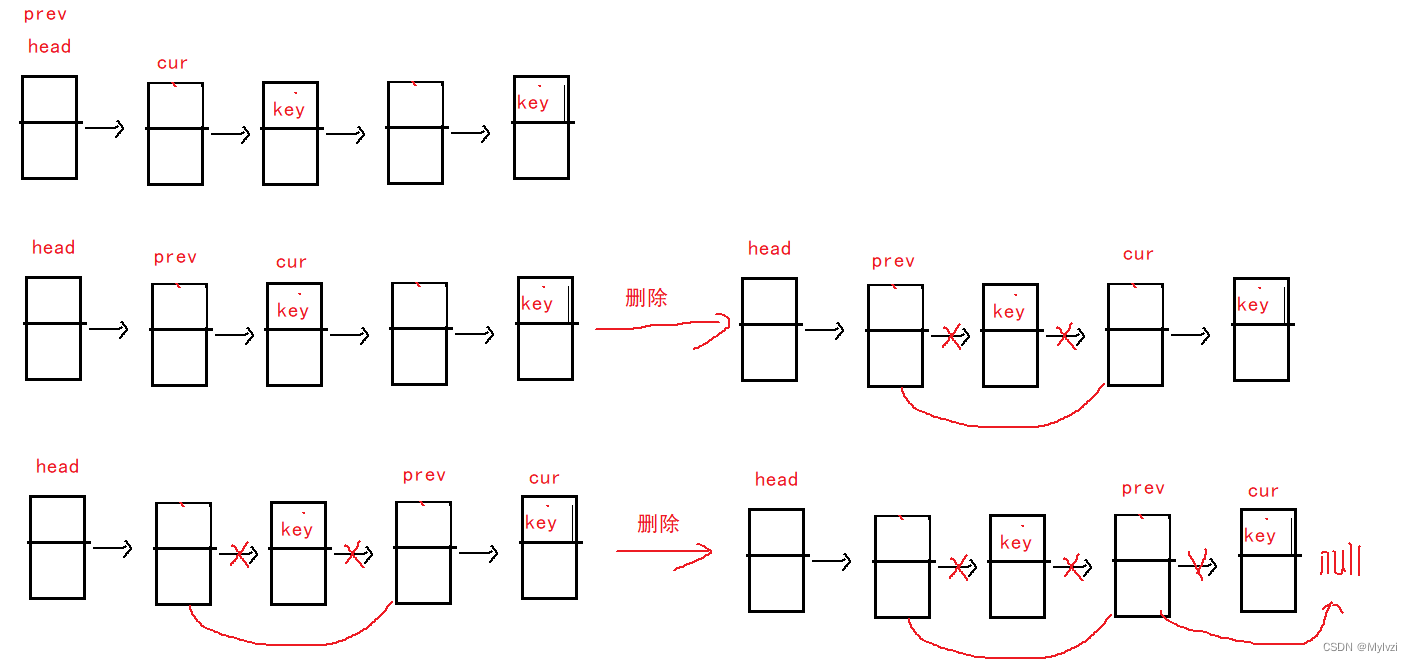
public void removeAll(int key) {
if(head == null) {
throw new RuntimeException("链表为空 无法删除");
}
// 处理头节点是key的情况
while (head.val == key) {
head = head.next;
}
// 设置两个结点 前驱节点prev 和用于遍历的结点cur
ListNode prev = head;
ListNode cur = head.next;
while (cur != null) {
// 等于 进行删除
if (cur.val == key) {
prev.next = cur.next;
cur = cur.next;
continue;
}
prev = prev.next;
cur = cur.next;
}
}注意考虑当头节点是要删除的结点
7.链表的打印
// 打印链表
public void display() {
// 要始终保持head结点是头节点 此处使用一个临时结点cur用于遍历整个链表
ListNode cur = head;
while (cur != null) {
System.out.print(cur.val);
cur = cur.next;
}
}四.LinkedList
1.什么是LinkedList
LinkedList是Java中使用双向链表实现的一中数据结构,每个节点都含有三个属性:
- elem:存储元素的值
- next:保存当前节点的下一个结点
- prev:保存当前结点的上一个结点
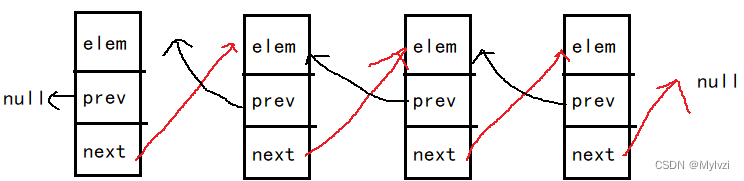
在集合框架中,LinkedList也实现了List接口

说明:
1.LinkedList没有实现RandomAccess接口,因此LinkedList不支持随机访问
2.LinkedList适合用于大量进行数据增加/删除的操作
2.LinkedList的模拟实现
1.LinkedList的结构
LinkedList是一个双向的链表,且有两个"标记结点"head,last,分别用于标记链表的头/尾
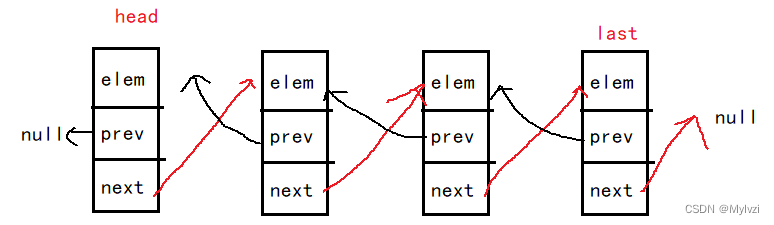
2.代码实现
public class MyLinkedList {
static class ListNode {
private int data;
private ListNode prev;
private ListNode next;
public ListNode(int data) {
this.data = data;
}
}
public ListNode head;
public ListNode last;
/**
* 前三个方法和prev没关系
* 只需遍历整个链表即可
* @return
*/
//得到单链表的长度
public int size(){
int cnt = 0;
ListNode cur = head;
while (cur != null) {
cnt++;
cur = cur.next;
}
return cnt;
}
// 打印链表
public void display(){
ListNode cur = head;
while (cur != null) {
System.out.print(cur.data + " ");
cur = cur.next;
}
System.out.println();
}
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key){
ListNode cur = head;
while (cur != null) {
if (cur.data == key) {
return true;
}
cur = cur.next;
}
System.out.println("链表不包含该元素");
return false;
}
//头插法
public void addFirst(int data){
ListNode node = new ListNode(data);
// 为空,直接赋值
if (head == null) {
head = last = node;
}else {
node.next = head;
head.prev = node;
head = node;
}
}
//尾插法 最方便的一集 因为本来就有尾结点
public void addLast(int data){
ListNode node = new ListNode(data);
// 为空,直接赋值
if (head == null) {
head = last = node;
}else {
last.next = node;
node.prev = last;
last = node;
}
}
//任意位置插入,第一个数据节点为0号下标
public void addIndex(int index,int data){
if(index<0 || index>size()) {
throw new RuntimeException(index + "位置异常");
}
if (index == 0) {
addFirst(data);
return;
}
if(index == size()){
addLast(data);
return;
}
ListNode cur = searchIndex(index);
ListNode node = new ListNode(data);
// 插入 对于单链表来说需要cur走到Index位置的前一个结点 而双向链表不需要 直接走到index位置的结点即可
// 在index位置的插入都是先绑定后面的
node.next = cur;
cur.prev.next = node;
// 这两行的顺序不能改变
node.prev = cur.prev;
cur.prev = node;
}
private ListNode searchIndex(int index) {
ListNode cur = head;
while (index > 0) {
