






 本文探讨了信息熵的概念及其衡量标准,详细介绍了信息熵如何反映信息的不确定性,并通过实例展示了信息熵在文本处理和指标权重计算中的应用。此外,还讨论了利用信息熵判断新词出现的可能性。
本文探讨了信息熵的概念及其衡量标准,详细介绍了信息熵如何反映信息的不确定性,并通过实例展示了信息熵在文本处理和指标权重计算中的应用。此外,还讨论了利用信息熵判断新词出现的可能性。
目录
1.一条信息中信息量的大小取决于什么?
即:信息消除了多少不确定性!

A中信息的不确定性就高于B中信息的不确定性。
信息熵是不确定性的标志,如果一个随机变量的信息熵越大,其不确定性也越高。
定义x是离散随机变量,其概率密度函数为p(x),它的信息熵(entropy)定义为
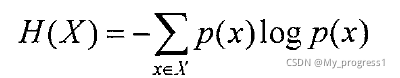
B在的信息熵=
“我很爱武汉”的信息熵=
“我很爱爱爱武汉”的信息熵=
上面两句中,表达了相同的意思,但是第一句话篇幅少,信息熵高。
法语:3.98bit 西班牙语:4.01bit 英语:4.03bit
俄语:4.35bit 中文:9.6bit
也就是说,在表达相同的意思下,中文所需的篇幅最少,法语所需的篇幅最多。
同时,若一条信息的含义越难预判,则信息熵则越高。
另外一点,假定X和Y是两个离散随机变量,其联合分布为P(x,y),边缘分布分别为P(X)与P(Y),其联合熵为
随机变量X与Y的互信息公式为
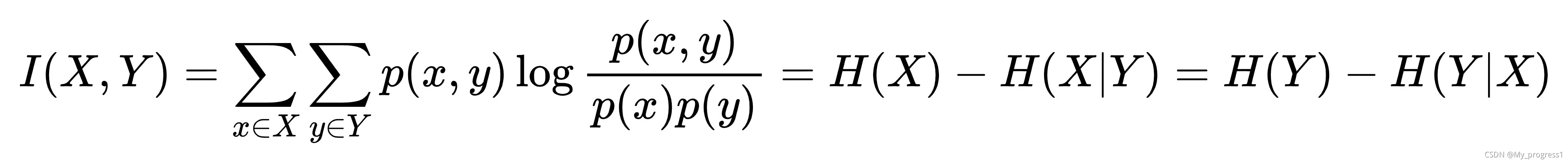
若X,Y相互独立,则:
若X,Y相关性较高,则越大于零。
2.信息论的应用
2.1文本处理中对于新词的出现
例如:"机器学习是一个交叉领域学科,涉及信息处理、统计学、计算机科学等多个学科。"
经过分词后,“机器”与“学习”会被分开。
取统计词频的方法计算分词后中每个词的概率。若两个相邻词的互信息I(X,Y)大于给定的阈值,认为是新词出现。即“机器学习”这个词会出现。
当然,我们这里只是一个句子,在文本处理的过程中,我们面对的可能是一篇文章。
2.2计算指标权重
这篇文章中对于熵权法的应用解释的非常清楚,也有例子。
指标权重确定方法之熵权法_moon的博客-优快云博客_熵权法求权重
3.自己的理解
对于新词的出现,是否可以使用Jaccard Index,其公式为
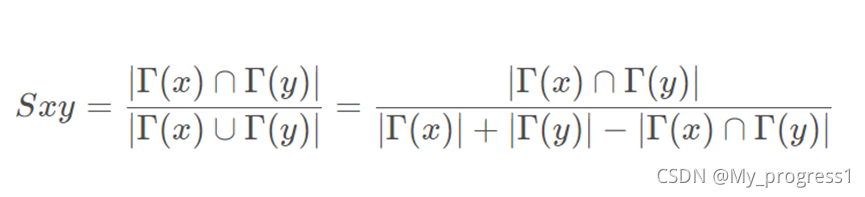
注意,我们是剔除“的”、“了”、“是”、“我”等高频使用字词?
设置阈值,两次词有连接的,设置为1;没有连接的,设置为0。
这个的区别就是是否取logx函数
3.1问题
1.公式中log的底是多少,是e还是2,还是10?
2.用log处理的好处是什么?
3.信息熵还可以运用到什么地方?
4.参考文献
科学证明中文就是最最最高级的!【硬核科普】信息熵是什么_哔哩哔哩_bilibili
信息熵极低的文字会是什么样子?信息熵极高的文字又是什么样子? - 知乎
许峰. 基于深度学习的网络舆情识别研究[D].北京邮电大学,2019.

















 5万+
5万+




 到【灌水乐园】发言
到【灌水乐园】发言