cur = cur.next;
index--;
}
return cur;
}
/**
* 我写的这个删除的代码将寻找data==Key的这个过程封装成一个方法 思路很好 但是不利于写删除所有的key值的方法
* 因为想要删除所有的key值,不可避免的是要遍历整个链表,而不是得到某一个节点
* @param key
* @return
*/
/* //删除第一次出现关键字为key的节点
public void remove(int key){
// 不能这样写,因为要求的是删除第一次出现的key
// if(last.data == key) {
// last = last.prev;
// last.next = null;
// return;
// }
// 使cur为data为key的结点
ListNode cur = findIndexOf(key);
if (cur == null) {
System.out.println("没有你要删除的结点");
return;
}
if (cur == head) {
head = head.next;
if (head != null) {
head.prev = null;
}else {
// 处理只有一个结点的情况 head直接为空了 此时只需把last也置空即可
last = null;
}
}else {
// 处理中间结点和尾巴结点 尾巴结点要单独处理(后继为null)
if (cur.next != null) {
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
}else {
cur.prev.next = null;
last = cur.prev;
}
}
}
private ListNode findIndexOf(int key) {
ListNode cur = head;
while (cur != null) {
if (cur.data == key) {
return cur;
}
cur = cur.next;
}
return null;
}*/
/**
* 重写remove方法
* @param key
* @return
*/
public void remove(int key) {
ListNode cur = head;
while (cur != null) {
if (cur.data == key) {
// 等于key也要分两种情况
if (cur == head) {
head = head.next;
if (head == null) {
last = null;
}else {
head.prev = null;
}
}else {
// 处理中间结点和尾结点
if (cur.next != null) {
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
}else {
cur.prev.next = null;
last = cur.prev;
}
}
return;
}else {
cur = cur.next;
}
}
}
//删除所有值为key的节点
public void removeAllKey(int key){
ListNode cur = head;
while (cur != null) {
if (cur.data == key) {
// 等于key也要分两种情况
if (cur == head) {
head = head.next;
if (head == null) {
last = null;
}else {
head.prev = null;
}
}else {
// 处理中间结点和尾结点
if (cur.next != null) {
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
}else {
cur.prev.next = null;
last = cur.prev;
}
}
cur = cur.next;
//return;
}else {
cur = cur.next;
}
}
}
public void clear(){
ListNode cur = head;
while (cur != null) {
ListNode curNext = cur.next;
cur.prev = null;
cur.next = null;
cur = cur.next;
}
// 头尾结点要单独置空
head = null;
last = null;
// // 把每一个链表都指控
// ListNode cur = head;
// while (cur != null) {
// cur.prev = null;
// cur = cur.next;
// if (cur != null) {
// cur.prev.next = null;
// }
// }
}
}3.LinkedList的使用
1.构造方法
- LinkedList() 无参构造
- public LinkedList(Collection<? estends E> c) 使用其他集合容器中元素构造List
// 无参的构造方法
public LinkedList() {
}
// 使用其他集合来构建一个链表
public LinkedList(Collection<? extends E> c) {
this();// 调用上面的构造方法
addAll(c);// 将集合c中的所有元素填入到创建的链表中
}2.其他方法
1.add
boolean add(E e) 尾插 e
// This method is equivalent to addLast. 这个方法和addLast是等价的
public boolean add(E e) {
linkLast(e);
return true;
}
// 尾插
void linkLast(E e) {
final LinkedList.Node<E> l = last;// 让l指向最后一个结点
// 创建一个新的结点
final LinkedList.Node<E> newNode = new LinkedList.Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;// 用于记录集合被修改的次数
}void add(int index, E element) 将 e 插入到 index 位置
public void add(int index, E element) {
checkPositionIndex(index);// 检查index是否合法
// 尾插
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
// Inserts element e before non-null Node succ. 在succ之前添加一个非空的结点e
void linkBefore(E e, LinkedList.Node<E> succ) {
// assert succ != null;
// 设置pred为succ的前驱节点
final LinkedList.Node<E> pred = succ.prev;
final LinkedList.Node<E> newNode = new LinkedList.Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}boolean addAll(Collection c) 尾插 c 中的元素
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
// 将集合c转变为数组 并求出他的长度
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
LinkedList.Node<E> pred, succ;
if (index == size) {
// 对list进行尾插集合c
succ = null;
pred = last;
} else {
// 在指定位置的list中进行c集合的插入
succ = node(index);
pred = succ.prev;
}
// 遍历集合 进行插入
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
LinkedList.Node<E> newNode = new LinkedList.Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
// 将新加入的结点和原来的结点连接起来
if (succ == null) {
// 此处处理的是尾插
last = pred;
} else {
// 处理在指定位置的插入
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
2.remove
E remove(int index) 删除 index 位置元素
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
E unlink(LinkedList.Node<E> x) {
// assert x != null;
final E element = x.item;
final LinkedList.Node<E> next = x.next;
final LinkedList.Node<E> prev = x.prev;
// 先处理x.prev
if (prev == null) {
// 要删除的结点为头结点 直接让x的下一个结点作为头结点
first = next;
} else {
// 不是头结点 连接x的下一个节点
prev.next = next;
x.prev = null;
}
// 处理x.next
if (next == null) {
// 要删除的结点是尾结点
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}以下操作都十分简单,读者可自行查阅使用,这里不做过多的介绍
3.get
E get(int index) 获取下标 index 位置元素
4.set
E set(int index, E element) 将下标 index 位置元素设置为 element
5.contains
boolean contains(Object o) 判断 o 是否在线性表中
6.indexOf
int indexOf(Object o) 返回第一个 o 所在下标
7.subList
List subList(int fromIndex, int toIndex) 截取部分 list
3. LinkedList的遍历
LinkedList的遍历的遍历一般有两种遍历方式
- 迭代器
- for each循环
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<>();
list.add(1); // add(elem): 表示尾插
list.add(2);
list.add(3);
list.add(4);
list.add(5);
list.add(6);
list.add(7);
// for each循环遍历
for (Integer i : list) {
System.out.print(i + " ");
}
// 迭代器
Iterator iterator = list.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}五. ArrayList和LinkedList的区别
- 存储空间:ArrayList物理地址连续 LinkedList物理地址不连续
- 随机访问(RandomAccess接口):ArrayList支持随机访问 LinkedList不支持
- 头插:ArrayList需要挪动数据 LinkedList不需要挪动数据
- 扩容:ArrayList空间不够需要使用grow进行1.5倍扩容 LinkedList没有容量的概念
- 应用场景:ArrayList频繁的查询 LinkedList频繁的进行数据的删除/插入

















 376
376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









